Towards Large-Scale In-Context Reinforcement Learning by Meta-Training in Randomized Worlds
作者: Fan Wang, Pengtao Shao, Yiming Zhang, Bo Yu, Shaoshan Liu, Ning Ding, Yang Cao, Yu Kang, Haifeng Wang
分类: cs.LG, cs.AI
发布日期: 2025-02-05 (更新: 2025-11-03)
备注: NeruIPS 2025
💡 一句话要点
提出AnyMDP及解耦策略蒸馏,实现大规模上下文强化学习的元训练
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 上下文强化学习 元学习 任务生成 策略蒸馏 泛化能力
📋 核心要点
- 上下文强化学习(ICRL)缺乏可扩展的任务集合,限制了其应用范围和性能。
- 提出AnyMDP,一种程序化生成的表格型MDP,以及解耦策略蒸馏方法,提升ICRL的元训练效率。
- 实验证明,该模型能够泛化到训练集中未见过的任务,并深入研究了数据分布与ICRL性能的关系。
📝 摘要(中文)
本文提出了一种可程序化生成表格型马尔可夫决策过程(MDP)的方法,称为AnyMDP,旨在解决上下文强化学习(ICRL)扩展性不足的问题。AnyMDP通过精心设计的随机化过程,能够大规模生成高质量的任务,同时保持较低的结构性偏差。为了促进大规模高效的元训练,本文进一步引入了解耦策略蒸馏,并在ICRL框架中引入先验信息。实验结果表明,通过足够大规模的AnyMDP任务,所提出的模型可以通过通用的上下文学习范式泛化到训练集中未考虑的任务。AnyMDP提供的可扩展任务集还能够更彻底地实证研究数据分布与ICRL性能之间的关系。研究还表明,ICRL的泛化能力可能会以增加任务多样性和延长适应期为代价。这一发现对扩展鲁棒的ICRL能力具有重要意义,突出了多样化和广泛的任务设计,以及优先考虑渐近性能而非少样本适应的必要性。
🔬 方法详解
问题定义:ICRL旨在使智能体能够从交互经验中自动且即时地学习,但其扩展性的主要挑战在于缺乏可扩展的任务集合。现有方法难以生成足够多样且高质量的任务,限制了ICRL的泛化能力和实际应用。
核心思路:本文的核心思路是通过程序化生成大规模、多样化的任务集合AnyMDP,并结合解耦策略蒸馏,来提升ICRL的元训练效率和泛化能力。AnyMDP的设计旨在降低结构性偏差,保证任务质量,而解耦策略蒸馏则用于加速训练过程,并引入先验知识。
技术框架:整体框架包含AnyMDP任务生成器、ICRL模型和解耦策略蒸馏模块。AnyMDP负责生成大规模的训练任务;ICRL模型利用上下文信息进行策略学习;解耦策略蒸馏模块则将策略学习分解为两个阶段:首先学习一个通用的策略,然后通过蒸馏将其迁移到特定任务。
关键创新:本文的关键创新在于AnyMDP任务生成器和解耦策略蒸馏方法。AnyMDP能够生成大规模、多样化且高质量的任务,为ICRL的元训练提供了充足的数据。解耦策略蒸馏则通过引入先验知识和加速训练过程,提升了ICRL的效率和泛化能力。与现有方法相比,AnyMDP能够生成更具多样性的任务,而解耦策略蒸馏则能够更有效地利用这些任务进行训练。
关键设计:AnyMDP的关键设计在于其随机化过程,包括状态空间大小、奖励函数、转移概率等参数的随机化。解耦策略蒸馏的关键设计在于损失函数的设计,包括策略蒸馏损失和行为克隆损失。此外,网络结构的设计也至关重要,需要能够有效地处理上下文信息,并学习到通用的策略。
🖼️ 关键图片
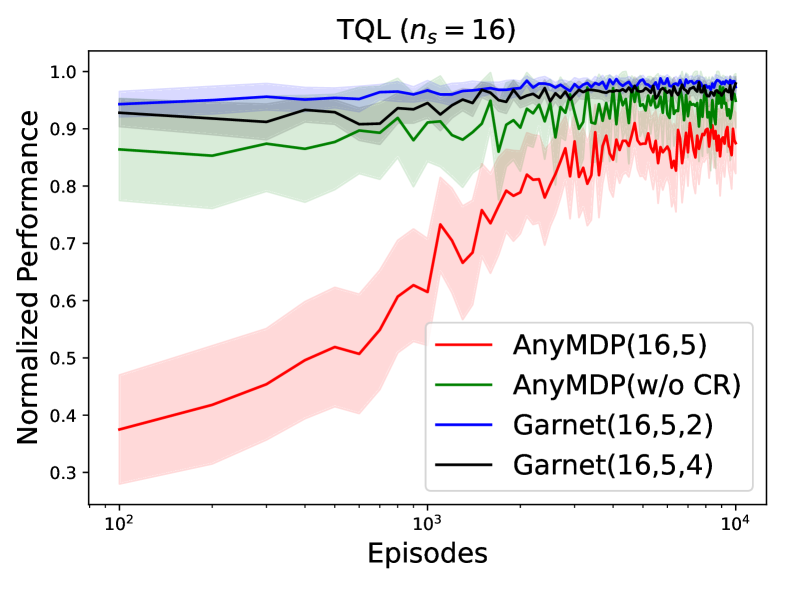
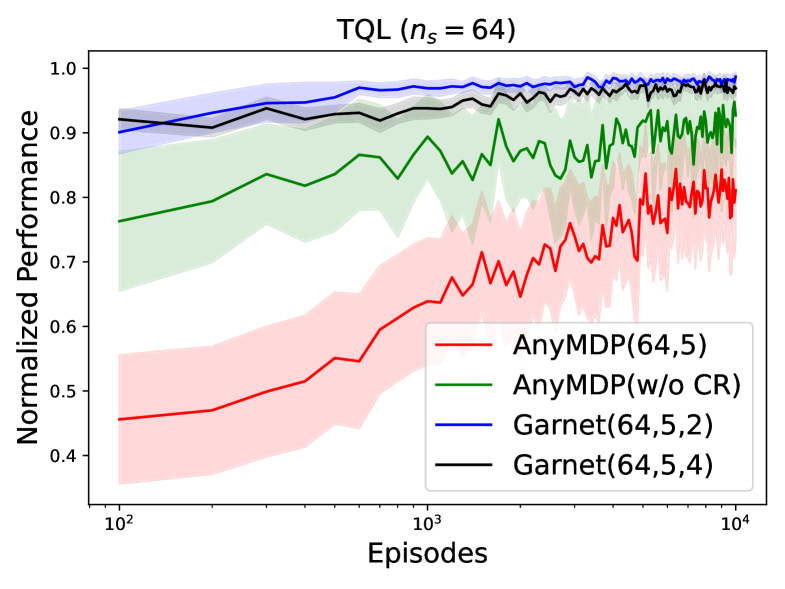

📊 实验亮点
实验结果表明,通过AnyMDP生成的大规模任务集合进行训练,ICRL模型能够泛化到训练集中未见过的任务。研究还发现,ICRL的泛化能力可能会以增加任务多样性和延长适应期为代价,这为未来研究提供了重要的指导方向。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、推荐系统等领域。通过AnyMDP生成的大规模任务集合,可以训练出更具泛化能力的ICRL智能体,使其能够快速适应新的环境和任务。这对于需要快速部署和适应的实际应用场景具有重要价值,并有望推动强化学习在更广泛领域的应用。
📄 摘要(原文)
In-Context Reinforcement Learning (ICRL) enables agents to learn automatically and on-the-fly from their interactive experiences. However, a major challenge in scaling up ICRL is the lack of scalable task collections. To address this, we propose the procedurally generated tabular Markov Decision Processes, named AnyMDP. Through a carefully designed randomization process, AnyMDP is capable of generating high-quality tasks on a large scale while maintaining relatively low structural biases. To facilitate efficient meta-training at scale, we further introduce decoupled policy distillation and induce prior information in the ICRL framework. Our results demonstrate that, with a sufficiently large scale of AnyMDP tasks, the proposed model can generalize to tasks that were not considered in the training set through versatile in-context learning paradigms. The scalable task set provided by AnyMDP also enables a more thorough empirical investigation of the relationship between data distribution and ICRL performance. We further show that the generalization of ICRL potentially comes at the cost of increased task diversity and longer adaptation periods. This finding carries critical implications for scaling robust ICRL capabilities, highlighting the necessity of diverse and extensive task design, and prioritizing asymptotic performance over few-shot adaptation.