Analyze Feature Flow to Enhance Interpretation and Steering in Language Models
作者: Daniil Laptev, Nikita Balagansky, Yaroslav Aksenov, Daniil Gavrilov
分类: cs.LG, cs.CL
发布日期: 2025-02-05 (更新: 2025-07-24)
💡 一句话要点
提出跨层特征流分析方法,增强语言模型的可解释性和操控性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 可解释性 特征流分析 稀疏自编码器 模型操控 跨层分析 余弦相似度
📋 核心要点
- 现有方法难以追踪大型语言模型中特征在不同层之间的演变过程,限制了模型的可解释性。
- 本文提出一种基于余弦相似度的跨层特征流分析方法,用于追踪特征在模型层间的演化路径。
- 实验表明,该方法能够实现对模型行为的直接控制,例如通过调整特定特征来控制文本生成的主题。
📝 摘要(中文)
本文提出了一种新的方法,用于系统地映射大型语言模型连续层中由稀疏自编码器发现的特征,扩展了先前研究层间特征链接的工作。通过使用无数据的余弦相似度技术,我们追踪了特定特征如何在每个阶段持续存在、转换或首次出现。这种方法产生了特征演化的细粒度流图,从而能够进行细粒度的可解释性分析,并深入了解模型的计算机制。至关重要的是,我们展示了这些跨层特征图如何通过放大或抑制所选特征来促进模型行为的直接控制,从而在文本生成中实现有针对性的主题控制。总之,我们的发现突出了因果跨层可解释性框架的效用,该框架不仅阐明了特征如何通过前向传递发展,而且还为透明地操纵大型语言模型提供了新的手段。
🔬 方法详解
问题定义:现有方法在理解大型语言模型内部运作机制方面存在挑战,尤其是在追踪和理解特征在不同层之间的演变过程方面。缺乏有效的工具来分析特征如何在层与层之间传递、转换和交互,这限制了我们对模型决策过程的理解,也阻碍了对模型行为的精确控制。现有方法通常难以提供细粒度的、跨层的特征演化视图,从而难以进行深入的机制性分析。
核心思路:本文的核心思路是利用数据无关的余弦相似度来追踪特征在大型语言模型不同层之间的流动和演变。通过计算相邻层之间特征激活向量的余弦相似度,可以确定哪些特征在层间保持一致、哪些特征发生了改变、以及哪些特征是新出现的。这种方法无需额外的数据,可以直接应用于预训练的模型,从而揭示模型内部的特征传递和转换机制。
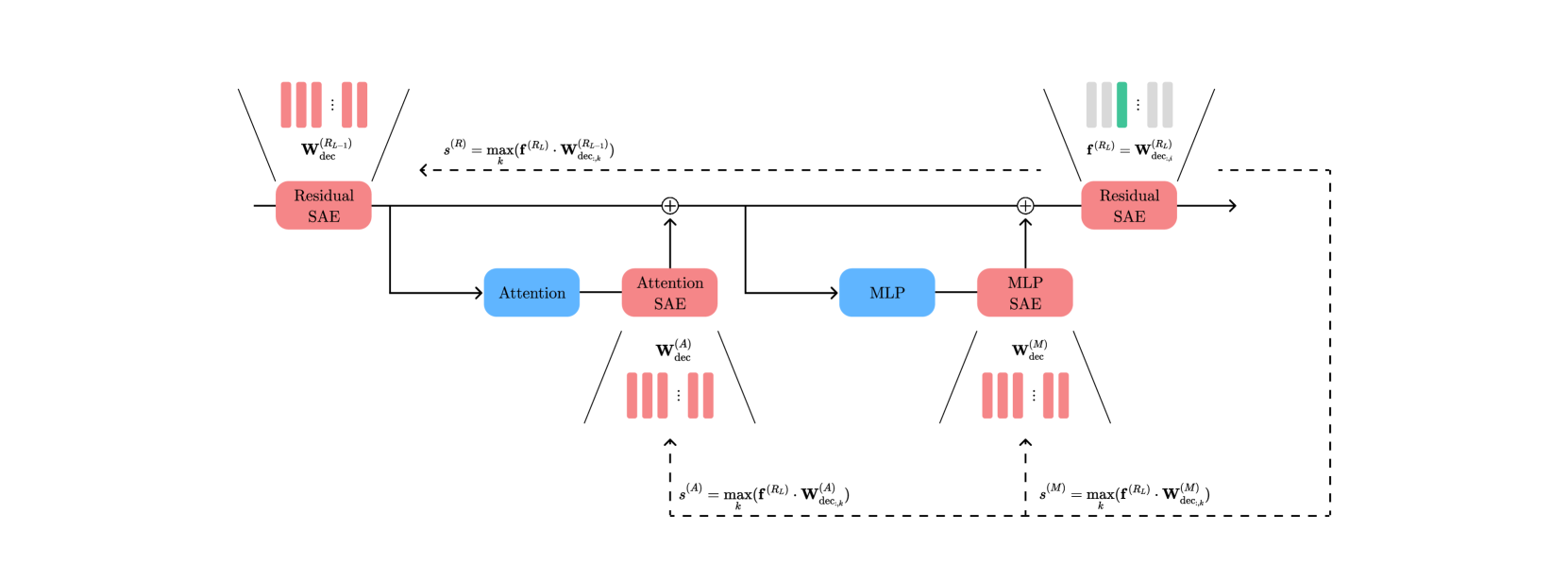
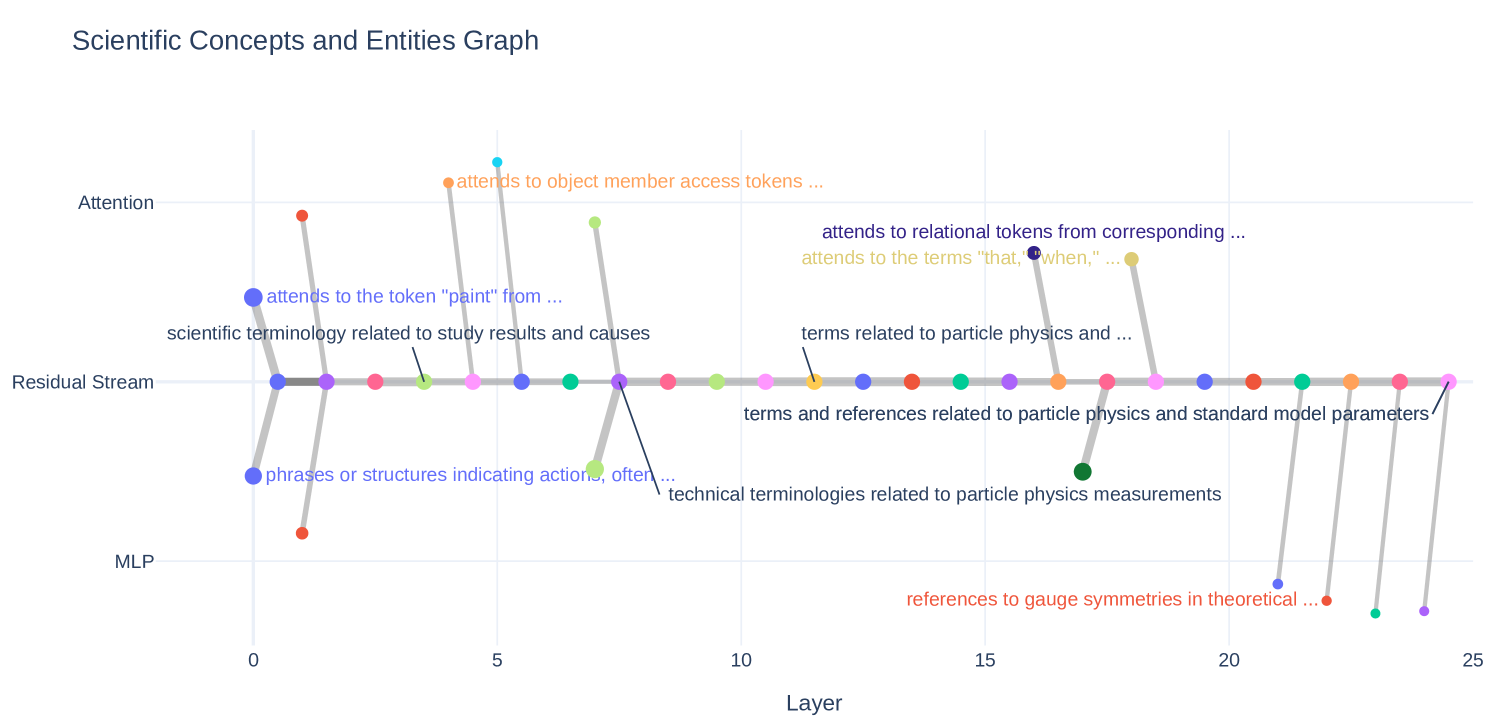
技术框架:该方法主要包含以下几个阶段:1) 利用稀疏自编码器在模型的每一层提取特征;2) 计算相邻层之间特征激活向量的余弦相似度,构建跨层特征映射;3) 基于特征映射构建特征流图,可视化特征在模型中的演化路径;4) 通过放大或抑制特定特征的激活值,实现对模型行为的控制。整体流程旨在提供一个可解释的框架,用于理解和操纵大型语言模型的内部表示。
关键创新:该方法最重要的创新点在于提出了一种数据无关的跨层特征流分析方法,能够系统地追踪特征在大型语言模型不同层之间的演化过程。与以往关注单层特征或层间简单连接的工作不同,该方法提供了细粒度的、跨层的特征演化视图,从而能够进行深入的机制性分析,并实现对模型行为的精确控制。
关键设计:关键设计包括:1) 使用稀疏自编码器提取特征,保证特征的稀疏性和可解释性;2) 使用余弦相似度作为特征匹配的度量,避免了对特定数据集的依赖;3) 构建特征流图,可视化特征在模型中的演化路径,方便用户理解和分析;4) 设计了特征放大和抑制机制,用于控制模型行为,例如通过调整特定特征的激活值来控制文本生成的主题。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法能够有效地追踪特征在大型语言模型不同层之间的演化过程,并实现对模型行为的精确控制。例如,通过放大或抑制特定特征,可以显著改变模型生成的文本主题,而无需重新训练模型。该方法为理解和操纵大型语言模型提供了一种新的途径。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可解释性、安全性和可控性。例如,可以用于识别模型中的有害特征,并对其进行抑制,从而提高模型的安全性。此外,该方法还可以用于控制模型的生成行为,例如通过调整特定特征来控制文本生成的主题和风格。该研究为开发更加可信赖和可控的人工智能系统奠定了基础。
📄 摘要(原文)
We introduce a new approach to systematically map features discovered by sparse autoencoder across consecutive layers of large language models, extending earlier work that examined inter-layer feature links. By using a data-free cosine similarity technique, we trace how specific features persist, transform, or first appear at each stage. This method yields granular flow graphs of feature evolution, enabling fine-grained interpretability and mechanistic insights into model computations. Crucially, we demonstrate how these cross-layer feature maps facilitate direct steering of model behavior by amplifying or suppressing chosen features, achieving targeted thematic control in text generation. Together, our findings highlight the utility of a causal, cross-layer interpretability framework that not only clarifies how features develop through forward passes but also provides new means for transparent manipulation of large language models.