Training Language Models to Reason Efficiently
作者: Daman Arora, Andrea Zanette
分类: cs.LG, cs.CL
发布日期: 2025-02-06 (更新: 2025-11-03)
备注: NeurIPS 2025
💡 一句话要点
提出基于强化学习的推理效率优化方法,降低大语言模型推理成本。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理效率 强化学习 计算资源分配 动态推理
📋 核心要点
- 现有大语言模型推理成本高昂,尤其是在复杂推理任务中,长链式思考导致计算开销巨大。
- 利用强化学习训练模型,使其能够根据任务复杂度动态分配计算资源,避免不必要的计算开销。
- 实验表明,该方法能在保持准确率的同时,显著降低推理成本,并可通过超参数控制效率水平。
📝 摘要(中文)
大型语言模型(LLM)通过扩展模型规模和训练数据取得了显著进展。然而,这种方法的收益递减促使人们寻找替代方法来提升模型能力,尤其是在需要高级推理的任务中。大型推理模型利用长链式思维在解决问题能力上取得了前所未有的突破,但同时也带来了与更长生成相关的巨大部署成本。降低推理成本对于这些模型的经济可行性、用户体验和环境可持续性至关重要。本文提出训练大型推理模型以实现高效推理。更准确地说,我们使用强化学习(RL)来训练推理模型,使其能够基于任务复杂性动态地分配推理时计算资源。我们的方法激励模型在保持准确性的同时,最大限度地减少不必要的计算开销,从而实现显著的效率提升。它能够推导出一系列具有不同效率水平的推理模型,并通过单个超参数进行控制。在两个开源大型推理模型上的实验表明,在保持大部分准确性的同时,推理成本显著降低。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在推理过程中计算效率低下的问题。现有方法,如简单地扩展模型尺寸和训练数据,虽然能提高性能,但收益递减,且推理成本随之增加,尤其是在需要复杂推理的任务中,长链式思考进一步加剧了这一问题。因此,如何在保证推理准确性的前提下,降低计算成本,是本文要解决的核心问题。
核心思路:论文的核心思路是让模型学会“聪明地”推理,即根据任务的复杂程度动态地调整计算资源的分配。对于简单的任务,模型可以快速给出答案,而对于复杂的任务,则可以分配更多的计算资源进行深入思考。这种动态调整避免了对所有任务都采用相同的、高成本的推理策略,从而提高了整体的计算效率。
技术框架:整体框架是基于强化学习的训练过程。首先,使用一个大型推理模型作为基础模型。然后,定义一个奖励函数,该函数同时考虑模型的准确性和计算成本。接下来,使用强化学习算法(具体算法未知)训练模型,使其能够根据输入任务的复杂程度,动态地调整推理过程中的计算资源分配。训练后的模型可以根据一个超参数来控制效率水平,从而得到一系列具有不同效率水平的推理模型。
关键创新:该方法的核心创新在于将强化学习应用于推理过程中的计算资源分配。与传统的静态计算资源分配方法不同,该方法能够根据任务的复杂程度动态地调整计算资源,从而在保证准确性的前提下,显著降低计算成本。这种动态调整的思想是该方法的核心创新点。
关键设计:具体的技术细节未知,但可以推测一些关键设计。奖励函数的设计至关重要,需要在准确性和计算成本之间进行权衡。强化学习算法的选择也会影响训练效果。此外,如何有效地表示任务的复杂程度,以及如何将复杂程度映射到计算资源分配策略,也是需要仔细考虑的关键设计。
🖼️ 关键图片
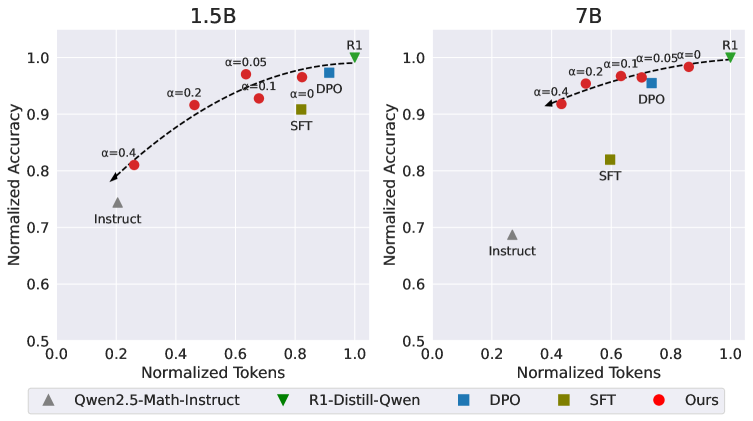
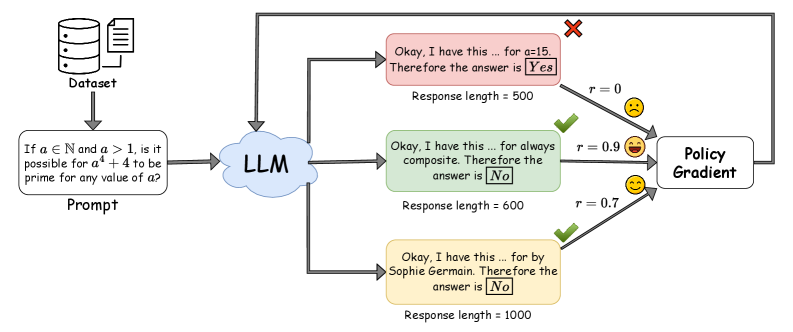
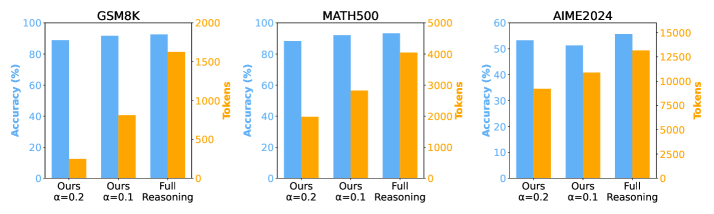
📊 实验亮点
论文在两个开源的大型推理模型上进行了实验,结果表明,该方法能够在保持大部分准确性的前提下,显著降低推理成本。具体的性能数据和提升幅度在摘要中未给出,但强调了效率的显著提升,并可以通过单个超参数控制效率水平,为实际应用提供了灵活性。
🎯 应用场景
该研究成果可广泛应用于各种需要大语言模型进行推理的场景,例如问答系统、对话机器人、代码生成等。通过降低推理成本,可以使这些应用更具经济可行性,并提高用户体验。此外,该方法还有助于降低大语言模型的能源消耗,从而促进人工智能的可持续发展。
📄 摘要(原文)
Scaling model size and training data has led to great advances in the performance of Large Language Models (LLMs). However, the diminishing returns of this approach necessitate alternative methods to improve model capabilities, particularly in tasks requiring advanced reasoning. Large reasoning models, which leverage long chain-of-thoughts, bring unprecedented breakthroughs in problem-solving capabilities but at a substantial deployment cost associated to longer generations. Reducing inference costs is crucial for the economic feasibility, user experience, and environmental sustainability of these models. In this work, we propose to train large reasoning models to reason efficiently. More precisely, we use reinforcement learning (RL) to train reasoning models to dynamically allocate inference-time compute based on task complexity. Our method incentivizes models to minimize unnecessary computational overhead while maintaining accuracy, thereby achieving substantial efficiency gains. It enables the derivation of a family of reasoning models with varying efficiency levels, controlled via a single hyperparameter. Experiments on two open-weight large reasoning models demonstrate significant reductions in inference cost while preserving most of the accuracy.