HACK: Homomorphic Acceleration via Compression of the Key-Value Cache for Disaggregated LLM Inference
作者: Zeyu Zhang, Haiying Shen, Shay Vargaftik, Ran Ben Basat, Michael Mitzenmacher, Minlan Yu
分类: cs.DC, cs.LG
发布日期: 2025-02-05
💡 一句话要点
HACK:通过压缩键值缓存实现异构LLM推理的同态加速
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 异构LLM推理 键值缓存 同态加速 量化 压缩 作业完成时间 矩阵乘法
📋 核心要点
- 异构LLM推理中,KV数据传输成为瓶颈,尤其是在长提示场景下,现有KV量化方法虽能缓解传输压力,但引入了显著的反量化开销。
- HACK的核心思想是直接在量化的KV数据上进行计算,避免反量化步骤,从而加速矩阵乘法运算,降低计算成本。
- 实验结果表明,HACK相比于异构LLM推理基线,JCT降低高达70.9%,相比于SOTA的KV量化方法,JCT降低高达52.3%。
📝 摘要(中文)
异构大型语言模型(LLM)推理因其将计算密集型的预填充阶段与内存密集型的解码阶段分离,避免了预填充-解码干扰并提高了资源利用率而日益普及。然而,在这两个阶段之间传输键值(KV)数据可能成为瓶颈,特别是对于长提示。此外,预填充和解码的计算时间开销是优化作业完成时间(JCT)的关键,并且KV数据大小对于长提示和序列而言可能变得过大。现有的KV量化方法可以缓解传输瓶颈并减少内存需求,但它们引入了显著的反量化开销,从而加剧了计算时间。我们提出了通过压缩KV缓存实现同态加速的HACK方法,用于异构LLM推理。HACK消除了繁重的KV反量化步骤,并直接对量化的KV数据执行计算,以近似并降低昂贵的矩阵乘法步骤的成本。大量的跟踪驱动实验表明,与异构LLM推理基线相比,HACK将JCT降低了高达70.9%,与最先进的KV量化方法相比,降低了高达52.3%。
🔬 方法详解
问题定义:论文旨在解决异构LLM推理中,由于预填充和解码阶段之间传输大量KV数据而导致的性能瓶颈问题。现有KV量化方法虽然可以压缩数据,但引入的反量化步骤会带来显著的计算开销,抵消了压缩带来的优势。尤其是在长提示和序列场景下,这个问题更加突出。
核心思路:HACK的核心思路是利用同态计算的思想,直接在量化的KV数据上进行计算,避免反量化步骤。通过设计一种特殊的量化方案,使得量化后的数据可以直接进行矩阵乘法等操作,从而加速推理过程。这种方法的核心在于找到一种既能有效压缩数据,又能保持计算性质的量化方案。
技术框架:HACK主要包含以下几个阶段:1. KV缓存的量化:使用特定的量化方案对KV缓存进行压缩。2. 同态计算:在量化的KV数据上直接进行矩阵乘法等计算。3. 结果的近似:由于量化带来的误差,需要对计算结果进行一定的近似处理,以保证推理精度。整个框架旨在消除反量化步骤,从而加速推理过程。
关键创新:HACK最重要的技术创新点在于提出了一种新的量化方案,该方案允许直接在量化的KV数据上进行计算,而无需进行反量化。这种方案的设计需要仔细考虑量化误差对计算结果的影响,并采取相应的措施进行补偿。与现有方法的本质区别在于,HACK避免了反量化步骤,从而显著降低了计算开销。
关键设计:HACK的关键设计包括:1. 量化方案的选择:需要选择一种既能有效压缩数据,又能保持计算性质的量化方案。2. 误差补偿机制:由于量化带来的误差,需要设计一种有效的误差补偿机制,以保证推理精度。3. 计算优化:需要对量化后的计算过程进行优化,以进一步提高计算效率。具体的参数设置、损失函数、网络结构等技术细节未知。
🖼️ 关键图片
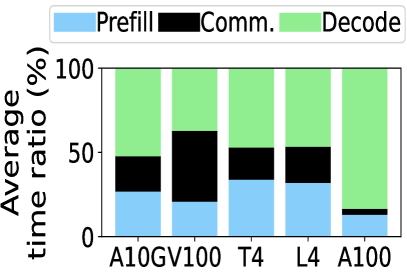
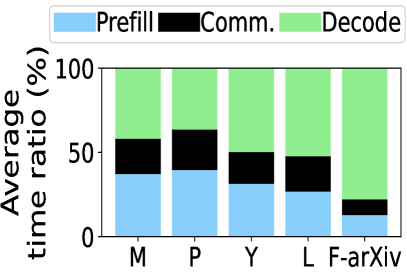

📊 实验亮点
实验结果表明,HACK在异构LLM推理任务中取得了显著的性能提升。与异构LLM推理基线相比,HACK将作业完成时间(JCT)降低了高达70.9%。与最先进的KV量化方法相比,HACK也将JCT降低了高达52.3%。这些结果表明,HACK能够有效地加速异构LLM推理,并降低计算成本。
🎯 应用场景
HACK具有广泛的应用前景,可以应用于各种需要进行异构LLM推理的场景,例如云端推理服务、边缘设备推理等。通过降低推理延迟和计算成本,HACK可以提高LLM的可用性和可扩展性,并促进LLM在更多领域的应用。该研究对于推动LLM推理技术的发展具有重要意义。
📄 摘要(原文)
Disaggregated Large Language Model (LLM) inference has gained popularity as it separates the computation-intensive prefill stage from the memory-intensive decode stage, avoiding the prefill-decode interference and improving resource utilization. However, transmitting Key-Value (KV) data between the two stages can be a bottleneck, especially for long prompts. Additionally, the computation time overhead for prefill and decode is key for optimizing Job Completion Time (JCT), and KV data size can become prohibitive for long prompts and sequences. Existing KV quantization methods can alleviate the transmission bottleneck and reduce memory requirements, but they introduce significant dequantization overhead, exacerbating the computation time. We propose Homomorphic Acceleration via Compression of the KV cache (HACK) for disaggregated LLM inference. HACK eliminates the heavy KV dequantization step, and directly performs computations on quantized KV data to approximate and reduce the cost of the expensive matrix-multiplication step. Extensive trace-driven experiments show that HACK reduces JCT by up to 70.9% compared to disaggregated LLM inference baseline and by up to 52.3% compared to state-of-the-art KV quantization methods.