TD-M(PC)$^2$: Improving Temporal Difference MPC Through Policy Constraint
作者: Haotian Lin, Pengcheng Wang, Jeff Schneider, Guanya Shi
分类: cs.LG, cs.RO
发布日期: 2025-02-05
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
TD-M(PC)$^2$:通过策略约束改进时序差分模型预测控制,提升数据效率
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模型预测控制 强化学习 价值学习 策略约束 时序差分学习 人形机器人 连续控制 数据效率
📋 核心要点
- 现有基于模型的强化学习方法在价值学习中存在持续的价值高估问题,源于规划器引导的数据与学习策略之间的不匹配。
- 提出一种策略正则化方法,通过减少超出分布的查询来缓解策略不匹配,从而改善价值学习,且无需额外计算。
- 实验表明,该方法在TD-MPC2等基线上有显著提升,尤其在复杂的人形机器人控制任务中表现突出。
📝 摘要(中文)
基于模型的强化学习算法结合了基于模型的规划和学习到的价值/策略先验,因其高数据效率和在连续控制中的卓越性能而备受认可。然而,我们发现,现有方法依赖于标准的SAC风格策略迭代进行价值学习,直接使用规划器生成的数据,通常会导致持续的价值高估。通过理论分析和实验,我们认为这个问题深植于数据生成策略(始终由规划器引导)与学习到的策略先验之间的结构性策略不匹配。为了以最小的代价缓解这种不匹配,我们提出了一个策略正则化项,减少了超出分布(OOD)的查询,从而改进了价值学习。我们的方法在现有框架之上进行了最小的修改,并且不需要额外的计算。大量的实验表明,所提出的方法在诸如TD-MPC2等基线上有了很大的改进,尤其是在61自由度的人形机器人任务中。
🔬 方法详解
问题定义:现有基于模型的强化学习方法,特别是那些结合了模型预测控制(MPC)和学习价值/策略先验的方法,在连续控制任务中表现出色。然而,这些方法在价值学习过程中,直接使用MPC规划器生成的数据,导致了持续的价值高估问题。这种高估阻碍了策略的有效学习和优化,限制了算法的性能。现有方法的痛点在于忽略了MPC规划器和学习策略之间的结构性差异,导致价值函数学习的偏差。
核心思路:论文的核心思路是通过引入策略约束来缓解MPC规划器和学习策略之间的不匹配。具体来说,通过添加一个策略正则化项,惩罚学习策略对超出分布(OOD)状态的查询,从而限制学习策略的行为,使其更接近MPC规划器生成的数据分布。这种策略约束有助于减少价值高估,提高价值函数的准确性。
技术框架:TD-M(PC)$^2$方法建立在现有的TD-MPC框架之上,主要包含以下几个模块:1) 系统动力学模型:用于预测未来状态;2) 模型预测控制(MPC)规划器:基于动力学模型生成轨迹数据;3) 价值函数学习器:使用时序差分学习更新价值函数;4) 策略学习器:学习控制策略。关键改进在于策略学习器中引入了策略约束项,以减少OOD查询。
关键创新:该方法最重要的技术创新点在于策略约束项的设计。与直接约束策略输出不同,该方法通过惩罚OOD查询来间接约束策略行为,从而避免了对策略表达能力的过度限制。这种策略约束方法简单有效,易于集成到现有的基于模型的强化学习框架中,并且不需要额外的计算开销。
关键设计:策略约束项的具体形式是基于KL散度的正则化项,用于衡量学习策略与MPC规划器生成的数据分布之间的差异。该正则化项被添加到策略学习的损失函数中,通过调整正则化系数来控制策略约束的强度。此外,该方法对现有TD-MPC框架的修改非常小,只需要在策略学习的损失函数中添加一个额外的正则化项即可。
🖼️ 关键图片

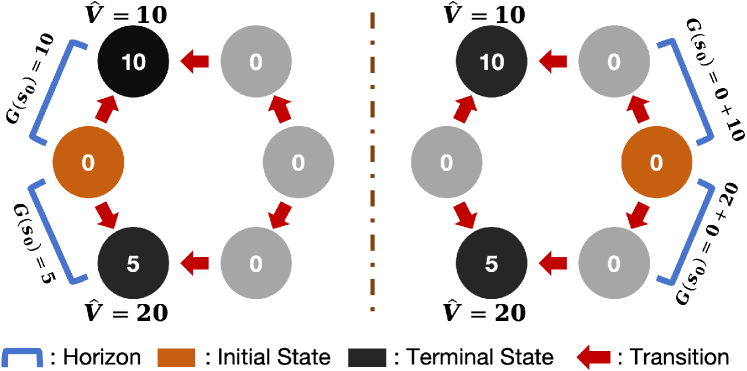

📊 实验亮点
实验结果表明,TD-M(PC)$^2$方法在多个连续控制任务中显著优于基线方法,包括TD-MPC2。特别是在61自由度的人形机器人任务中,TD-M(PC)$^2$实现了大幅度的性能提升,证明了策略约束在缓解价值高估和提高策略学习效率方面的有效性。此外,该方法仅需对现有框架进行最小的修改,且无需额外计算,使其具有很强的实用性。
🎯 应用场景
该研究成果可应用于各种需要高数据效率和精确控制的机器人任务,例如人形机器人控制、自动驾驶、工业自动化等。通过减少价值高估,提高策略学习的稳定性和性能,可以使机器人在复杂环境中更快地学习到有效的控制策略,从而实现更安全、更高效的自主操作。未来,该方法有望扩展到更广泛的强化学习应用领域。
📄 摘要(原文)
Model-based reinforcement learning algorithms that combine model-based planning and learned value/policy prior have gained significant recognition for their high data efficiency and superior performance in continuous control. However, we discover that existing methods that rely on standard SAC-style policy iteration for value learning, directly using data generated by the planner, often result in \emph{persistent value overestimation}. Through theoretical analysis and experiments, we argue that this issue is deeply rooted in the structural policy mismatch between the data generation policy that is always bootstrapped by the planner and the learned policy prior. To mitigate such a mismatch in a minimalist way, we propose a policy regularization term reducing out-of-distribution (OOD) queries, thereby improving value learning. Our method involves minimum changes on top of existing frameworks and requires no additional computation. Extensive experiments demonstrate that the proposed approach improves performance over baselines such as TD-MPC2 by large margins, particularly in 61-DoF humanoid tasks. View qualitative results at https://darthutopian.github.io/tdmpc_square/.