Twilight: Adaptive Attention Sparsity with Hierarchical Top-$p$ Pruning
作者: Chaofan Lin, Jiaming Tang, Shuo Yang, Hanshuo Wang, Tian Tang, Boyu Tian, Ion Stoica, Song Han, Mingyu Gao
分类: cs.LG, cs.CL
发布日期: 2025-02-04 (更新: 2025-11-04)
备注: To appear on NeurIPS 2025 (spotlight)
💡 一句话要点
Twilight:利用分层Top-$p$剪枝实现自适应注意力稀疏化,加速长文本LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本LLM 注意力稀疏化 自适应预算 Top-$p$采样 推理加速
📋 核心要点
- 现有稀疏注意力方法采用固定预算,难以适应真实场景中精度和效率的动态需求。
- Twilight框架借鉴Top-$p$采样思想,为现有稀疏注意力算法引入自适应稀疏性,无需重新设计注意力机制。
- 实验表明,Twilight能显著减少冗余计算,在长文本LLM推理中实现显著加速。
📝 摘要(中文)
本文提出Twilight框架,旨在解决长文本大语言模型(LLM)中注意力稀疏化算法预算固定,难以适应真实场景动态变化的问题。现有稀疏注意力或键值(KV)缓存压缩算法通常采用固定预算,无法在精度和效率之间取得最佳平衡。研究发现,将Top-$p$采样(nucleus sampling)应用于稀疏注意力可以实现自适应预算。Twilight框架无需牺牲原有稀疏注意力算法的精度,即可为其带来自适应稀疏性。实验结果表明,Twilight能够自适应地剪枝高达98%的冗余token,从而在自注意力操作中实现15.4倍的加速,并在长文本LLM解码的端到端单token延迟中实现3.9倍的加速。
🔬 方法详解
问题定义:现有长文本LLM的稀疏注意力方法,例如各种稀疏注意力机制和KV缓存压缩技术,通常使用固定的计算预算。然而,在实际应用中,不同输入文本的重要性程度不同,所需的计算资源也应有所差异。固定预算的稀疏化方法无法根据输入动态调整,导致要么精度不足,要么效率不高。因此,如何实现自适应的注意力稀疏化是本文要解决的关键问题。
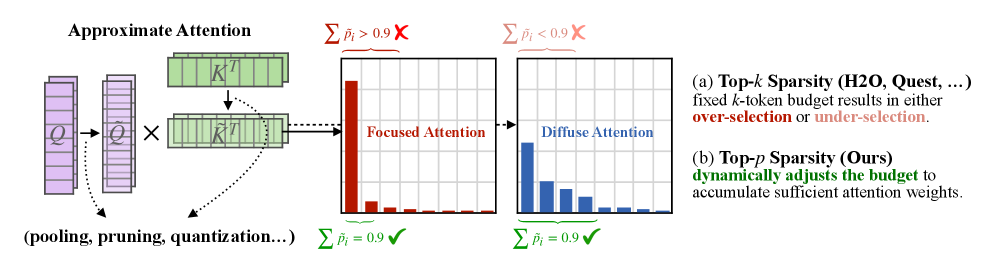
核心思路:本文的核心思路是将Top-$p$采样(nucleus sampling)的思想引入到稀疏注意力中。Top-$p$采样根据概率分布动态选择token,从而实现自适应的token选择。类似地,Twilight框架利用分层Top-$p$剪枝,自适应地选择需要保留的token,从而实现自适应的注意力稀疏化。这种方法允许模型根据输入的重要性程度,动态调整计算预算,在精度和效率之间取得更好的平衡。
技术框架:Twilight框架可以集成到任何现有的稀疏注意力算法中。其主要流程如下:1) 首先,使用现有的稀疏注意力算法计算每个token的重要性得分。2) 然后,使用分层Top-$p$剪枝算法,根据重要性得分自适应地选择需要保留的token。3) 最后,只对保留的token进行后续的注意力计算。分层Top-$p$剪枝包含多个层级,每个层级使用不同的$p$值,从而实现更精细的控制。
关键创新:Twilight的关键创新在于将Top-$p$采样思想引入到稀疏注意力中,从而实现了自适应的注意力稀疏化。与现有方法相比,Twilight不需要重新设计注意力机制,而是可以集成到任何现有的稀疏注意力算法中。此外,分层Top-$p$剪枝算法允许模型根据输入的重要性程度,动态调整计算预算,从而在精度和效率之间取得更好的平衡。
关键设计:Twilight框架的关键设计在于分层Top-$p$剪枝算法。该算法包含多个层级,每个层级使用不同的$p$值。例如,第一层级可以使用较大的$p$值,保留大部分token,而后续层级可以使用较小的$p$值,进一步剪枝冗余token。$p$值的选择可以根据实际情况进行调整,以达到最佳的精度和效率平衡。此外,Twilight框架还可以使用不同的重要性得分计算方法,例如注意力权重或梯度。
🖼️ 关键图片
📊 实验亮点
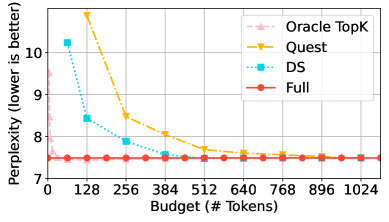
实验结果表明,Twilight框架能够自适应地剪枝高达98%的冗余token,从而在自注意力操作中实现15.4倍的加速,并在长文本LLM解码的端到端单token延迟中实现3.9倍的加速。这些结果表明,Twilight框架能够显著提高长文本LLM的推理效率,同时保持较高的精度。
🎯 应用场景
Twilight框架可广泛应用于需要处理长文本的大语言模型场景,例如文档摘要、机器翻译、对话系统等。通过自适应地减少冗余计算,Twilight可以显著降低计算成本,提高推理速度,从而使得长文本LLM能够更高效地部署在资源受限的设备上,并支持更大规模的应用。
📄 摘要(原文)
Leveraging attention sparsity to accelerate long-context large language models (LLMs) has been a hot research topic. However, current algorithms such as sparse attention or key-value (KV) cache compression tend to use a fixed budget, which presents a significant challenge during deployment because it fails to account for the dynamic nature of real-world scenarios, where the optimal balance between accuracy and efficiency can vary greatly. In this paper, we find that borrowing top-$p$ sampling (nucleus sampling) to sparse attention can surprisingly achieve adaptive budgeting. Based on this, we propose Twilight, a framework to bring adaptive sparsity to any existing sparse attention algorithm without sacrificing their accuracy. Empirical results show that Twilight can adaptively prune at most 98% of redundant tokens, leading to $15.4\times$ acceleration in self-attention operations and $3.9\times$ acceleration in end-to-end per token latency in long context LLM decoding.