Scaling Laws for Upcycling Mixture-of-Experts Language Models
作者: Seng Pei Liew, Takuya Kato, Sho Takase
分类: cs.LG, cs.CL
发布日期: 2025-02-05 (更新: 2025-06-16)
备注: ICML 2025. 16 figures, 8 tables. Code available at https://github.com/sbintuitions/sparse-upcycling-scaling-laws
💡 一句话要点
研究MoE语言模型Upcycling扩展规律,指导高效训练并超越从头训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 混合专家模型 Upcycling 扩展规律 模型训练
📋 核心要点
- 大型语言模型预训练成本高昂,Upcycling和MoE是降低成本的有效手段,但MoE模型Upcycling的扩展规律尚不明确。
- 本文通过大量实验,研究了数据集大小和模型配置对Upcycling MoE模型性能的影响,并发现了新的交互作用。
- 研究结果表明,存在限制Upcycling效率的因素,并为Upcycling提供了指导,确定了优于从头训练的条件。
📝 摘要(中文)
预训练大型语言模型(LLMs)需要大量的计算资源,即使使用高端GPU集群也通常需要数月的训练时间。目前有两种方法可以缓解这种计算需求:重用较小的模型来训练较大的模型(upcycling),以及训练计算效率高的模型,如混合专家模型(MoE)。本文研究了LLM到MoE模型的upcycling,其扩展行为仍未被充分探索。通过大量的实验,我们确定了描述性能如何依赖于数据集大小和模型配置的经验扩展规律。特别地,我们表明,虽然扩展这些因素可以提高性能,但在密集数据集和upcycling训练数据集之间存在一种新的交互作用,限制了在大型计算预算下upcycling的效率。基于这些发现,我们为扩展upcycling提供了指导,并建立了在预算约束内upcycling优于从头训练的条件。
🔬 方法详解
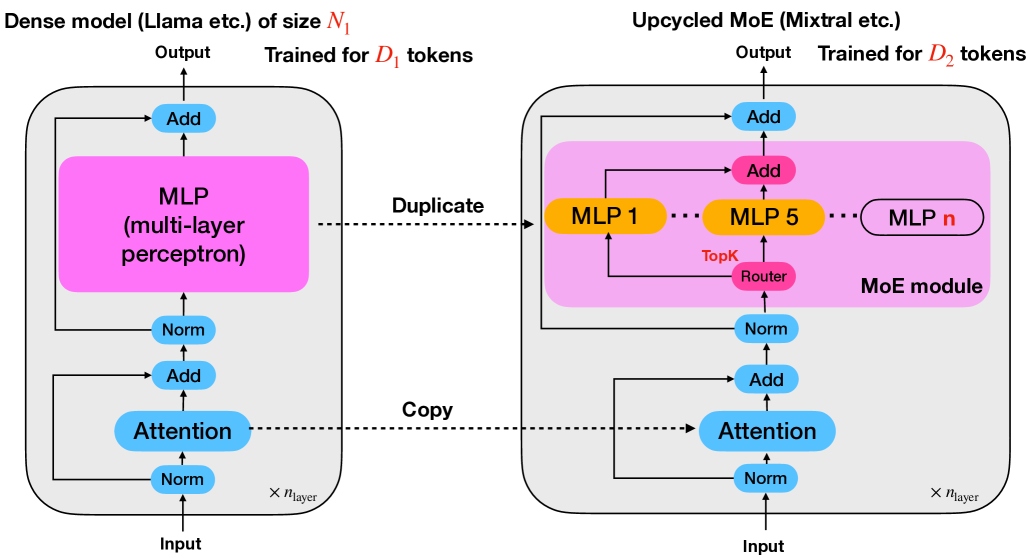
问题定义:论文旨在解决大型语言模型(LLM)训练过程中计算资源消耗巨大的问题。现有方法,如从头开始训练大型模型,成本高昂且耗时。Upcycling和MoE模型是降低成本的有效手段,但如何有效地将LLM upcycling到MoE模型,以及这种upcycling的扩展规律尚不明确,限制了其应用。
核心思路:论文的核心思路是通过实验研究,揭示Upcycling MoE模型的扩展规律,即性能如何随数据集大小和模型配置变化。通过分析实验数据,找出影响Upcycling效率的关键因素,并据此提出指导原则,优化Upcycling过程,使其在特定条件下优于从头训练。
技术框架:论文的技术框架主要包括以下几个部分:首先,选择合适的LLM作为基础模型;其次,构建MoE模型,并设计Upcycling训练策略;然后,进行大规模实验,改变数据集大小和模型配置,记录性能指标;最后,分析实验数据,建立经验扩展规律,并提出优化建议。整体流程是典型的实验驱动研究。
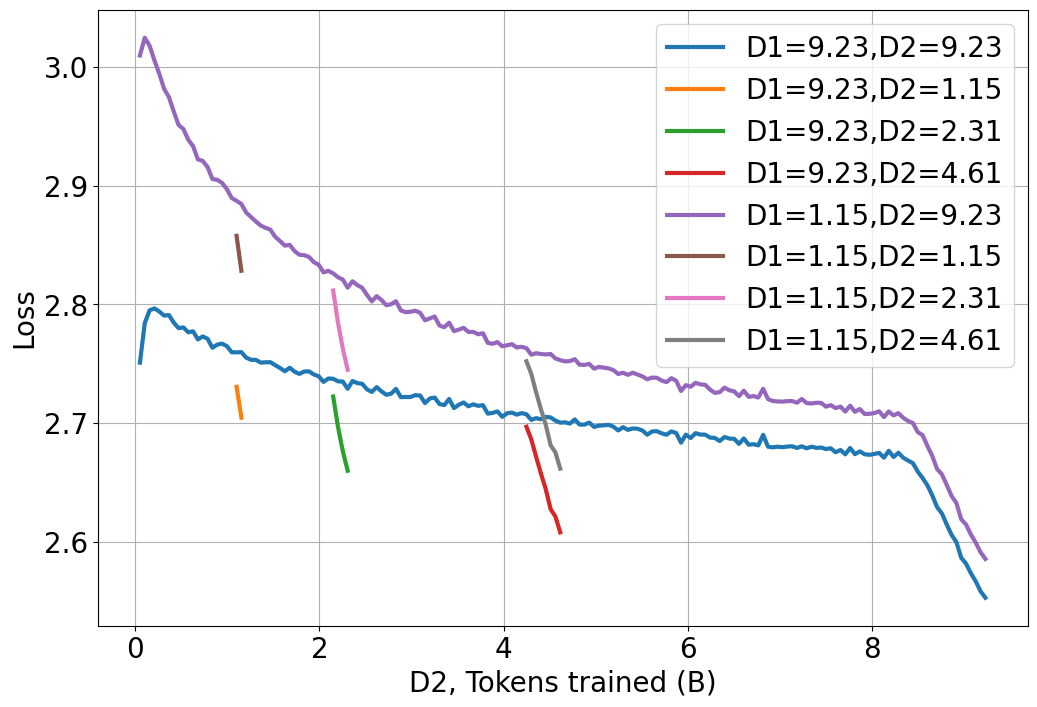
关键创新:论文的关键创新在于发现了密集数据集和Upcycling训练数据集之间存在一种新的交互作用,这种交互作用限制了在大型计算预算下Upcycling的效率。这是之前未被充分认识到的,为后续研究提供了新的视角。
关键设计:论文的关键设计包括:1) 精心设计的实验方案,覆盖了不同的数据集大小和模型配置;2) 细致的性能指标监控,能够准确反映Upcycling的效果;3) 对实验数据的深入分析,能够揭示隐藏的扩展规律。具体的参数设置、损失函数、网络结构等细节在论文中应该有详细描述,但摘要中未提及。
🖼️ 关键图片

📊 实验亮点
论文通过大量实验,揭示了Upcycling MoE模型的扩展规律,发现密集数据集和Upcycling训练数据集之间存在交互作用,限制了Upcycling效率。研究结果为Upcycling提供了指导,并确定了在预算约束下Upcycling优于从头训练的条件,具有重要的实际意义。
🎯 应用场景
该研究成果可应用于降低大型语言模型的训练成本,加速模型迭代和部署。通过Upcycling,可以更有效地利用现有模型,减少对计算资源的需求,推动LLM在资源受限环境下的应用,例如边缘计算设备或小型研究机构。
📄 摘要(原文)
Pretraining large language models (LLMs) is resource-intensive, often requiring months of training time even with high-end GPU clusters. There are two approaches of mitigating such computational demands: reusing smaller models to train larger ones (upcycling), and training computationally efficient models like mixture-of-experts (MoE). In this paper, we study the upcycling of LLMs to MoE models, of which the scaling behavior remains underexplored. Through extensive experiments, we identify empirical scaling laws that describe how performance depends on dataset size and model configuration. Particularly, we show that, while scaling these factors improves performance, there is a novel interaction term between the dense and upcycled training dataset that limits the efficiency of upcycling at large computational budgets. Based on these findings, we provide guidance to scale upcycling, and establish conditions under which upcycling outperforms from-scratch trainings within budget constraints.