A Unified Understanding and Evaluation of Steering Methods
作者: Shawn Im, Sharon Li
分类: cs.LG, cs.CL
发布日期: 2025-02-04 (更新: 2026-01-09)
💡 一句话要点
提出统一框架,分析并评估大语言模型中的隐空间操控方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 隐空间操控 可控生成 文本生成 模型评估
📋 核心要点
- 现有隐空间操控方法缺乏统一的理解和评估标准,难以比较和优化不同方法。
- 论文提出了一个统一的分析和评估框架,形式化了隐空间操控的核心原则,并提供了理论见解。
- 通过实验验证了理论见解,确定了影响性能的关键因素,并展示了特定方法的优越性。
📝 摘要(中文)
隐空间操控方法通过将操控向量应用于中间激活层来控制大型语言模型,从而引导输出到期望的行为,而无需重新训练,这是一种实用的方法。尽管它们的重要性日益增加,但该领域缺乏跨任务和数据集的统一理解和一致评估,阻碍了进展。本文介绍了一个统一的框架,用于分析和评估操控方法,形式化了它们的核心原则,并提供了对其有效性的理论见解。通过对多项选择和开放式文本生成任务的全面实证评估,我们验证了这些见解,确定了影响性能的关键因素,并证明了某些方法的优越性。我们的工作弥合了理论和实践的视角,为推进LLM中隐空间操控方法的设计、优化和部署提供了可操作的指导。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中隐空间操控方法缺乏统一理解和评估标准的问题。现有方法在不同任务和数据集上的表现不一致,难以进行有效比较和优化。这阻碍了该领域的发展,并使得选择和应用合适的操控方法变得困难。
核心思路:论文的核心思路是构建一个统一的框架,用于分析和评估不同的隐空间操控方法。该框架形式化了这些方法的核心原则,并提供了对其有效性的理论解释。通过统一的评估标准,可以更好地理解不同方法的优缺点,并指导其设计和优化。
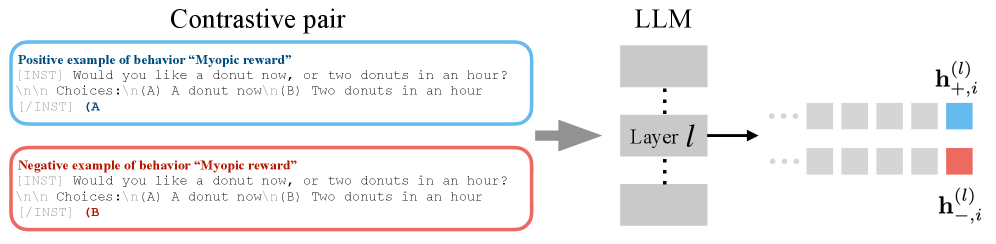
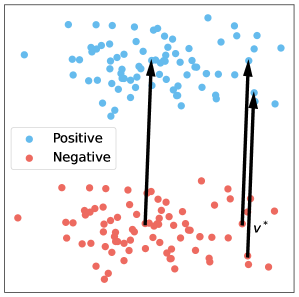
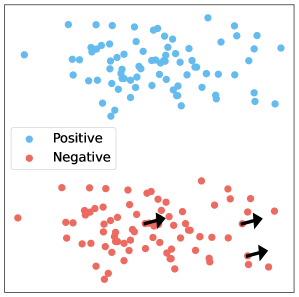
技术框架:论文提出的框架主要包含以下几个阶段:1) 形式化隐空间操控的核心原则,例如操控向量的构建和应用方式。2) 基于形式化的原则,建立统一的评估指标,用于衡量不同方法在不同任务上的性能。3) 通过实验验证理论见解,并分析影响性能的关键因素。4) 基于分析结果,提出改进现有方法的建议。
关键创新:论文的关键创新在于提出了一个统一的框架,将不同的隐空间操控方法置于同一理论框架下进行分析和评估。这使得研究者可以更清晰地理解这些方法的本质,并进行更有效的比较和优化。此外,论文还提供了对这些方法有效性的理论见解,有助于指导其设计和应用。
关键设计:论文的关键设计包括:1) 对隐空间操控方法进行形式化描述,明确其核心组成部分和操作流程。2) 设计了一系列评估指标,用于衡量不同方法在不同任务上的性能,例如准确率、流畅度和一致性。3) 通过实验验证了理论见解,并分析了影响性能的关键因素,例如操控向量的维度、学习率和正则化参数。
🖼️ 关键图片
📊 实验亮点
论文通过在多项选择和开放式文本生成任务上的实验,验证了所提出的统一框架的有效性。实验结果表明,某些隐空间操控方法在特定任务上表现出优越性,并且论文还确定了影响性能的关键因素,例如操控向量的维度和学习率。这些发现为改进现有方法提供了有价值的指导。
🎯 应用场景
该研究成果可应用于各种需要控制LLM行为的场景,例如:生成特定风格的文本、引导模型输出特定观点、避免模型生成有害内容等。该研究有助于提升LLM的可控性和安全性,促进其在各个领域的应用。
📄 摘要(原文)
Latent space steering methods provide a practical approach to controlling large language models by applying steering vectors to intermediate activations, guiding outputs toward desired behaviors while avoiding retraining. Despite their growing importance, the field lacks a unified understanding and consistent evaluation across tasks and datasets, hindering progress. This paper introduces a unified framework for analyzing and evaluating steering methods, formalizing their core principles and offering theoretical insights into their effectiveness. Through comprehensive empirical evaluations on multiple-choice and open-ended text generation tasks, we validate these insights, identifying key factors that influence performance and demonstrating the superiority of certain methods. Our work bridges theoretical and practical perspectives, offering actionable guidance for advancing the design, optimization, and deployment of latent space steering methods in LLMs.