Leveraging the true depth of LLMs
作者: Ramón Calvo González, Daniele Paliotta, Matteo Pagliardini, Martin Jaggi, François Fleuret
分类: cs.LG, cs.CL
发布日期: 2025-02-05 (更新: 2026-01-06)
💡 一句话要点
提出LLM层并行加速方法,无需重训练,显著提升推理吞吐量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 LLM推理 模型加速 层并行 计算图优化
📋 核心要点
- 现有LLM推理成本高昂,即使层剪枝等方法降低了计算量,也未能有效转化为推理速度的提升。
- 论文提出一种无需重训练的层并行方法,通过并行计算连续层对来重构计算图,从而加速推理过程。
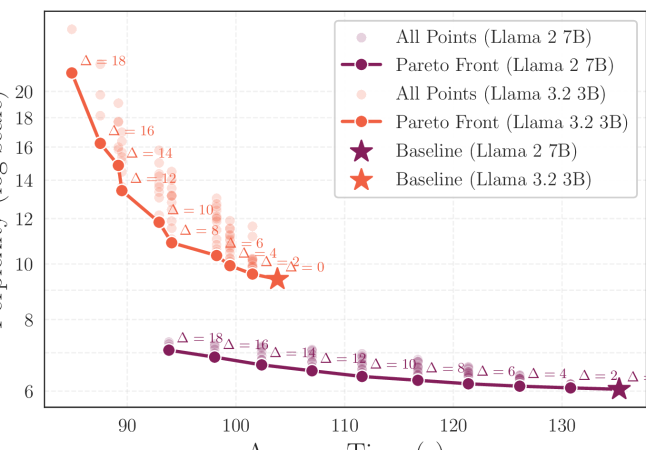
- 实验表明,该方法在Llama 2 7B模型上实现了1.19倍的吞吐量提升,精度损失仅为1.5%,且可通过微调恢复。
📝 摘要(中文)
大型语言模型(LLM)的强大能力因其巨大的计算成本而黯然失色。虽然最近的研究表明,许多LLM层可以重新排序甚至移除,而对准确性的影响最小,但这些见解尚未转化为显著的推理加速。为了弥合这一差距,我们提出了一种新的方法,通过并行分组和评估连续层对来重构计算图。这种方法不需要重新训练,在Llama 2 7B上实现了1.19倍的吞吐量增益,同时平均基准精度仅降低1.5%。我们证明了该方法在大规模LLM部署中的实际价值,并表明可以通过对并行化层进行轻量级微调来恢复部分损失的精度。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)推理速度慢,计算成本高昂。尽管已经有研究表明可以通过剪枝或重排LLM的层来降低计算量,但这些方法并没有有效地转化为实际推理速度的提升。现有的推理优化方法往往需要大量的工程优化或者模型重训练,成本较高。
核心思路:论文的核心思路是通过并行执行LLM中的连续层对来加速推理过程。通过将计算图重构为可以并行执行的结构,可以充分利用硬件资源,从而提高推理吞吐量。这种方法不需要对模型进行重新训练,因此可以快速部署到现有的LLM模型上。
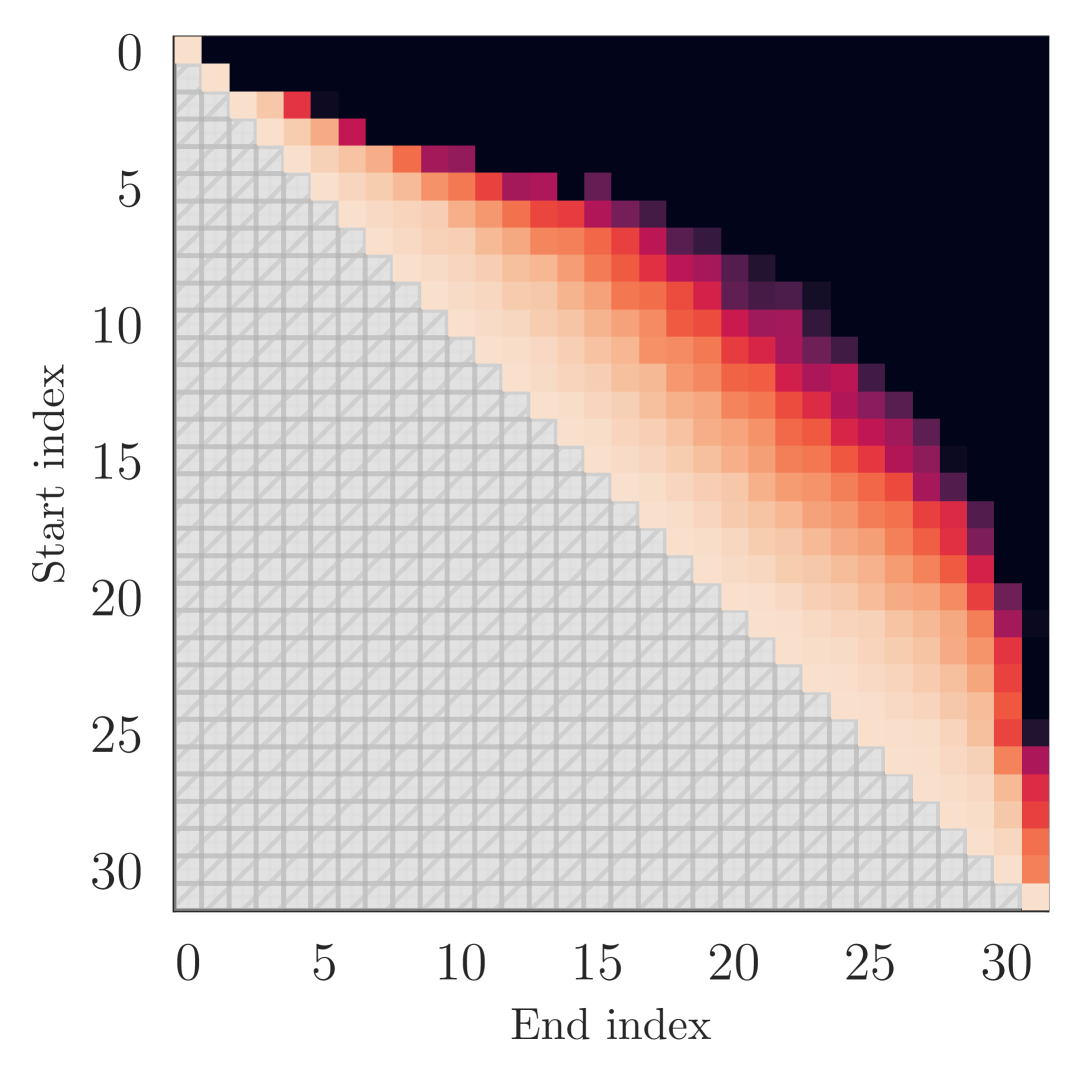
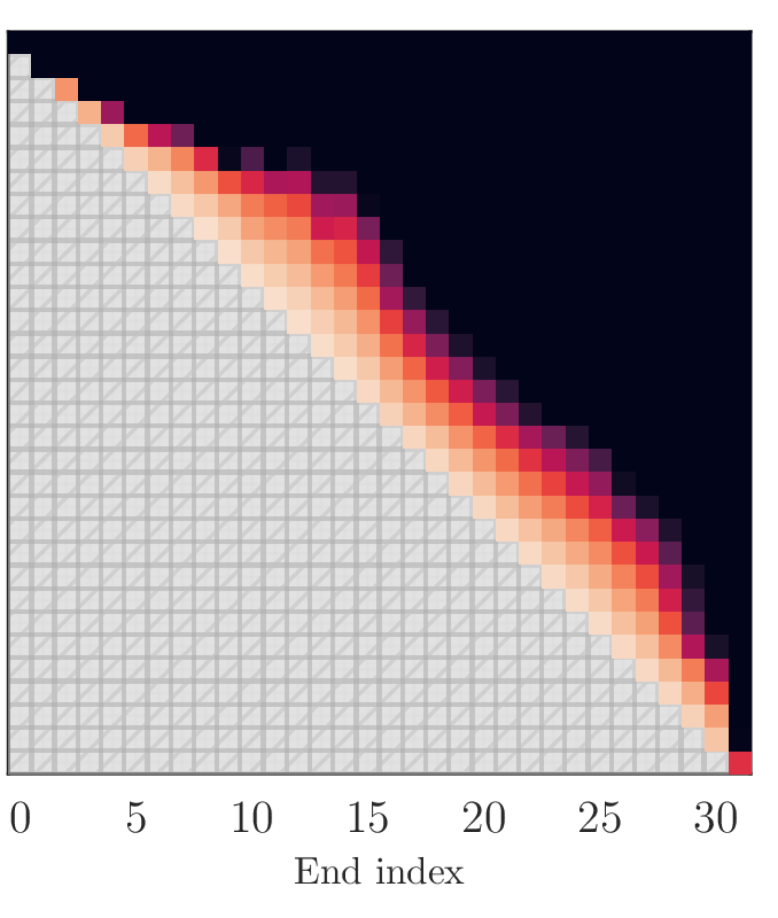
技术框架:该方法的核心在于将LLM的计算图进行重构,将连续的层两两分组,然后并行地执行这些层对。具体来说,假设LLM有N层,那么可以将这些层分成N/2个层对,每个层对包含两个连续的层。然后,使用并行计算资源同时执行这些层对。在执行完所有层对之后,将结果传递给下一组层对,直到完成整个LLM的推理过程。
关键创新:该方法最重要的创新点在于它能够在不重新训练模型的情况下,通过并行化层计算来显著提高LLM的推理速度。与现有的需要大量工程优化或模型重训练的方法相比,该方法更加简单高效,并且可以快速部署到现有的LLM模型上。
关键设计:该方法的关键设计在于如何选择合适的层对进行并行化,以及如何处理层之间的依赖关系。论文中采用了一种简单的策略,即直接将连续的层两两分组。对于层之间的依赖关系,论文通过在并行计算之后进行同步来保证计算的正确性。此外,论文还提出了一种轻量级的微调方法,用于恢复由于并行化而损失的精度。具体的微调策略未知,论文中提到是对并行化的层进行微调。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在Llama 2 7B模型上实现了1.19倍的吞吐量提升,同时平均基准精度仅降低1.5%。通过对并行化层进行轻量级微调,可以恢复部分损失的精度。这些结果表明,该方法是一种有效且实用的LLM推理加速方法。
🎯 应用场景
该研究成果可广泛应用于大规模LLM的部署场景,例如在线对话系统、智能客服、文本生成等。通过提高LLM的推理速度,可以降低服务延迟,提升用户体验,并降低计算成本。该方法尤其适用于对延迟敏感的应用场景,例如实时翻译、语音识别等。未来,该方法可以进一步扩展到其他类型的深度学习模型,并与其他优化技术相结合,以实现更高的推理效率。
📄 摘要(原文)
The remarkable capabilities of Large Language Models (LLMs) are overshadowed by their immense computational cost. While recent work has shown that many LLM layers can be reordered or even removed with minimal impact on accuracy, these insights have not been translated into significant inference speedups. To bridge this gap, we introduce a novel method that restructures the computational graph by grouping and evaluating consecutive layer pairs in parallel. This approach, requiring no retraining, yields a 1.19x throughput gain on Llama 2 7B while reducing the average benchmark accuracy by only 1.5\%. We demonstrate the practical value of this method for large-scale LLM deployment and show that some of the lost accuracy can be recovered with lightweight fine-tuning of the parallelized layers.