KVTuner: Sensitivity-Aware Layer-Wise Mixed-Precision KV Cache Quantization for Efficient and Nearly Lossless LLM Inference
作者: Xing Li, Zeyu Xing, Yiming Li, Linping Qu, Hui-Ling Zhen, Wulong Liu, Yiwu Yao, Sinno Jialin Pan, Mingxuan Yuan
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-02-06 (更新: 2025-11-20)
备注: Accepted by ICML25. Code: https://github.com/cmd2001/KVTuner
🔗 代码/项目: GITHUB
💡 一句话要点
KVTuner:一种敏感度感知的层级混合精度KV缓存量化方法,用于高效且近乎无损的LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存量化 混合精度量化 大型语言模型 推理加速 层级敏感度 注意力机制 模型优化
📋 核心要点
- 现有KV缓存量化方法忽略了不同Transformer层对量化误差的敏感性差异,导致量化策略并非最优。
- KVTuner框架通过分析层级注意力模式与量化误差的相关性,自适应搜索最优的层级混合精度KV量化配置。
- 实验表明,KVTuner能为多种LLM实现近乎无损的低比特量化,并显著提升推理吞吐量,最高可达21.25%。
📝 摘要(中文)
KV缓存量化可以在长上下文和大批量大小场景中提高大型语言模型(LLM)的推理吞吐量和延迟,同时保持LLM的有效性。然而,当前的方法存在三个未解决的问题:忽略了层级对KV缓存量化的敏感性,在线细粒度决策的高开销,以及对不同LLM和约束的低灵活性。因此,我们从理论上分析了层级Transformer注意力模式与KV缓存量化误差的内在相关性,并研究了为什么Key缓存通常比Value缓存对于减少量化误差更重要。我们进一步提出了一个简单而有效的框架KVTuner,以自适应地搜索硬件友好的层级KV量化精度对,用于粗粒度的KV缓存,并通过多目标优化,在在线推理期间直接利用离线搜索的配置。为了降低离线校准的计算成本,我们利用层内KV精度对剪枝和层间聚类来减少搜索空间。实验结果表明,对于像Llama-3.1-8B-Instruct这样的LLM,我们可以实现近乎无损的3.25位混合精度KV缓存量化,而对于像Qwen2.5-7B-Instruct这样的敏感模型,在数学推理任务上可以实现4.0位。与KIVI-KV8量化相比,在各种上下文长度下,最大推理吞吐量可以提高21.25%。我们的代码和搜索的配置可在https://github.com/cmd2001/KVTuner获得。
🔬 方法详解
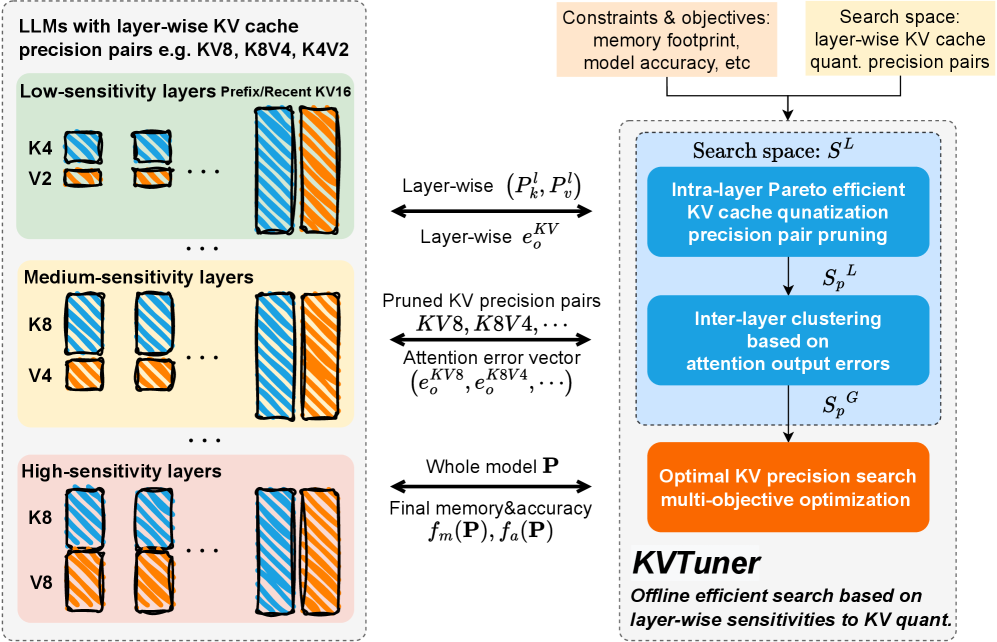
问题定义:论文旨在解决大型语言模型(LLM)推理过程中KV缓存量化的问题。现有方法忽略了不同Transformer层对KV缓存量化的敏感度差异,采用统一的量化策略,导致量化误差较大,性能提升有限。此外,在线细粒度决策开销高,且缺乏对不同LLM和硬件约束的适应性。
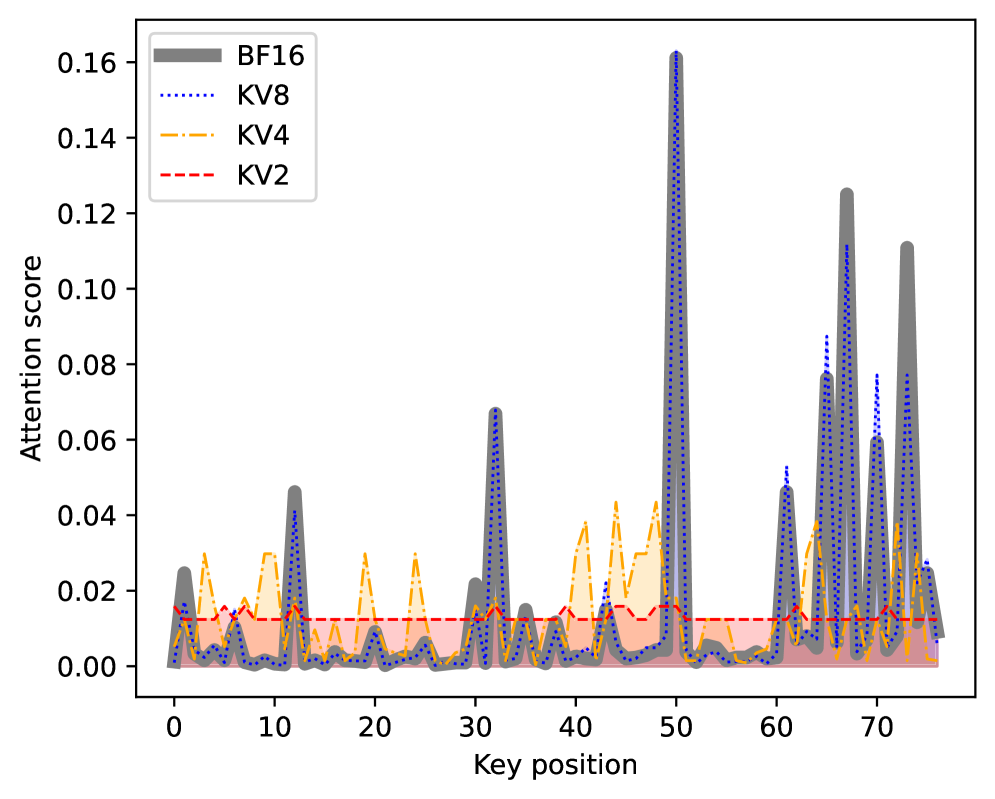
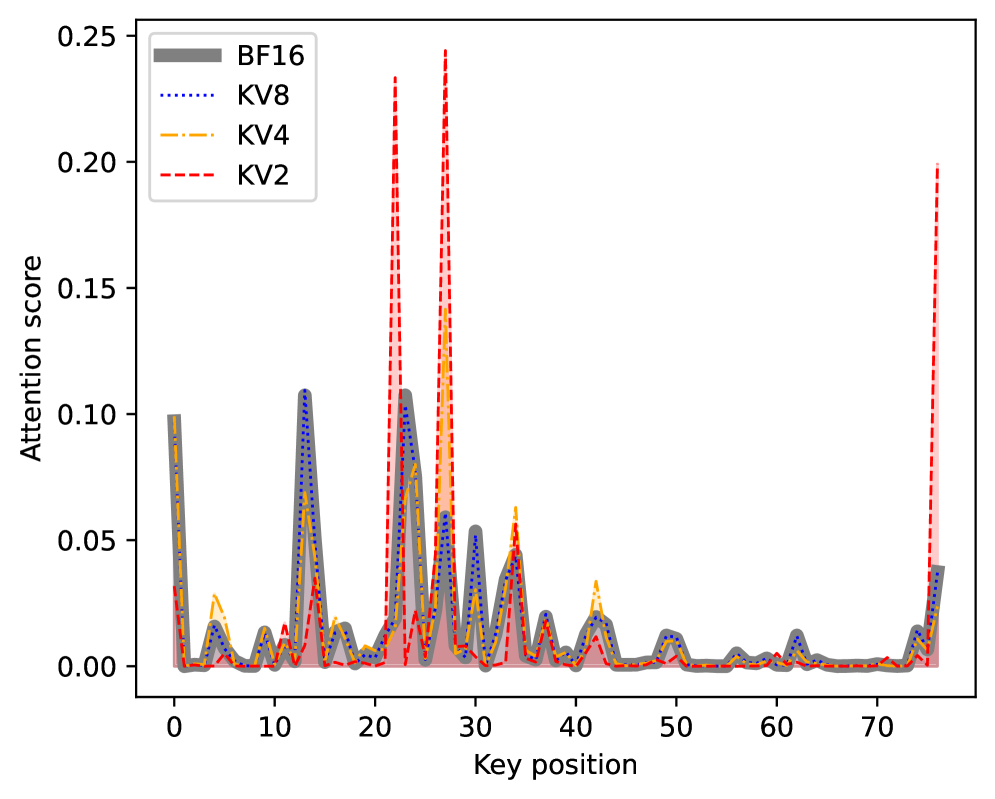
核心思路:论文的核心思路是利用层级Transformer注意力模式与KV缓存量化误差的内在相关性,对不同层采用不同的量化精度。通过离线搜索最优的层级混合精度KV量化配置,并在在线推理时直接应用,从而在保证模型性能的同时,提升推理效率。Key缓存通常比Value缓存对于减少量化误差更重要。
技术框架:KVTuner框架包含离线校准和在线推理两个阶段。离线校准阶段,首先分析层级注意力模式,然后通过多目标优化搜索最优的层级KV量化精度对。为了降低搜索空间,采用层内KV精度对剪枝和层间聚类。在线推理阶段,直接利用离线搜索的配置进行KV缓存量化。
关键创新:论文的关键创新在于提出了敏感度感知的层级混合精度KV缓存量化方法。通过理论分析和实验验证,揭示了层级注意力模式与KV缓存量化误差的相关性,并据此设计了自适应的量化策略。此外,采用离线搜索和在线应用的方式,降低了在线推理的计算开销。
关键设计:KVTuner的关键设计包括:1) 基于注意力模式的层级敏感度分析;2) 硬件友好的量化精度选择;3) 多目标优化搜索策略,平衡模型性能和量化比特数;4) 层内KV精度对剪枝和层间聚类,降低搜索空间。
🖼️ 关键图片
📊 实验亮点
实验结果表明,KVTuner在Llama-3.1-8B-Instruct模型上实现了近乎无损的3.25位混合精度KV缓存量化,在Qwen2.5-7B-Instruct模型上实现了4.0位量化。与KIVI-KV8量化相比,在各种上下文长度下,最大推理吞吐量可以提高21.25%。这些结果表明KVTuner在提升LLM推理效率方面具有显著优势。
🎯 应用场景
KVTuner可应用于各种需要高效LLM推理的场景,如移动设备上的本地推理、边缘计算、以及对延迟敏感的云服务。通过降低KV缓存的存储需求和计算复杂度,KVTuner能够显著提升LLM在资源受限环境下的部署能力,并降低推理成本,加速LLM的普及。
📄 摘要(原文)
KV cache quantization can improve Large Language Models (LLMs) inference throughput and latency in long contexts and large batch-size scenarios while preserving LLMs effectiveness. However, current methods have three unsolved issues: overlooking layer-wise sensitivity to KV cache quantization, high overhead of online fine-grained decision-making, and low flexibility to different LLMs and constraints. Therefore, we theoretically analyze the inherent correlation of layer-wise transformer attention patterns to KV cache quantization errors and study why key cache is generally more important than value cache for quantization error reduction. We further propose a simple yet effective framework KVTuner to adaptively search for the optimal hardware-friendly layer-wise KV quantization precision pairs for coarse-grained KV cache with multi-objective optimization and directly utilize the offline searched configurations during online inference. To reduce the computational cost of offline calibration, we utilize the intra-layer KV precision pair pruning and inter-layer clustering to reduce the search space. Experimental results show that we can achieve nearly lossless 3.25-bit mixed precision KV cache quantization for LLMs like Llama-3.1-8B-Instruct and 4.0-bit for sensitive models like Qwen2.5-7B-Instruct on mathematical reasoning tasks. The maximum inference throughput can be improved by 21.25\% compared with KIVI-KV8 quantization over various context lengths. Our code and searched configurations are available at https://github.com/cmd2001/KVTuner.