FocalCodec: Low-Bitrate Speech Coding via Focal Modulation Networks
作者: Luca Della Libera, Francesco Paissan, Cem Subakan, Mirco Ravanelli
分类: cs.LG, cs.AI, cs.SD, eess.AS
发布日期: 2025-02-06 (更新: 2025-10-24)
备注: Accepted at NeurIPS 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
FocalCodec:基于焦点调制网络的低比特率语音编码
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音编码 低比特率 焦点调制网络 神经音频编解码器 语音重合成 语音转换 二元量化
📋 核心要点
- 现有神经音频编解码器存在高比特率、信息损失以及多码本设计导致的复杂性问题。
- FocalCodec利用焦点调制网络和单个二元码本,实现了低比特率的语音压缩。
- 实验表明,FocalCodec在低比特率下实现了有竞争力的语音重合成和语音转换性能,并能有效处理多语言和噪声环境。
📝 摘要(中文)
大型语言模型通过在海量数据集上的自监督预训练彻底改变了自然语言处理。受此成功的启发,研究人员探索了将这些方法应用于语音,通过使用神经音频编解码器将连续音频离散化为token。然而,现有方法面临诸多限制,包括高比特率、语义或声学信息的丢失,以及在试图同时捕获两者时依赖多码本设计,这增加了下游任务的架构复杂性。为了解决这些挑战,我们引入了FocalCodec,这是一种基于焦点调制的高效低比特率编解码器,它利用单个二元码本以0.16到0.65 kbps之间的速率压缩语音。FocalCodec在语音重合成和语音转换方面提供了比当前最先进技术更低的比特率,同时有效地处理了多语言语音和噪声环境。在下游任务上的评估表明,FocalCodec成功地保留了足够的语义和声学信息,同时也非常适合生成建模。演示样本和代码可在https://lucadellalib.github.io/focalcodec-web/上找到。
🔬 方法详解
问题定义:现有神经音频编解码器为了将连续语音转换为离散token,以便利用大型语言模型,通常面临高比特率的挑战。同时,为了兼顾语义和声学信息的保留,一些方法采用多码本设计,增加了模型复杂性,不利于下游任务的应用。因此,如何在低比特率下有效压缩语音,同时保留足够的语义和声学信息,是一个亟待解决的问题。
核心思路:FocalCodec的核心思路是利用焦点调制网络(Focal Modulation Networks)来学习语音的潜在表示,并使用单个二元码本对这些表示进行量化。焦点调制能够有效地捕捉语音中的长程依赖关系,从而更好地保留语义信息。使用单个二元码本简化了模型结构,降低了比特率。
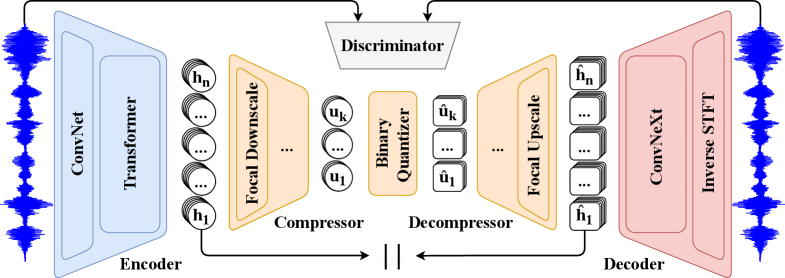
技术框架:FocalCodec的整体框架包含以下几个主要模块:1) 编码器:将输入语音转换为潜在表示;2) 量化器:使用二元码本对潜在表示进行量化;3) 解码器:将量化后的表示重构为语音。编码器和解码器基于焦点调制网络构建,量化器则使用简单的二元量化。整个流程旨在实现低比特率的语音压缩和高质量的语音重构。
关键创新:FocalCodec的关键创新在于将焦点调制网络应用于语音编码,并结合单个二元码本实现了低比特率的语音压缩。与现有方法相比,FocalCodec在保证语音质量的同时,显著降低了比特率,并简化了模型结构。焦点调制网络能够更好地捕捉语音中的长程依赖关系,从而更好地保留语义信息,这是传统方法难以实现的。
关键设计:FocalCodec的关键设计包括:1) 焦点调制网络的具体结构,包括层数、通道数等;2) 二元码本的大小和训练方法;3) 损失函数的设计,包括重构损失和对抗损失等,以保证重构语音的质量和自然度;4) 训练数据的选择和预处理方法,以提高模型的泛化能力。
🖼️ 关键图片

📊 实验亮点
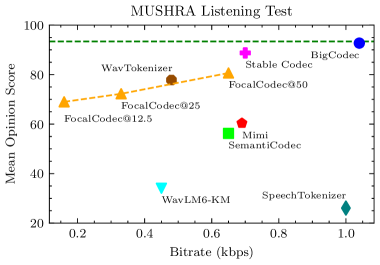
FocalCodec在语音重合成和语音转换任务上取得了显著的成果。在低至0.16 kbps的比特率下,FocalCodec仍然能够生成可理解的语音。与现有的最先进方法相比,FocalCodec在更低的比特率下实现了更优的语音质量。此外,FocalCodec还能够有效地处理多语言语音和噪声环境,表明其具有良好的鲁棒性和泛化能力。实验结果表明,FocalCodec成功地保留了足够的语义和声学信息,使其非常适合生成建模。
🎯 应用场景
FocalCodec具有广泛的应用前景,包括低带宽语音通信、语音存储、语音合成和语音转换等。其低比特率特性使其非常适合在带宽受限的环境中使用,例如移动通信和物联网设备。此外,FocalCodec还可以用于语音数据的压缩存储,降低存储成本。在语音合成和语音转换方面,FocalCodec可以作为一种有效的特征提取器,为生成高质量的语音提供支持。未来,FocalCodec有望在智能语音助手、语音游戏等领域发挥重要作用。
📄 摘要(原文)
Large language models have revolutionized natural language processing through self-supervised pretraining on massive datasets. Inspired by this success, researchers have explored adapting these methods to speech by discretizing continuous audio into tokens using neural audio codecs. However, existing approaches face limitations, including high bitrates, the loss of either semantic or acoustic information, and the reliance on multi-codebook designs when trying to capture both, which increases architectural complexity for downstream tasks. To address these challenges, we introduce FocalCodec, an efficient low-bitrate codec based on focal modulation that utilizes a single binary codebook to compress speech between 0.16 and 0.65 kbps. FocalCodec delivers competitive performance in speech resynthesis and voice conversion at lower bitrates than the current state-of-the-art, while effectively handling multilingual speech and noisy environments. Evaluation on downstream tasks shows that FocalCodec successfully preserves sufficient semantic and acoustic information, while also being well-suited for generative modeling. Demo samples and code are available at https://lucadellalib.github.io/focalcodec-web/.