Elucidating the Preconditioning in Consistency Distillation
作者: Kaiwen Zheng, Guande He, Jianfei Chen, Fan Bao, Jun Zhu
分类: cs.LG, cs.CV
发布日期: 2025-02-05 (更新: 2025-04-30)
备注: Accepted at ICLR 2025
💡 一句话要点
提出Analytic-Precond,通过解析优化预处理加速一致性蒸馏训练。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 一致性蒸馏 扩散模型 预处理 轨迹模型 解析优化 模型加速 生成模型
📋 核心要点
- 现有一致性蒸馏的预处理方法依赖手工设计,可能导致次优性能,限制了模型的训练效率和生成质量。
- 论文提出Analytic-Precond方法,通过解析优化预处理系数,缩小教师模型和学生模型之间的一致性差距。
- 实验结果表明,Analytic-Precond能够显著加速一致性轨迹模型的训练,并在多个数据集上实现2-3倍的加速效果。
📝 摘要(中文)
一致性蒸馏是加速扩散模型的一种常用方法,尤其是在一致性(轨迹)模型中。它训练一个学生模型,使其在由教师模型确定的概率流(PF)常微分方程(ODE)轨迹上反向传播。预处理是一种关键技术,通过使用预定义的系数线性组合输入数据和网络输出来稳定一致性蒸馏,以此作为一致性函数。它在不限制神经网络形式和表达能力的前提下,施加了一致性函数的边界条件。然而,先前的预处理方法是手工设计的,可能并非最优选择。本文首次从理论上深入研究了一致性蒸馏中的预处理,阐明了其设计标准以及与教师ODE轨迹的联系。基于这些分析,我们进一步提出了一种名为Analytic-Precond的原则性方法,用于根据广义教师ODE上的一致性差距(定义为教师去噪器和最优学生去噪器之间的差距)来解析地优化预处理。实验表明,Analytic-Precond可以促进轨迹跳跃器的学习,增强学生轨迹与教师轨迹的对齐,并在各种数据集的多步生成中实现一致性轨迹模型2倍至3倍的训练加速。
🔬 方法详解
问题定义:一致性蒸馏旨在加速扩散模型的训练,但现有方法中,预处理步骤依赖手工设计,缺乏理论指导,可能导致次优的训练效果和生成质量。核心问题是如何找到一种更有效、更具理论依据的预处理方法,以提高一致性蒸馏的效率和性能。
核心思路:论文的核心思路是通过解析优化预处理系数,使其能够最小化教师模型和学生模型之间的一致性差距。具体来说,就是根据广义教师ODE上的一致性差距,推导出最优的预处理系数,从而更好地对齐学生模型的轨迹与教师模型的轨迹。
技术框架:该方法主要包含以下几个阶段:1) 分析现有预处理方法的不足,并从理论上阐明预处理的设计标准;2) 基于广义教师ODE,定义一致性差距;3) 推导解析解,得到最优的预处理系数,即Analytic-Precond;4) 将Analytic-Precond应用于一致性蒸馏的训练过程中,加速学生模型的学习。
关键创新:论文最重要的技术创新在于提出了Analytic-Precond,一种基于解析优化的预处理方法。与现有手工设计的预处理方法不同,Analytic-Precond能够根据教师ODE和一致性差距,自动地调整预处理系数,从而更有效地对齐学生模型的轨迹与教师模型的轨迹。
关键设计:Analytic-Precond的关键设计在于如何根据一致性差距推导出最优的预处理系数。具体来说,论文首先定义了广义教师ODE,然后基于该ODE,推导出了教师去噪器和最优学生去噪器之间的差距。最后,通过最小化该差距,得到了预处理系数的解析解。此外,损失函数的设计也至关重要,需要能够有效地衡量学生模型和教师模型之间的一致性。
🖼️ 关键图片

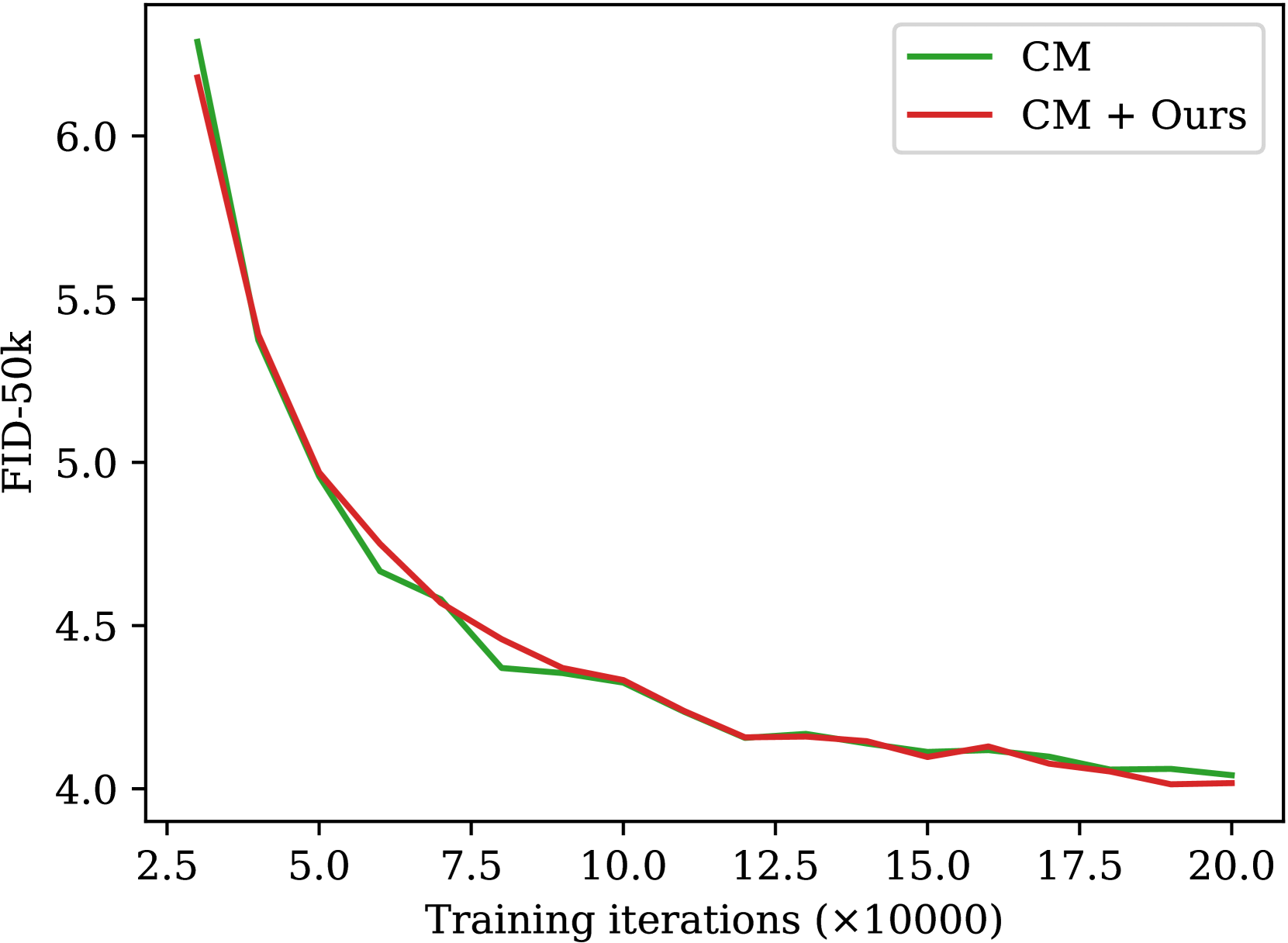
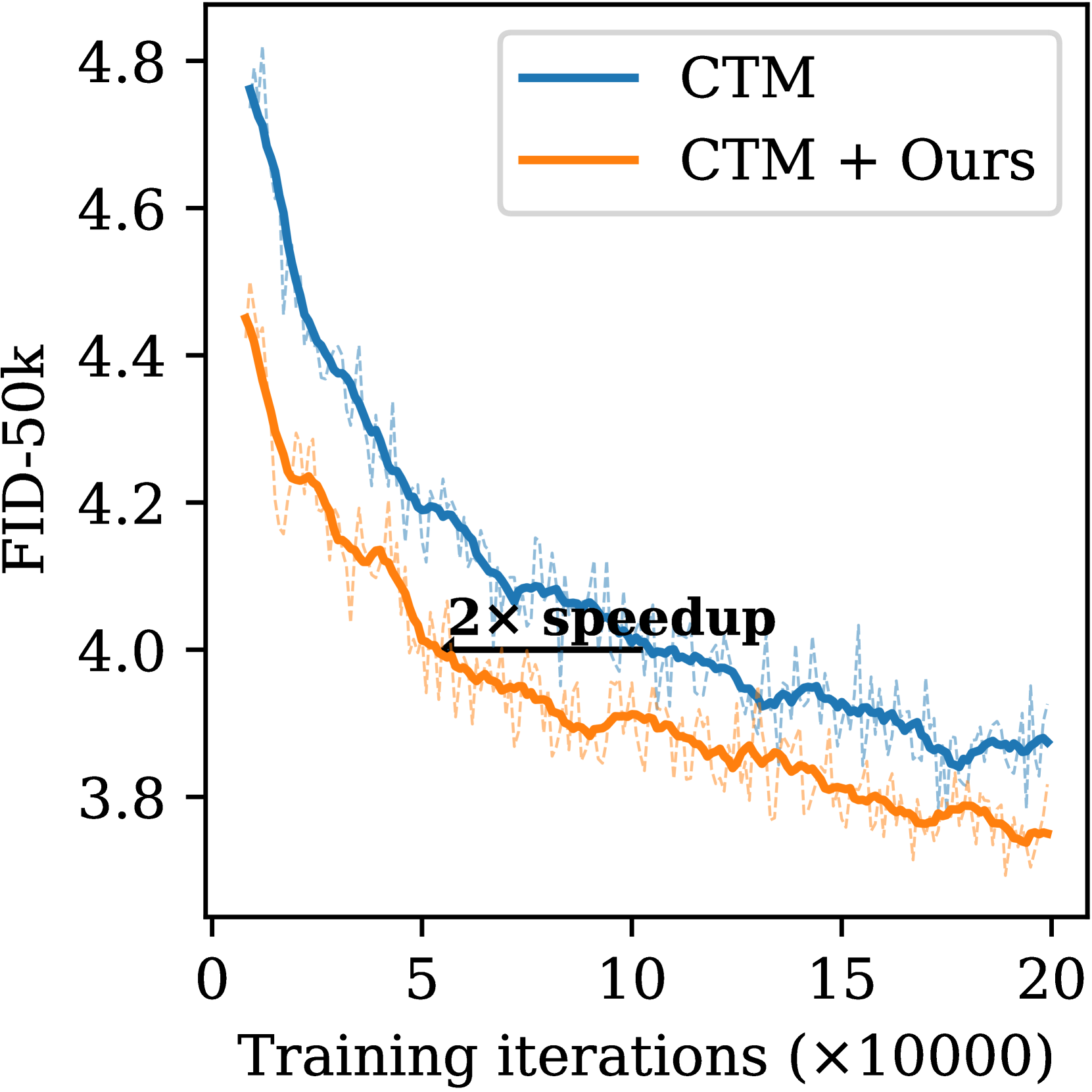
📊 实验亮点
实验结果表明,Analytic-Precond在多个数据集上实现了显著的性能提升。具体来说,与现有方法相比,Analytic-Precond能够将一致性轨迹模型的训练速度提高2倍至3倍,同时保持或提高生成样本的质量。这表明Analytic-Precond是一种有效的预处理方法,能够显著加速一致性蒸馏的训练过程。
🎯 应用场景
该研究成果可广泛应用于图像生成、音频合成等领域,尤其是在需要快速生成高质量样本的场景下。通过加速一致性蒸馏的训练过程,可以降低计算成本,提高生成效率,并有望推动相关应用的发展,例如实时图像编辑、快速原型设计等。
📄 摘要(原文)
Consistency distillation is a prevalent way for accelerating diffusion models adopted in consistency (trajectory) models, in which a student model is trained to traverse backward on the probability flow (PF) ordinary differential equation (ODE) trajectory determined by the teacher model. Preconditioning is a vital technique for stabilizing consistency distillation, by linear combining the input data and the network output with pre-defined coefficients as the consistency function. It imposes the boundary condition of consistency functions without restricting the form and expressiveness of the neural network. However, previous preconditionings are hand-crafted and may be suboptimal choices. In this work, we offer the first theoretical insights into the preconditioning in consistency distillation, by elucidating its design criteria and the connection to the teacher ODE trajectory. Based on these analyses, we further propose a principled way dubbed \textit{Analytic-Precond} to analytically optimize the preconditioning according to the consistency gap (defined as the gap between the teacher denoiser and the optimal student denoiser) on a generalized teacher ODE. We demonstrate that Analytic-Precond can facilitate the learning of trajectory jumpers, enhance the alignment of the student trajectory with the teacher's, and achieve $2\times$ to $3\times$ training acceleration of consistency trajectory models in multi-step generation across various datasets.