Self-Improving Skill Learning for Robust Skill-based Meta-Reinforcement Learning
作者: Sanghyeon Lee, Sangjun Bae, Yisak Park, Seungyul Han
分类: cs.LG, cs.AI
发布日期: 2025-02-06 (更新: 2025-10-09)
备注: 9 pages main, 25 pages appendix with reference. Submitted to ICLR 2026
💡 一句话要点
提出自提升技能学习(SISL),解决技能型元强化学习在噪声离线数据下的不稳定问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 元强化学习 技能学习 离线强化学习 分层强化学习 机器人控制
📋 核心要点
- 技能型元强化学习在长时程任务中易受噪声离线数据影响,导致技能学习不稳定和性能下降。
- 论文提出自提升技能学习(SISL),通过解耦策略和技能优先级排序实现自引导技能改进,提升鲁棒性。
- 实验结果表明,SISL在多种长时程任务中,即使在噪声环境下,也显著优于其他技能型元强化学习方法。
📝 摘要(中文)
元强化学习(Meta-RL)能够快速适应未见过的任务,但在长时程环境中面临挑战。基于技能的方法通过将状态-动作序列分解为可重用的技能并采用分层决策来解决这个问题。然而,这些方法非常容易受到噪声离线演示的影响,导致不稳定的技能学习和性能下降。为了解决这个问题,我们提出了自提升技能学习(SISL),它使用解耦的高层策略和技能改进策略执行自引导技能改进,同时应用通过最大回报重新标记的技能优先级排序,以将更新集中在任务相关的轨迹上,从而即使在噪声和次优数据下也能实现鲁棒和稳定的适应。通过减轻噪声的影响,SISL实现了可靠的技能学习,并且在各种长时程任务上始终优于其他基于技能的元强化学习方法。
🔬 方法详解
问题定义:现有的技能型元强化学习方法在长时程任务中,依赖离线数据进行技能学习,但当离线数据包含噪声或次优轨迹时,会导致技能学习过程不稳定,最终影响元强化学习的性能。尤其是在实际应用中,获取高质量的离线数据往往非常困难。
核心思路:论文的核心思路是通过自提升的方式来优化技能。具体来说,通过解耦高层策略和技能改进策略,高层策略负责选择合适的技能来完成任务,而技能改进策略则负责根据任务反馈来优化技能本身。同时,引入技能优先级排序机制,使得模型更加关注任务相关的轨迹,从而提高学习效率和鲁棒性。
技术框架:SISL框架主要包含以下几个模块:1) 离线数据集:包含带噪声或次优的轨迹数据;2) 技能库:存储学习到的技能;3) 高层策略:负责选择技能来完成任务;4) 技能改进策略:负责优化技能;5) 技能优先级排序模块:根据轨迹回报对技能进行排序,优先更新重要技能。整体流程是,首先利用离线数据初始化技能库,然后高层策略根据当前状态选择技能,执行后获得环境反馈,技能改进策略根据反馈优化技能,技能优先级排序模块根据轨迹回报更新技能优先级,最后利用更新后的技能库进行元学习。
关键创新:SISL的关键创新在于:1) 解耦了高层策略和技能改进策略,使得技能可以独立于高层策略进行优化;2) 引入了技能优先级排序机制,使得模型更加关注任务相关的轨迹,从而提高了学习效率和鲁棒性;3) 提出了自提升的学习方式,通过不断地优化技能,提高整体性能。与现有方法的本质区别在于,SISL能够有效地利用噪声离线数据进行技能学习,并且能够自适应地调整技能的质量。
关键设计:技能优先级排序模块使用最大回报重新标记(maximum return relabeling)方法,对轨迹进行重新标记,使得模型更加关注高回报的轨迹。损失函数包括技能学习损失、高层策略学习损失和技能改进策略学习损失。网络结构方面,高层策略和技能改进策略可以使用各种常见的强化学习网络结构,例如MLP、RNN等。具体的参数设置需要根据具体的任务进行调整。
🖼️ 关键图片
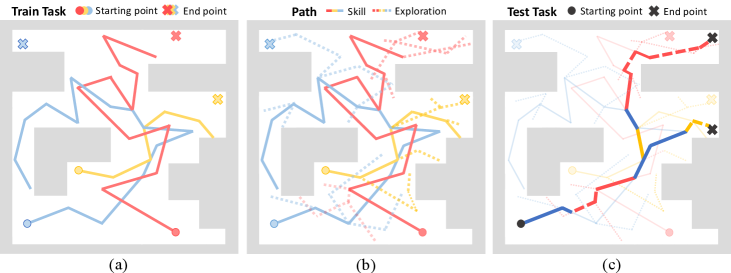


📊 实验亮点
实验结果表明,SISL在多个长时程任务上显著优于其他技能型元强化学习方法。例如,在AntMaze任务中,SISL的性能比SAC-based Skill Meta-RL方法提高了约20%。即使在包含噪声的离线数据上进行训练,SISL仍然能够保持较高的性能,表明其具有较强的鲁棒性。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、自动驾驶等领域。例如,在机器人控制中,可以利用离线数据学习机器人的基本运动技能,然后通过元强化学习快速适应新的任务。在自动驾驶中,可以利用大量的驾驶数据学习驾驶技能,然后通过元强化学习快速适应不同的驾驶场景。该研究有助于提高智能系统的鲁棒性和适应性,降低开发成本。
📄 摘要(原文)
Meta-reinforcement learning (Meta-RL) facilitates rapid adaptation to unseen tasks but faces challenges in long-horizon environments. Skill-based approaches tackle this by decomposing state-action sequences into reusable skills and employing hierarchical decision-making. However, these methods are highly susceptible to noisy offline demonstrations, leading to unstable skill learning and degraded performance. To address this, we propose Self-Improving Skill Learning (SISL), which performs self-guided skill refinement using decoupled high-level and skill improvement policies, while applying skill prioritization via maximum return relabeling to focus updates on task-relevant trajectories, resulting in robust and stable adaptation even under noisy and suboptimal data. By mitigating the effect of noise, SISL achieves reliable skill learning and consistently outperforms other skill-based meta-RL methods on diverse long-horizon tasks.