CleanSurvival: Automated data preprocessing for time-to-event models using reinforcement learning
作者: Yousef Koka, David Selby, Gerrit Großmann, Sebastian Vollmer, Kathan Pandya
分类: cs.LG
发布日期: 2025-02-06 (更新: 2026-01-14)
🔗 代码/项目: GITHUB
💡 一句话要点
CleanSurvival:利用强化学习自动进行生存分析数据预处理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 生存分析 数据预处理 强化学习 Q学习 自动化机器学习
📋 核心要点
- 生存分析的数据预处理缺乏自动化和定制化方案,严重影响模型性能。
- CleanSurvival利用强化学习自动选择最优的数据预处理流程,针对生存分析任务定制。
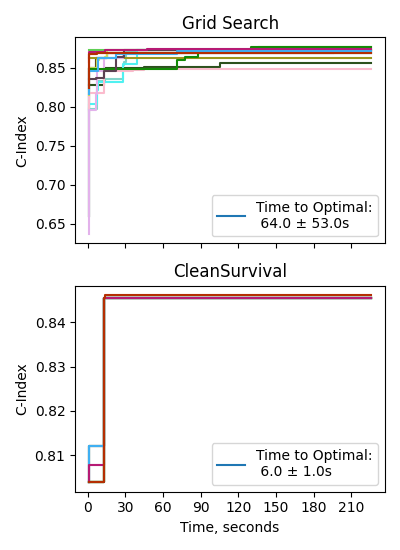
- 实验表明,CleanSurvival优于标准方法,且比随机网格搜索更快,并在不同数据条件下有效。
📝 摘要(中文)
数据预处理是机器学习中至关重要但常被忽视的环节,其对模型性能有显著影响。虽然自动化机器学习流程已开始将数据预处理整合到分类和回归任务中,但对于生存分析等更专业的任务,这种整合仍然不足。生存分析不仅面临一般的数据预处理挑战,还缺乏定制化的自动化解决方案。为解决这一问题,本文提出了'CleanSurvival',一种基于强化学习的解决方案,用于优化专门为生存分析设计的数据预处理流程。该框架可以处理连续和分类变量,使用Q学习选择数据插补、异常值检测和特征提取技术的最佳组合,以优化Cox模型、随机森林、神经网络或用户提供的生存时间模型的性能。实验基准测试表明,基于Q学习的数据预处理比标准方法具有更优越的预测性能,并且找到此类模型比无向随机网格搜索快10倍。此外,仿真研究证明了其在不同类型和缺失程度以及数据噪声下的有效性。
🔬 方法详解
问题定义:论文旨在解决生存分析中数据预处理自动化程度低的问题。现有方法,如手动预处理或通用的自动化机器学习流程,无法针对生存分析的特点进行优化,导致模型性能受限。此外,手动调整预处理流程耗时且依赖专家经验。
核心思路:论文的核心思路是将数据预处理过程建模为一个强化学习问题。通过定义状态、动作和奖励函数,利用Q学习算法训练一个智能体,使其能够自动选择最优的数据预处理步骤,从而最大化生存分析模型的预测性能。这种方法能够自适应地处理不同数据集的特点,并避免手动调整的繁琐。
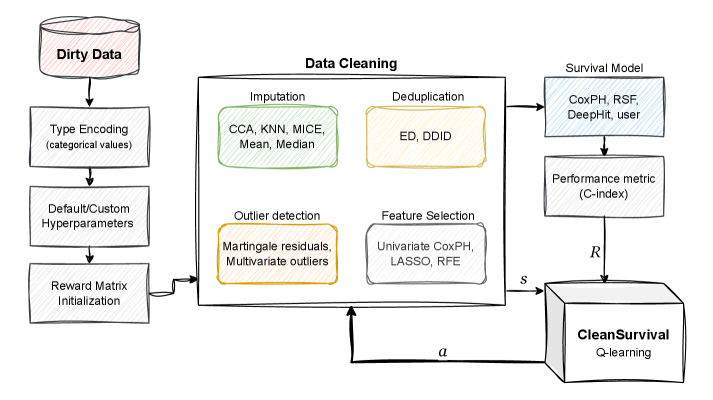
技术框架:CleanSurvival框架包含以下主要模块:1) 环境(Environment):代表待处理的数据集,以及当前的数据预处理状态。2) 智能体(Agent):使用Q学习算法,根据当前状态选择一个数据预处理动作。3) 动作空间(Action Space):包含一系列数据预处理操作,如数据插补、异常值检测和特征提取等。4) 奖励函数(Reward Function):根据生存分析模型的性能(如C-index)来评估当前预处理流程的效果,并给予智能体相应的奖励。5) 生存分析模型(Survival Analysis Model):可以是Cox比例风险模型、随机森林、神经网络或用户自定义的模型。框架通过迭代地执行动作、评估奖励和更新Q值,最终找到最优的数据预处理流程。
关键创新:该论文的关键创新在于将强化学习应用于生存分析的数据预处理。与传统的自动化机器学习流程相比,CleanSurvival能够针对生存分析的特点进行优化,并自动选择最优的预处理步骤。此外,该框架具有很强的灵活性,可以支持不同的生存分析模型和数据预处理操作。
关键设计:Q学习算法是CleanSurvival的核心。状态空间由数据集的统计特征(如缺失值比例、数据分布等)定义。动作空间包含一系列预处理操作,每个操作都有不同的参数设置。奖励函数基于生存分析模型的C-index,用于评估预处理流程的效果。为了加速训练过程,论文可能采用了经验回放等技术。具体的Q学习参数(如学习率、折扣因子等)需要根据具体数据集进行调整。
🖼️ 关键图片
📊 实验亮点
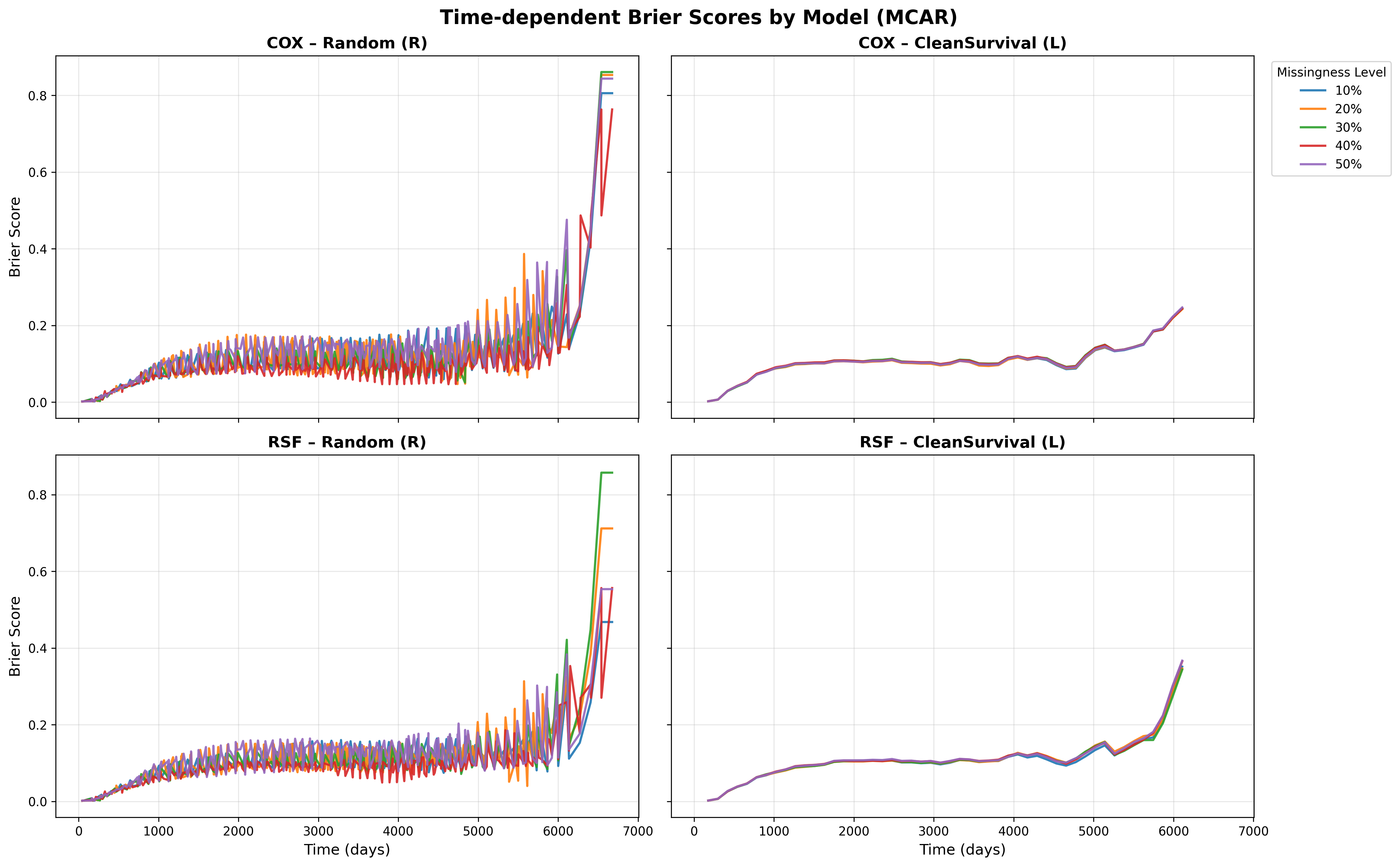
实验结果表明,CleanSurvival在真实数据集上优于标准的数据预处理方法,并且比随机网格搜索快10倍。仿真研究也证明了其在不同类型和缺失程度以及数据噪声下的有效性。这些结果表明,CleanSurvival是一种有效且高效的生存分析数据预处理方法。
🎯 应用场景
CleanSurvival可应用于医疗健康、金融风控、工业设备维护等领域,在这些领域中,生存分析被广泛用于预测事件发生的时间。该研究可以提高生存分析模型的预测精度和效率,帮助决策者更好地理解风险,制定更有效的策略。例如,在医疗领域,可以用于预测患者的生存时间,从而制定更个性化的治疗方案。
📄 摘要(原文)
Data preprocessing is a critical yet frequently neglected aspect of machine learning, often paid little attention despite its potentially significant impact on model performance. While automated machine learning pipelines are starting to recognize and integrate data preprocessing into their solutions for classification and regression tasks, this integration is lacking for more specialized tasks like survival or time-to-event models. As a result, survival analysis not only faces the general challenges of data preprocessing but also suffers from the lack of tailored, automated solutions in this area. To address this gap, this paper presents 'CleanSurvival', a reinforcement-learning-based solution for optimizing preprocessing pipelines, extended specifically for survival analysis. The framework can handle continuous and categorical variables, using Q-learning to select which combination of data imputation, outlier detection and feature extraction techniques achieves optimal performance for a Cox, random forest, neural network or user-supplied time-to-event model. The package is available on GitHub: https://github.com/datasciapps/CleanSurvival Experimental benchmarks on real-world datasets show that the Q-learning-based data preprocessing results in superior predictive performance to standard approaches, finding such a model up to 10 times faster than undirected random grid search. Furthermore, a simulation study demonstrates the effectiveness in different types and levels of missingness and noise in the data.