Teaching Language Models to Critique via Reinforcement Learning
作者: Zhihui Xie, Jie Chen, Liyu Chen, Weichao Mao, Jingjing Xu, Lingpeng Kong
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-02-05 (更新: 2025-11-29)
💡 一句话要点
提出CTRL框架,通过强化学习训练代码生成评论模型,提升LLM代码生成能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 强化学习 语言模型 评论模型 迭代优化
📋 核心要点
- 现有LLM难以提供准确的代码生成评价和改进建议,限制了其迭代优化能力。
- CTRL框架利用强化学习训练评论模型,使其能够生成最大化代码修正性能的反馈。
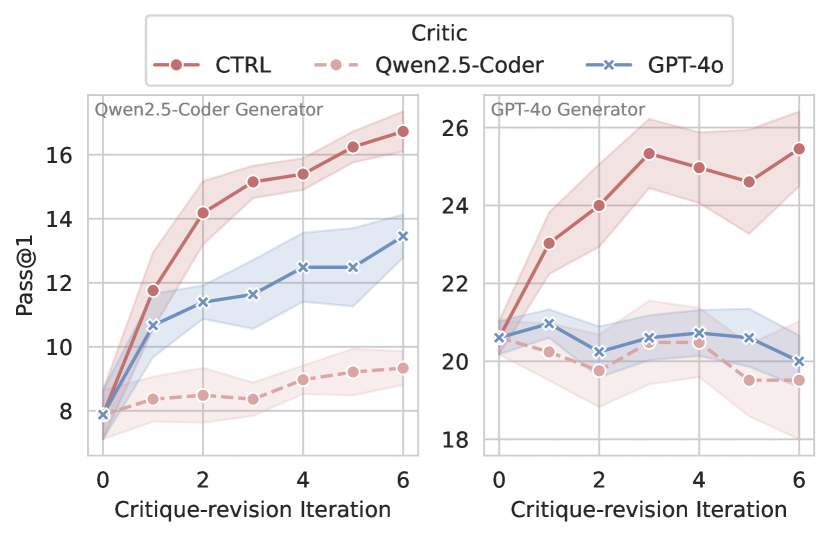
- 实验表明,CTRL显著提升了代码生成通过率,并能有效缓解误差累积问题。
📝 摘要(中文)
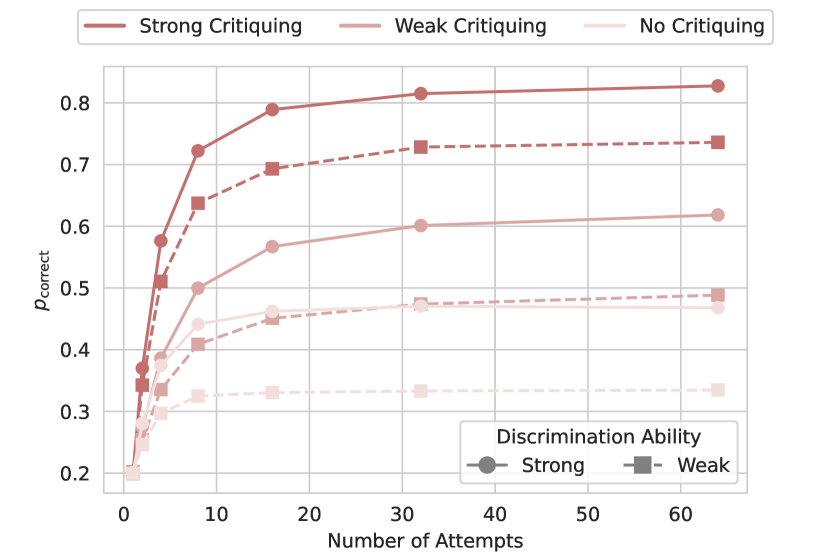
训练大型语言模型(LLM)以评论和改进其输出对于构建能够迭代改进的系统至关重要,但其根本上受到提供准确判断和可操作建议的能力的限制。本文研究了用于代码生成的LLM评论模型,并提出了CTRL框架,即通过强化学习进行评论模型训练,该框架训练评论模型以生成反馈,从而在没有人工监督的情况下,最大化固定生成器模型的修正性能。结果表明,使用CTRL训练的评论模型显著提高了通过率,并减轻了基础和更强的生成器模型中的复合误差。此外,我们表明这些评论模型充当了准确的生成奖励模型,并通过迭代评论-修订实现测试时扩展,在具有挑战性的代码生成基准测试中实现了高达106.1%的相对改进。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在代码生成任务中,缺乏有效的自我评价和改进机制的问题。现有方法依赖人工标注或简单的规则,难以提供准确、可操作的反馈,导致生成代码的质量难以保证,且容易出现误差累积。
核心思路:论文的核心思路是利用强化学习训练一个专门的评论模型(Critic),该模型能够对生成器(Generator)生成的代码进行评价,并给出改进建议。通过强化学习,评论模型的目标是最大化生成器修正后的代码的性能,从而间接提升生成器的代码质量。
技术框架:CTRL框架包含两个主要模块:代码生成器和评论模型。代码生成器负责生成代码,评论模型负责对生成的代码进行评价并给出反馈。整个训练流程如下:1) 代码生成器生成代码;2) 评论模型对生成的代码进行评价,并给出修改建议;3) 基于评论模型的建议,代码生成器对代码进行修正;4) 使用修正后的代码的性能作为奖励信号,通过强化学习更新评论模型。
关键创新:CTRL框架的关键创新在于使用强化学习来训练评论模型,使其能够生成最大化代码修正性能的反馈。与传统的监督学习方法相比,强化学习能够更好地捕捉代码生成任务的复杂性,并学习到更有效的评价和改进策略。此外,该方法无需人工标注数据,降低了训练成本。
关键设计:评论模型采用Transformer架构,输入为生成的代码,输出为修改建议。强化学习算法采用策略梯度方法,奖励函数为修正后代码的执行成功率。为了避免奖励稀疏问题,论文还引入了中间奖励,例如代码的语法正确性等。具体参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用CTRL框架训练的评论模型显著提高了代码生成通过率,在多个代码生成基准测试中取得了显著的性能提升。例如,在某项测试中,相对基线模型实现了高达106.1%的相对改进。此外,实验还验证了评论模型可以作为准确的生成奖励模型,并通过迭代评论-修订实现测试时扩展。
🎯 应用场景
该研究成果可应用于自动化代码生成、代码审查、智能编程助手等领域。通过训练高质量的评论模型,可以显著提升代码生成效率和质量,降低软件开发成本,并为开发者提供更智能的编程辅助工具。未来,该方法还可以扩展到其他自然语言生成任务中,例如文本摘要、机器翻译等。
📄 摘要(原文)
Teaching large language models (LLMs) to critique and refine their outputs is crucial for building systems that can iteratively improve, yet it is fundamentally limited by the ability to provide accurate judgments and actionable suggestions. In this work, we study LLM critics for code generation and propose $\texttt{CTRL}$, a framework for $\texttt{C}$ritic $\texttt{T}$raining via $\texttt{R}$einforcement $\texttt{L}$earning, which trains a critic model to generate feedback that maximizes correction performance for a fixed generator model without human supervision. Our results demonstrate that critics trained with $\texttt{CTRL}$ significantly enhance pass rates and mitigate compounding errors across both base and stronger generator models. Furthermore, we show that these critic models act as accurate generative reward models and enable test-time scaling through iterative critique-revision, achieving up to 106.1% relative improvements across challenging code generation benchmarks.