Bilevel ZOFO: Efficient LLM Fine-Tuning and Meta-Training
作者: Reza Shirkavand, Peiran Yu, Qi He, Heng Huang
分类: cs.LG
发布日期: 2025-02-05 (更新: 2025-12-15)
💡 一句话要点
提出Bilevel-ZOFO以解决LLM微调效率问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 微调 双层优化 参数高效微调 零阶方法 元学习 计算效率
📋 核心要点
- 现有的参数高效微调方法在高任务特定准确度要求下,往往表现不如全微调,且零阶方法收敛慢、对提示选择敏感。
- Bilevel-ZOFO通过在内层快速局部FO-PEFT适应与外层稳定的零阶更新相结合,解决了上述问题,提升了微调效率。
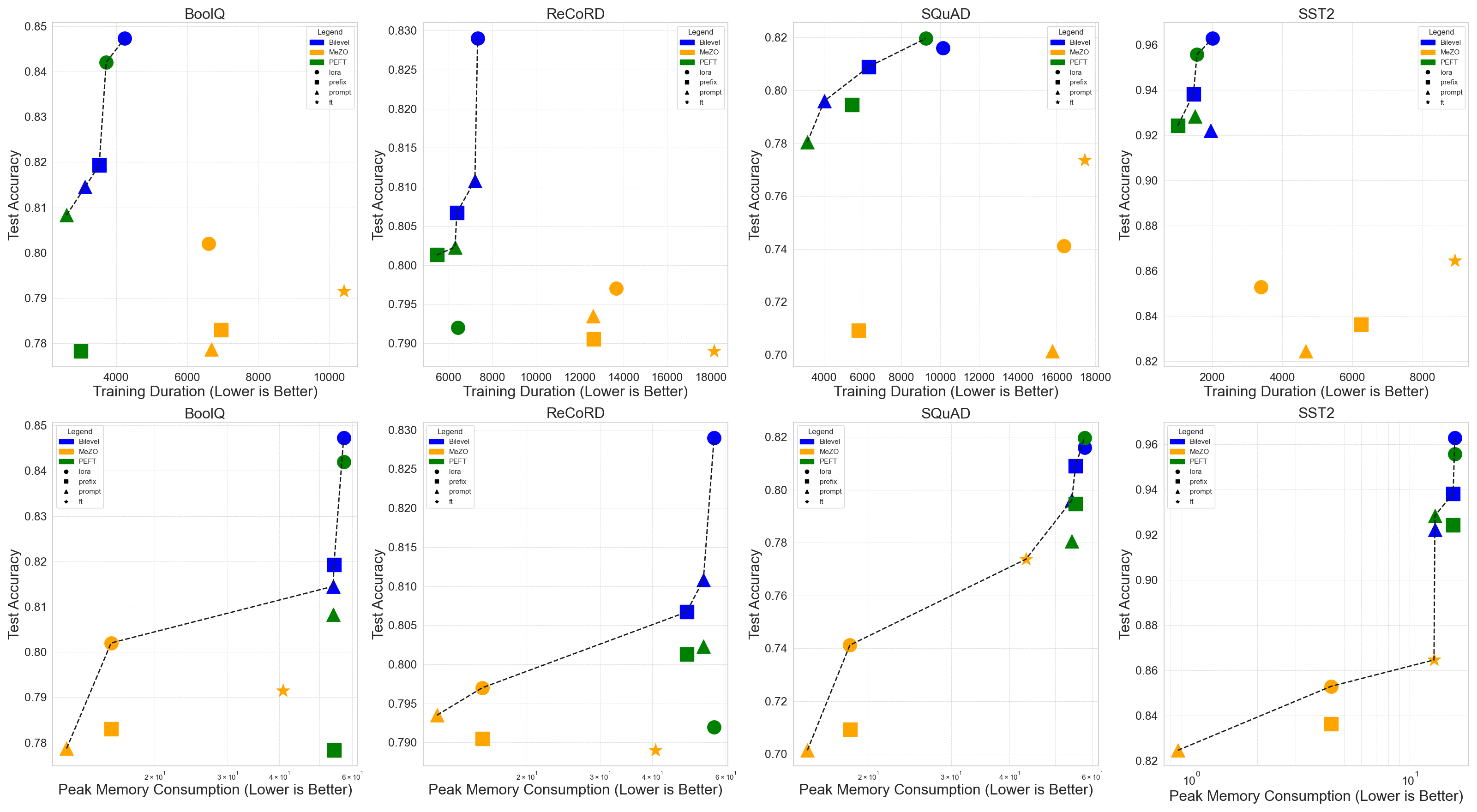
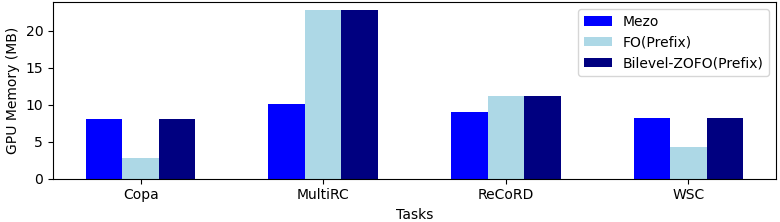
- 实验结果表明,Bilevel-ZOFO在训练速度上比现有的零阶和FO-PEFT方法快2-4倍,同时保持相似的内存使用效率。
📝 摘要(中文)
针对使用一阶优化器微调预训练大型语言模型(LLM)在计算上面临的挑战,本文提出了一种双层优化方法Bilevel-ZOFO。该方法结合了快速的局部一阶参数高效微调(FO-PEFT)和稳定的零阶更新,显著提高了训练效率。通过理论收敛保证和实证结果,Bilevel-ZOFO在训练速度上提升了2-4倍,同时保持了相似的内存效率。此外,该方法通过更新全模型并仅适应少量FO-PEFT模块,实现了全模型能力与少量样本效率的结合,展现出良好的元学习能力。
🔬 方法详解
问题定义:本文旨在解决使用一阶优化器微调大型语言模型时的计算效率问题。现有的参数高效微调方法在高任务特定准确度下表现不佳,而零阶方法则面临收敛慢和对提示选择敏感的挑战。
核心思路:Bilevel-ZOFO结合了快速的局部一阶参数高效微调(FO-PEFT)和稳定的零阶更新,通过内外层的双层优化结构,提升了微调的效率和稳定性。内层的FO-PEFT适应减少了零阶估计的方差,外层的零阶更新则增强了参数高效微调的泛化能力。
技术框架:Bilevel-ZOFO的整体架构包括内层的FO-PEFT适应和外层的零阶更新。内层负责快速适应特定任务,外层则进行全模型的更新。整个流程通过双层优化实现高效的模型微调。
关键创新:Bilevel-ZOFO的主要创新在于将FO-PEFT与零阶方法结合,形成双层优化结构。这一设计使得模型在保持高效性的同时,能够更好地适应新任务,显著提升了训练速度和稳定性。
关键设计:在实现中,FO-PEFT模块的参数设置经过精心设计,以确保在低内存消耗下实现快速适应。同时,零阶更新的策略也经过优化,以提高对任务的泛化能力。具体的损失函数和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果显示,Bilevel-ZOFO在训练速度上比现有的零阶和FO-PEFT方法快2-4倍,同时在内存效率上保持相似水平。这一显著提升表明该方法在实际应用中具有较高的效率和实用性,为大型语言模型的微调提供了新的思路。
🎯 应用场景
Bilevel-ZOFO在自然语言处理、对话系统和文本生成等领域具有广泛的应用潜力。其高效的微调能力使得模型能够快速适应新任务,降低了计算资源的需求,适合在资源受限的环境中部署。此外,该方法的元学习特性使其在少量样本学习场景中表现出色,推动了智能系统的快速迭代与应用。
📄 摘要(原文)
Fine-tuning pre-trained Large Language Models (LLMs) for downstream tasks using First-Order (FO) optimizers presents significant computational challenges. Parameter-Efficient Fine-Tuning (PEFT) methods address these by freezing most model parameters and training only a small subset. However, PEFT often underperforms compared to full fine-tuning when high task-specific accuracy is required. Zeroth-Order (ZO) methods fine-tune the entire pre-trained model without back-propagation, estimating gradients through forward passes only. While memory-efficient, ZO methods suffer from slow convergence and high sensitivity to prompt selection. We bridge these two worlds with Bilevel-ZOFO, a bilevel optimization method that couples fast, local FO-PEFT adaptation at the inner level with stable, memory-efficient ZO updates of the full backbone at the outer level. The FO-PEFT inner loop performs fast, low-memory local adaptation that reduces the variance of ZO estimates and stabilizes the search, guiding the outer ZO updates of the full backbone and reducing prompt sensitivity. In the mean time, the outer ZO provides better generalization ability for PEFT. We provide theoretical convergence guarantees and empirically demonstrate that Bilevel-ZOFO significantly outperforms existing ZO and FO-PEFT methods, achieving 2-4 times faster training while maintaining similar memory efficiency. Additionally, we show by updating the backbone with ZO and adapting only a tiny FO-PEFT block per task, Bilevel-ZOFO combines full-model capacity with few-shot efficiency, making it a very efficient meta-learning algorithm that quickly adapts to new tasks.