Short-length Adversarial Training Helps LLMs Defend Long-length Jailbreak Attacks: Theoretical and Empirical Evidence
作者: Shaopeng Fu, Liang Ding, Jingfeng Zhang, Di Wang
分类: cs.LG, cs.CR, stat.ML
发布日期: 2025-02-06 (更新: 2025-06-07)
🔗 代码/项目: GITHUB
💡 一句话要点
短长度对抗训练提升LLM对长长度越狱攻击的防御能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对抗训练 大型语言模型 越狱攻击 鲁棒性 安全性
📋 核心要点
- 现有的对抗训练方法在处理长长度越狱攻击时,资源消耗较大,限制了其应用。
- 本文提出通过短长度对抗训练来有效防御长长度越狱攻击,降低了训练资源的需求。
- 实验结果显示,短长度对抗训练与长长度越狱攻击之间存在正相关性,验证了方法的有效性。
📝 摘要(中文)
针对大型语言模型(LLMs)的越狱攻击旨在通过精心设计的对抗提示诱导模型产生有害行为。为减轻此类攻击,本文提出通过对抗训练(AT)进行对齐,即在一些最具对抗性的提示上训练LLMs,以帮助其学习在攻击下安全行为。研究发现,防御长度为Θ(M)的越狱攻击,仅需在长度为Θ(√M)的对抗提示上进行对齐。理论分析表明,线性变换器在线性回归任务中的对抗上下文学习具有稳健的泛化界限。实验证实了对抗提示长度与攻击成功率之间的正相关性,表明通过高效的短长度AT可以有效防御长长度越狱攻击。
🔬 方法详解
问题定义:本文解决的是大型语言模型在面对越狱攻击时的防御能力不足问题。现有方法在使用长长度对抗提示进行训练时,资源消耗高,限制了其实际应用。
核心思路:论文提出的核心思路是,通过在较短的对抗提示上进行训练,来提升模型对长长度越狱攻击的防御能力。这种方法不仅降低了训练成本,还保持了模型的鲁棒性。
技术框架:整体架构包括对抗训练阶段和评估阶段。在对抗训练阶段,模型在短长度对抗提示上进行训练;在评估阶段,模型的防御能力通过长长度越狱攻击进行测试。
关键创新:最重要的技术创新在于发现了短长度对抗训练可以有效防御长长度越狱攻击的现象。这一发现与传统方法的依赖长长度对抗提示的思路形成鲜明对比。
关键设计:在训练过程中,设置了对抗提示的长度为Θ(√M),并通过线性变换器进行对抗上下文学习,确保模型能够在训练和测试中保持良好的泛化能力。
🖼️ 关键图片
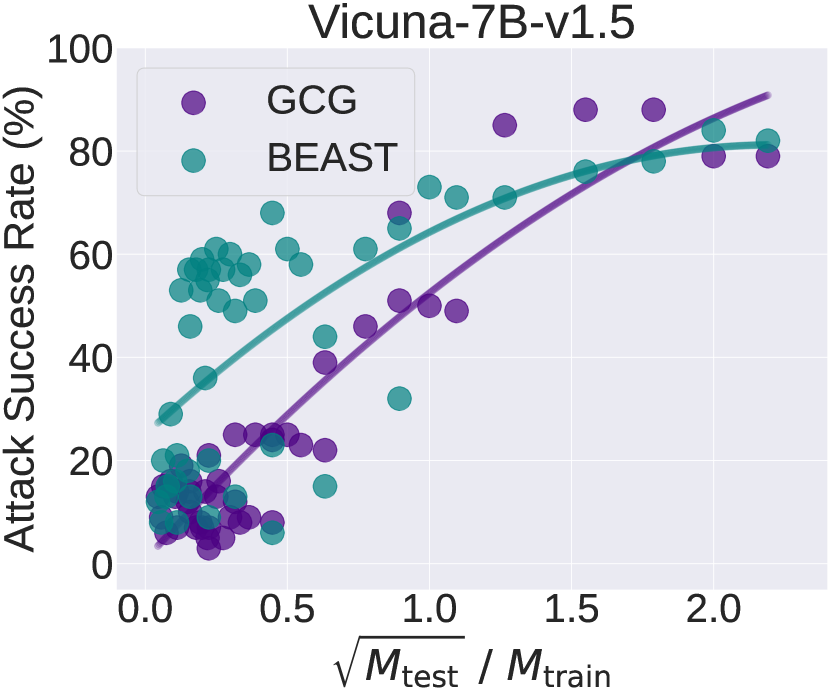
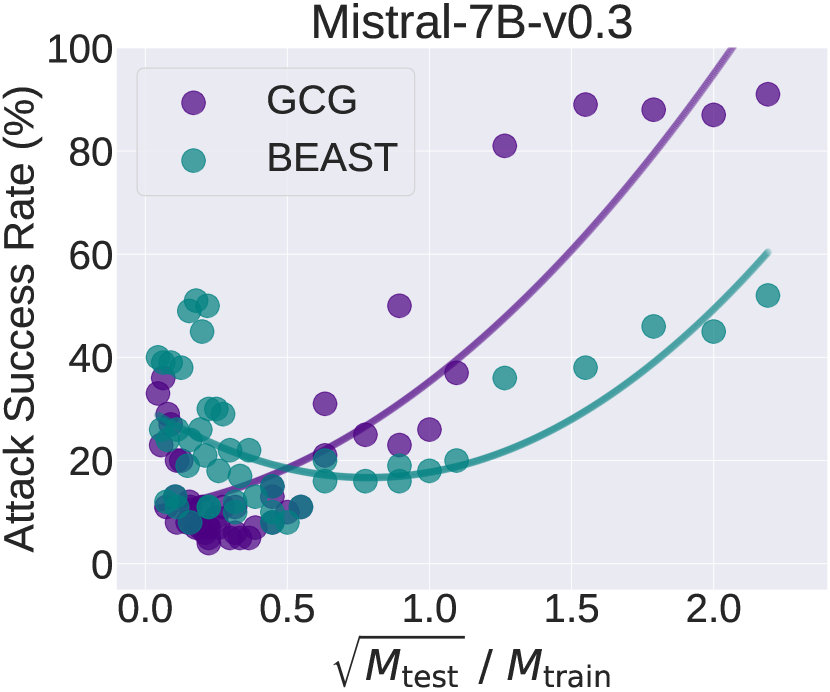
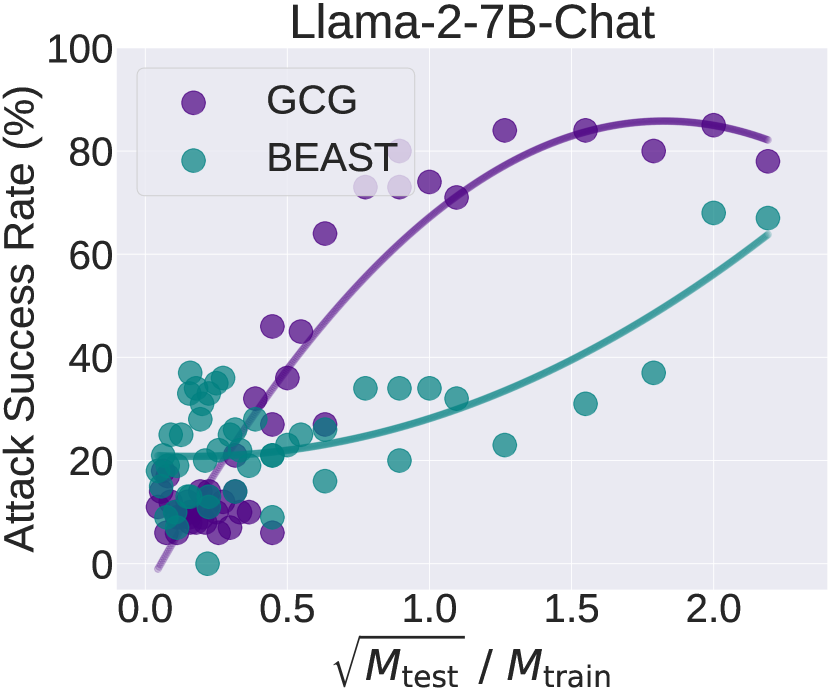
📊 实验亮点
实验结果表明,短长度对抗训练与长长度越狱攻击的成功率之间存在正相关性。具体而言,攻击成功率与对抗提示长度的平方根与训练长度的比率呈现出显著的正相关,验证了短长度训练的有效性。
🎯 应用场景
该研究的潜在应用领域包括安全性要求高的对话系统、内容生成模型以及其他需要防止恶意输入的人工智能应用。通过提高模型的防御能力,可以有效降低潜在的安全风险,提升用户信任度。
📄 摘要(原文)
Jailbreak attacks against large language models (LLMs) aim to induce harmful behaviors in LLMs through carefully crafted adversarial prompts. To mitigate attacks, one way is to perform adversarial training (AT)-based alignment, i.e., training LLMs on some of the most adversarial prompts to help them learn how to behave safely under attacks. During AT, the length of adversarial prompts plays a critical role in the robustness of aligned LLMs. While long-length adversarial prompts during AT might lead to strong LLM robustness, their synthesis however is very resource-consuming, which may limit the application of LLM AT. This paper focuses on adversarial suffix jailbreak attacks and unveils that to defend against a jailbreak attack with an adversarial suffix of length $Θ(M)$, it is enough to align LLMs on prompts with adversarial suffixes of length $Θ(\sqrt{M})$. Theoretically, we analyze the adversarial in-context learning of linear transformers on linear regression tasks and prove a robust generalization bound for trained transformers. The bound depends on the term $Θ(\sqrt{M_{\text{test}}}/M_{\text{train}})$, where $M_{\text{train}}$ and $M_{\text{test}}$ are the numbers of adversarially perturbed in-context samples during training and testing. Empirically, we conduct AT on popular open-source LLMs and evaluate their robustness against jailbreak attacks of different adversarial suffix lengths. Results confirm a positive correlation between the attack success rate and the ratio of the square root of the adversarial suffix length during jailbreaking to the length during AT. Our findings show that it is practical to defend against
long-length'' jailbreak attacks via efficientshort-length'' AT. The code is available at https://github.com/fshp971/adv-icl.