Do Large Language Model Benchmarks Test Reliability?
作者: Joshua Vendrow, Edward Vendrow, Sara Beery, Aleksander Madry
分类: cs.LG, cs.CL
发布日期: 2025-02-05
🔗 代码/项目: GITHUB
💡 一句话要点
提出铂金基准测试集,解决大语言模型可靠性评估中标签错误问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 可靠性评估 基准测试 标签错误 铂金基准
📋 核心要点
- 现有大语言模型基准测试存在标签错误,影响了模型可靠性的准确评估。
- 论文提出“铂金基准”概念,通过精心校正标签错误和消除歧义来提高基准质量。
- 实验表明,即使在铂金基准上,前沿LLM在简单任务中仍存在失败,揭示了模型固有的弱点。
📝 摘要(中文)
在部署大型语言模型(LLM)时,确保这些模型不仅具有能力,而且具有可靠性非常重要。虽然已经创建了许多基准来跟踪LLM不断增长的能力,但尚未有类似地关注于衡量其可靠性。为了理解这种差距的潜在影响,我们研究了当前基准在多大程度上量化了模型的可靠性。我们发现普遍存在的标签错误会损害这些评估,掩盖了持续存在的模型故障并隐藏了不可靠的行为。受可靠性评估中这一差距的推动,我们提出了所谓的铂金基准的概念,即经过精心策划以最大限度地减少标签错误和歧义的基准。作为构建此类基准的首次尝试,我们修改了来自十五个现有流行基准的示例。我们评估了这些铂金基准上的各种模型,发现前沿LLM仍然在简单的任务(如小学级别的数学文字问题)上表现出失败。进一步分析这些失败揭示了先前未识别的问题模式,即前沿模型始终难以解决的问题。我们在https://github.com/MadryLab/platinum-benchmarks提供了代码。
🔬 方法详解
问题定义:现有的大语言模型(LLM)基准测试在评估模型可靠性方面存在不足。主要问题在于基准数据集中普遍存在的标签错误和歧义,这些错误掩盖了模型实际存在的缺陷,导致对模型性能的评估不准确。现有方法无法有效区分模型是因为能力不足还是因为数据标签错误而失败。
核心思路:论文的核心思路是构建高质量的“铂金基准”,通过人工审核和校正现有基准数据集中的标签错误和歧义,从而提供更可靠的模型评估。这种方法旨在消除数据质量对评估结果的干扰,更准确地反映模型的真实能力和可靠性。
技术框架:论文没有提出一个全新的技术框架,而是专注于对现有基准数据集进行改进。主要流程包括:1) 选择15个常用的LLM基准数据集;2) 人工审核这些数据集中的样本,识别并纠正标签错误和歧义;3) 使用修正后的数据集(即铂金基准)评估一系列LLM模型;4) 分析模型在铂金基准上的表现,识别模型存在的弱点和失败模式。
关键创新:论文的关键创新在于提出了“铂金基准”的概念,并强调了数据质量在LLM评估中的重要性。与以往关注模型架构和训练方法的研究不同,该论文关注于评估数据的质量,并提出了一种系统性的方法来提高评估数据的可靠性。
关键设计:论文的关键设计在于人工审核和校正标签错误的过程。具体细节未知,但可以推测需要领域专家参与,并制定明确的标注规范,以确保校正后的标签准确可靠。论文未提及具体的参数设置、损失函数或网络结构,因为其重点在于数据集的改进而非模型本身。
🖼️ 关键图片

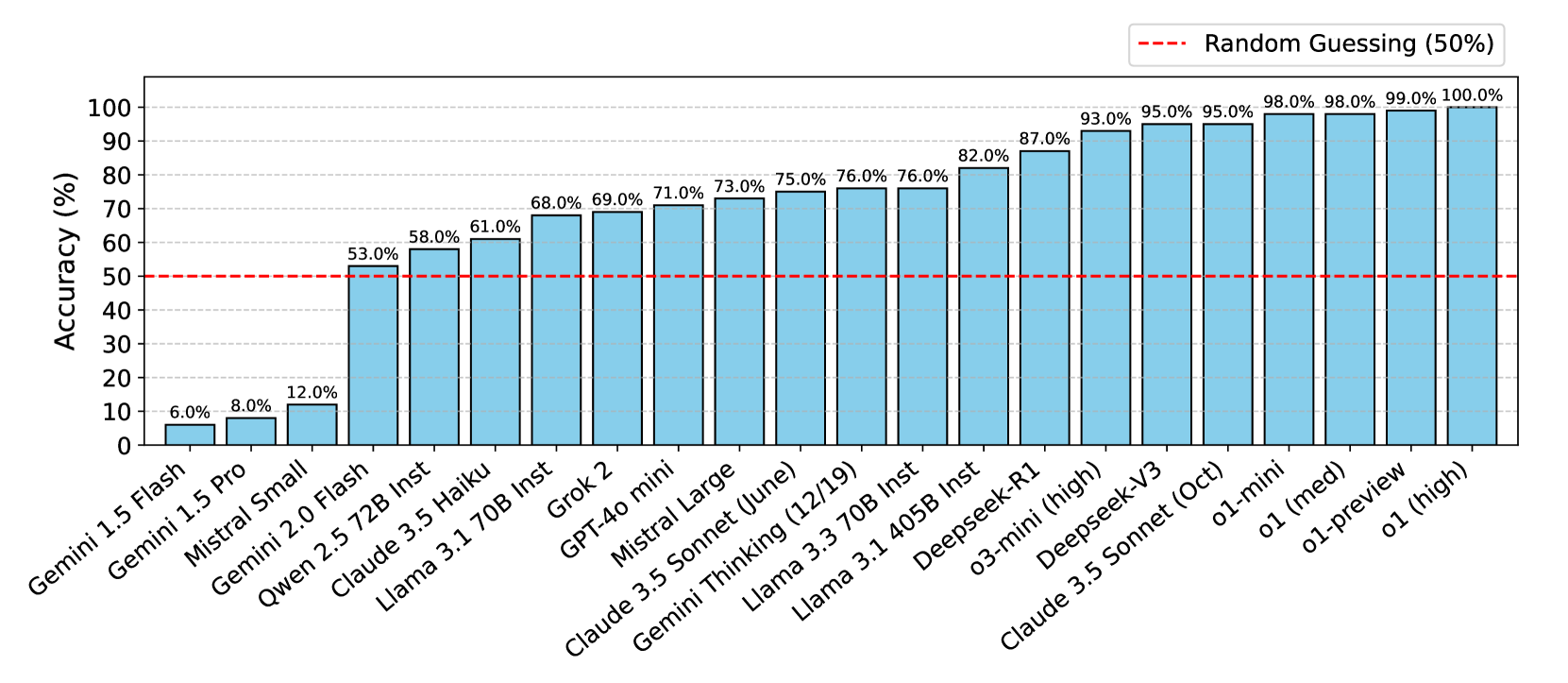
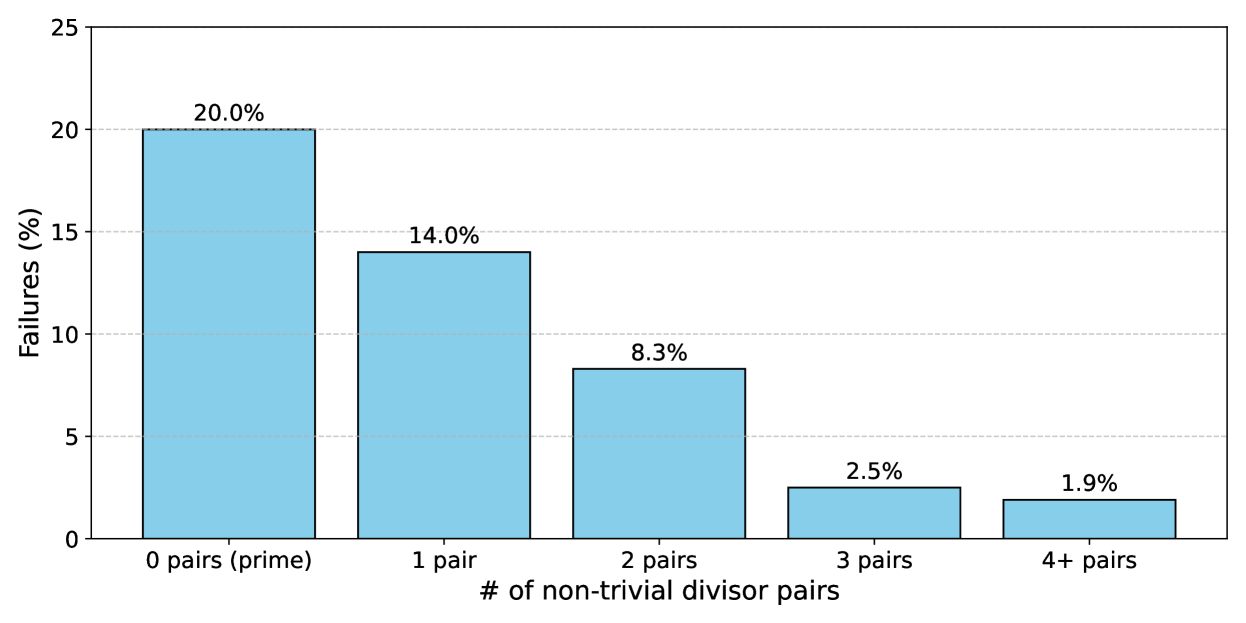
📊 实验亮点
论文通过在铂金基准上评估一系列前沿LLM,发现即使在经过精心校正的数据集上,这些模型仍然在简单的任务(如小学级别的数学文字问题)上表现出失败。这些失败揭示了先前未识别的问题模式,表明即使是最先进的LLM也存在固有的弱点。
🎯 应用场景
该研究成果可应用于大语言模型的可靠性评估、模型选择和模型改进。通过使用铂金基准,可以更准确地评估模型的性能,从而选择更可靠的模型部署到实际应用中。此外,铂金基准还可以帮助研究人员识别模型存在的弱点,从而有针对性地改进模型。
📄 摘要(原文)
When deploying large language models (LLMs), it is important to ensure that these models are not only capable, but also reliable. Many benchmarks have been created to track LLMs' growing capabilities, however there has been no similar focus on measuring their reliability. To understand the potential ramifications of this gap, we investigate how well current benchmarks quantify model reliability. We find that pervasive label errors can compromise these evaluations, obscuring lingering model failures and hiding unreliable behavior. Motivated by this gap in the evaluation of reliability, we then propose the concept of so-called platinum benchmarks, i.e., benchmarks carefully curated to minimize label errors and ambiguity. As a first attempt at constructing such benchmarks, we revise examples from fifteen existing popular benchmarks. We evaluate a wide range of models on these platinum benchmarks and find that, indeed, frontier LLMs still exhibit failures on simple tasks such as elementary-level math word problems. Analyzing these failures further reveals previously unidentified patterns of problems on which frontier models consistently struggle. We provide code at https://github.com/MadryLab/platinum-benchmarks