A Match Made in Heaven? AI-driven Matching of Vulnerabilities and Security Unit Tests
作者: Emanuele Iannone, Quang-Cuong Bui, Riccardo Scandariato
分类: cs.SE, cs.CR, cs.LG
发布日期: 2025-02-05 (更新: 2026-01-08)
备注: Accepted in the MSR 2026 Technical Track. This work was partially supported by EU-funded project Sec4AI4Sec (grant no. 101120393)
💡 一句话要点
VuTeCo:AI驱动的漏洞与安全单元测试匹配框架,促进安全测试用例生成。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 软件安全 单元测试 漏洞检测 AI驱动 代码理解
📋 核心要点
- 现有方法缺乏足够的漏洞见证测试用例,阻碍了AI模型学习生成安全相关的单元测试。
- VuTeCo框架通过“发现”和“匹配”两个任务,自动从Java项目中提取并关联漏洞与对应的测试用例。
- 实验表明,VuTeCo在Vul4J数据集上取得了良好的F0.5分数和精度,并构建了新的Test4Vul数据集。
📝 摘要(中文)
软件漏洞通常通过污点分析、渗透测试或模糊测试来检测。它们也可以通过单元测试发现,这些单元测试使用特定输入来执行安全敏感的行为,被称为漏洞见证测试。生成式AI模型可以帮助开发者编写这些测试,但它们需要大量的学习示例,而目前这些示例非常稀缺。本文介绍了一种AI驱动的框架VuTeCo,用于从Java仓库中收集漏洞见证测试的示例。VuTeCo执行两个任务:(1)“发现”任务,确定一个单元测试用例是否与安全相关;(2)“匹配”任务,将测试用例与其见证的漏洞相关联。VuTeCo使用UniXcoder解决“发现”任务,在来自Vul4J的单元测试数据集上实现了0.73的F0.5分数和0.83的精度。使用DeepSeek Coder解决“匹配”任务,在来自Vul4J的单元测试和漏洞对数据集上实现了0.65的F0.5分数和0.75的精度。VuTeCo已在427个Java项目和1,238个漏洞上进行了实际应用,获得了224个被确认为与安全相关的测试用例,以及35个正确匹配到29个漏洞的测试。验证后的测试被收集在一个名为Test4Vul的新数据集中。VuTeCo为大规模检索漏洞见证测试奠定了基础,使未来的AI模型能够更好地理解和生成安全单元测试。
🔬 方法详解
问题定义:论文旨在解决安全单元测试用例稀缺的问题。现有方法依赖人工编写或动态分析,效率低且覆盖率有限。缺乏大规模的漏洞见证测试用例,使得AI模型难以学习并生成有效的安全测试。
核心思路:论文的核心思路是利用AI模型自动识别和匹配漏洞与对应的单元测试用例。通过“发现”任务筛选出安全相关的测试用例,并通过“匹配”任务将测试用例与特定的漏洞关联起来,从而构建大规模的漏洞见证测试数据集。
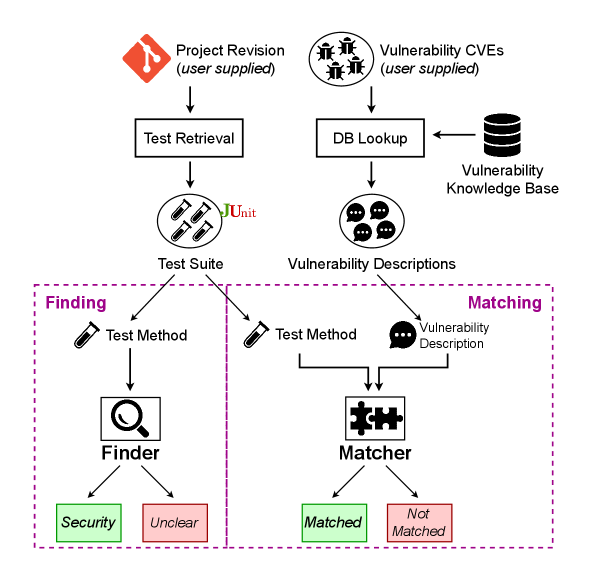
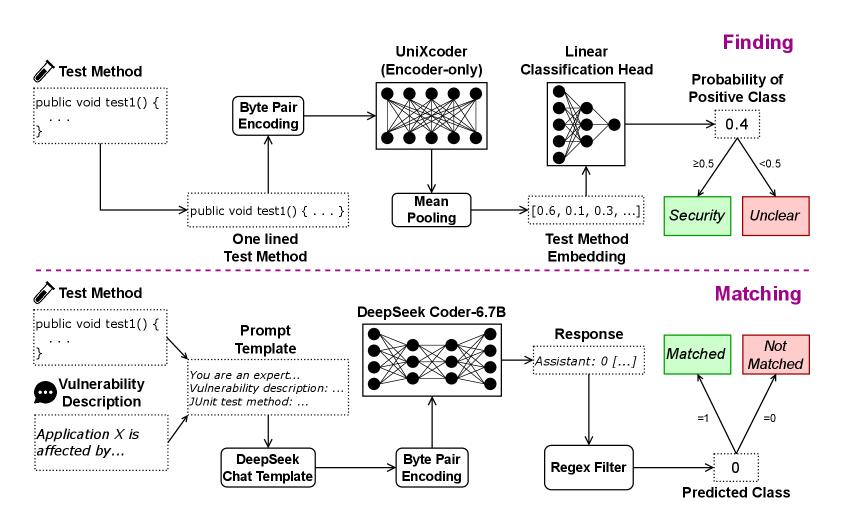
技术框架:VuTeCo框架包含两个主要模块:Finding和Matching。Finding模块使用UniXcoder模型判断单元测试是否与安全相关。Matching模块使用DeepSeek Coder模型将测试用例与漏洞进行匹配。整个流程包括从Java项目中提取单元测试和漏洞信息,然后分别使用Finding和Matching模块进行处理,最后将验证后的测试用例添加到Test4Vul数据集中。
关键创新:该论文的关键创新在于提出了一个完整的AI驱动框架,用于自动收集和匹配漏洞见证测试用例。与传统方法相比,VuTeCo能够大规模地从实际项目中提取有用的测试用例,从而为AI模型学习安全测试生成提供了数据基础。
关键设计:Finding任务使用UniXcoder模型,采用预训练的Transformer架构,针对代码理解任务进行了微调。Matching任务使用DeepSeek Coder模型,同样基于Transformer架构,但更侧重于代码生成和理解。评估指标采用F0.5分数和精度,更侧重于正例的准确性。数据集来自Vul4J,包含大量的Java漏洞和对应的修复信息。
🖼️ 关键图片
📊 实验亮点
VuTeCo在Vul4J数据集上取得了显著成果,Finding任务的F0.5分数为0.73,精度为0.83;Matching任务的F0.5分数为0.65,精度为0.75。通过在427个Java项目上的实际应用,收集了224个安全相关的测试用例,并正确匹配了35个测试用例到29个漏洞。这些验证后的测试用例被整理成Test4Vul数据集。
🎯 应用场景
该研究成果可应用于软件安全测试自动化领域,帮助开发者更高效地生成和维护安全相关的单元测试。通过构建大规模的漏洞见证测试数据集,可以训练更强大的AI模型,自动发现和修复软件漏洞,提升软件的整体安全性。未来,该方法可以扩展到其他编程语言和安全漏洞类型。
📄 摘要(原文)
Software vulnerabilities are often detected via taint analysis, penetration testing, or fuzzing. They are also found via unit tests that exercise security-sensitive behavior with specific inputs, called vulnerability-witnessing tests. Generative AI models could help developers in writing them, but they require many examples to learn from, which are currently scarce. This paper introduces VuTeCo, an AI-driven framework for collecting examples of vulnerability-witnessing tests from Java repositories. VuTeCo carries out two tasks: (1) The "Finding" task to determine whether a unit test case is security-related, and (2) the "Matching" task to relate a test case to the vulnerability it witnesses. VuTeCo addresses the Finding task with UniXcoder, achieving an F0.5 score of 0.73 and a precision of 0.83 on a test set of unit tests from Vul4J. The Matching task is addressed using DeepSeek Coder, achieving an F0.5 score of 0.65 and a precision of 0.75 on a test set of pairs of unit tests and vulnerabilities from Vul4J. VuTeCo has been used in the wild on 427 Java projects and 1,238 vulnerabilities, obtaining 224 test cases confirmed to be security-related and 35 tests correctly matched to 29 vulnerabilities. The validated tests were collected in a new dataset called Test4Vul. VuTeCo lays the foundation for large-scale retrieval of vulnerability-witnessing tests, enabling future AI models to better understand and generate security unit tests.