On Teacher Hacking in Language Model Distillation
作者: Daniil Tiapkin, Daniele Calandriello, Johan Ferret, Sarah Perrin, Nino Vieillard, Alexandre Ramé, Mathieu Blondel
分类: cs.LG, cs.AI, cs.CL, stat.ML
发布日期: 2025-02-04
💡 一句话要点
研究知识蒸馏中的“教师黑客”现象,揭示数据多样性对模型泛化的影响
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 语言模型 教师黑客 数据多样性 模型泛化
📋 核心要点
- 现有语言模型蒸馏方法可能导致学生模型过度拟合教师模型的缺陷,即“教师黑客”现象。
- 论文提出通过增加训练数据的多样性来缓解教师黑客现象,从而提升学生模型的泛化能力。
- 实验表明,使用在线数据生成策略可以有效降低“教师黑客”风险,并改善学生模型的性能。
📝 摘要(中文)
本文研究了语言模型(LM)知识蒸馏中一种名为“教师黑客”的现象。该现象类似于强化学习中的奖励黑客,即学生模型过度优化教师模型的缺陷,导致在真实目标上的性能下降。为了研究这一现象,作者设计了一个受控实验环境,包含:(i) 代表真实分布的oracle LM,(ii) 从oracle LM蒸馏得到的教师LM,以及 (iii) 从教师LM蒸馏得到的学生LM。实验结果表明,使用固定的离线数据集进行蒸馏时,会发生教师黑客现象,并且可以通过观察优化过程偏离多项式收敛规律来检测它。相反,采用在线数据生成技术可以有效缓解教师黑客现象。更准确地说,数据多样性是防止黑客攻击的关键因素。总的来说,这项研究更深入地理解了蒸馏在构建鲁棒和高效LM方面的优势和局限性。
🔬 方法详解
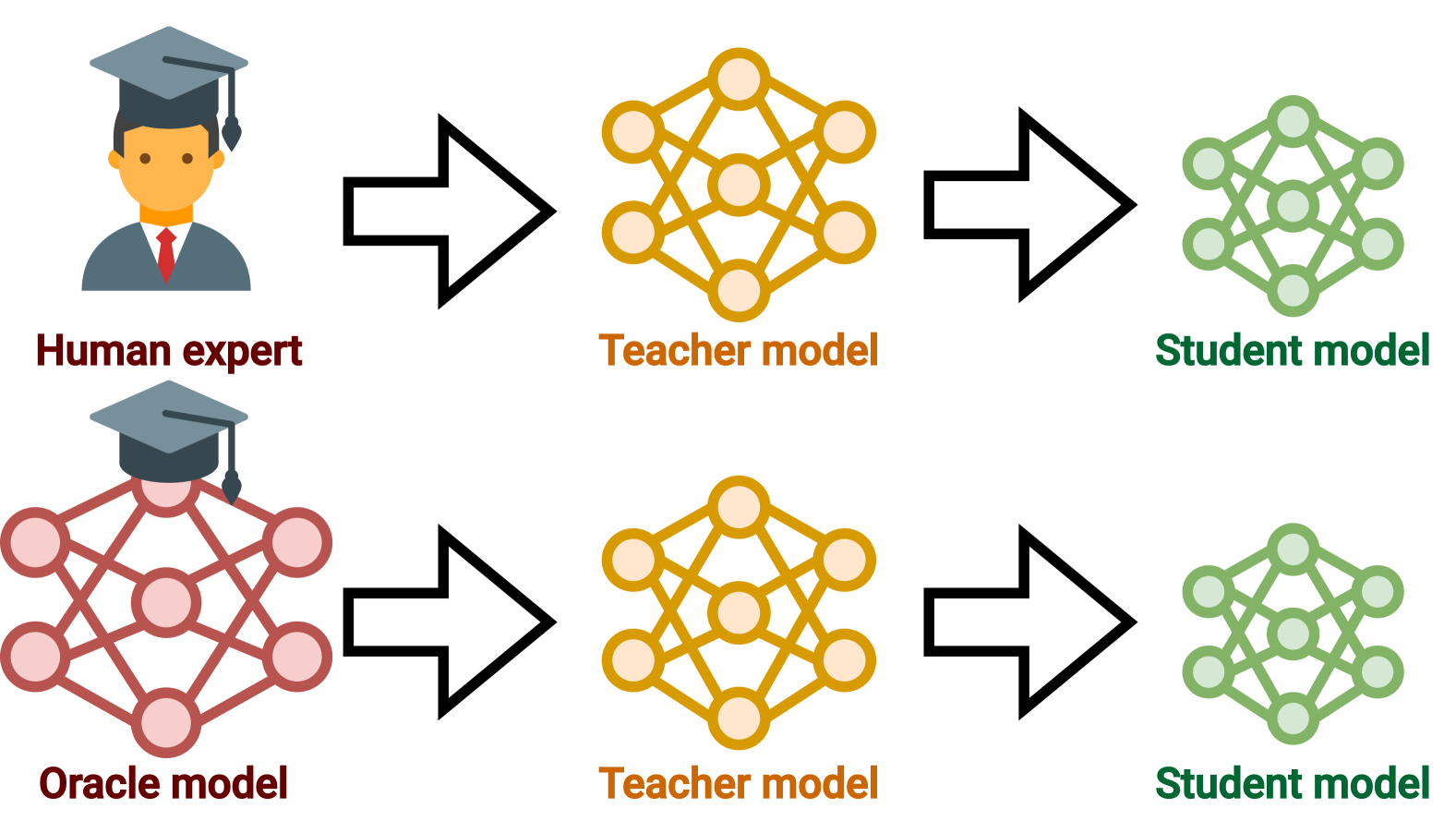
问题定义:论文旨在研究知识蒸馏过程中,学生模型是否会过度拟合教师模型的偏差,从而在真实分布上表现不佳,即“教师黑客”现象。现有方法在蒸馏过程中,往往忽略了教师模型本身可能存在的缺陷,导致学生模型学习到错误的知识。
核心思路:论文的核心思路是通过控制实验环境,模拟知识蒸馏过程,并观察学生模型的学习行为。通过对比不同数据生成策略下的蒸馏效果,分析“教师黑客”现象产生的原因,并提出缓解策略。核心在于增加训练数据的多样性,避免学生模型过度依赖教师模型的特定偏差。
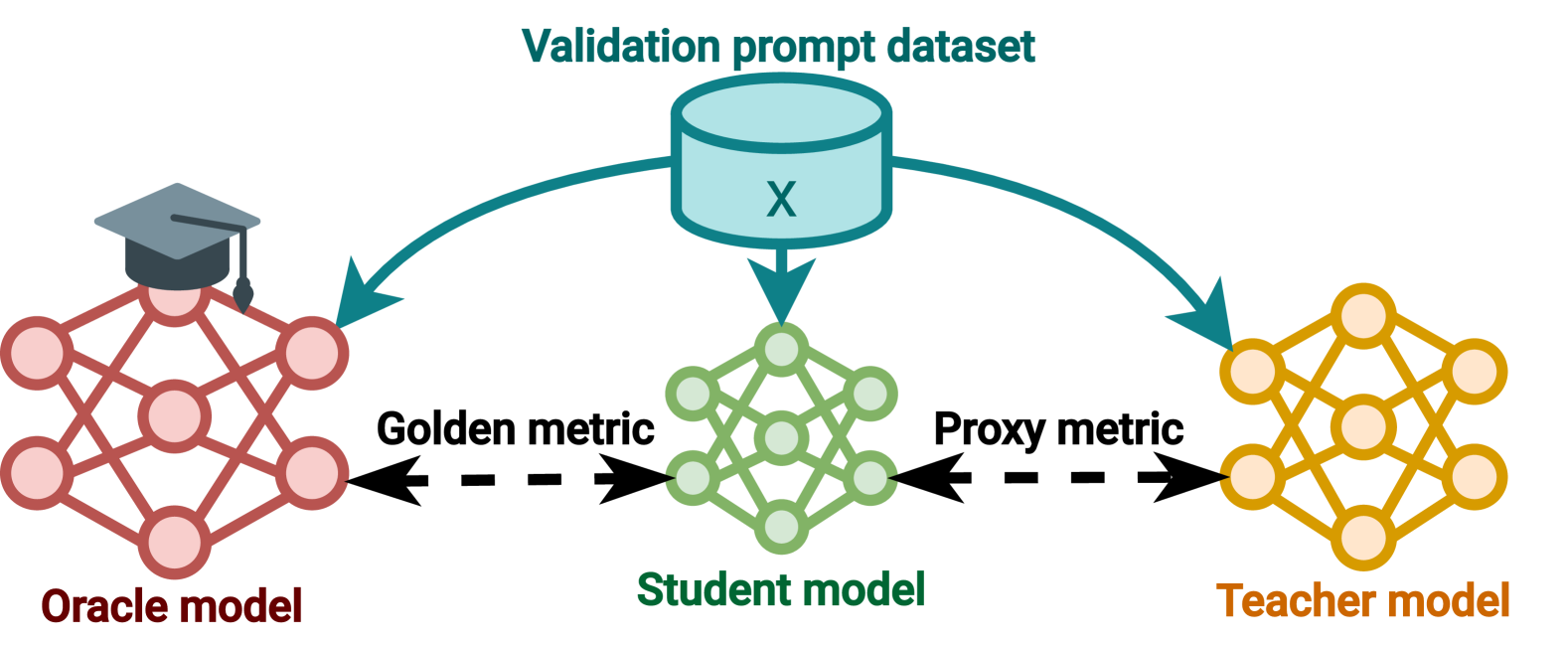
技术框架:论文构建了一个三阶段的实验框架:(1) Oracle LM:代表真实数据分布,作为理想的教师模型。(2) Teacher LM:通过从Oracle LM蒸馏得到,模拟实际应用中可能存在的有偏差的教师模型。(3) Student LM:通过从Teacher LM蒸馏得到,观察其学习行为,判断是否存在“教师黑客”现象。通过比较离线数据集和在线数据生成两种方式,研究数据多样性对蒸馏效果的影响。
关键创新:论文的关键创新在于首次提出了“教师黑客”这一概念,并设计实验验证了其存在。同时,论文强调了数据多样性在知识蒸馏中的重要性,并提出了通过在线数据生成来缓解“教师黑客”现象的策略。这为知识蒸馏的研究提供了新的视角。
关键设计:论文的关键设计包括:(1) 使用Oracle LM作为ground truth,方便评估学生模型的性能。(2) 对比离线数据集和在线数据生成两种数据策略,研究数据多样性的影响。(3) 通过观察优化过程的收敛速度,判断是否存在“教师黑客”现象。具体而言,如果优化过程偏离多项式收敛规律,则表明可能发生了“教师黑客”现象。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用固定的离线数据集进行蒸馏时,会发生教师黑客现象,并且可以通过观察优化过程偏离多项式收敛规律来检测它。相反,采用在线数据生成技术可以有效缓解教师黑客现象。数据多样性是防止黑客攻击的关键因素。
🎯 应用场景
该研究成果可应用于提升语言模型蒸馏的鲁棒性和泛化能力,尤其是在教师模型本身存在偏差的情况下。通过增加训练数据的多样性,可以有效避免学生模型过度拟合教师模型的缺陷,从而提高模型在真实场景中的性能。这对于构建可靠的、高效的语言模型具有重要意义。
📄 摘要(原文)
Post-training of language models (LMs) increasingly relies on the following two stages: (i) knowledge distillation, where the LM is trained to imitate a larger teacher LM, and (ii) reinforcement learning from human feedback (RLHF), where the LM is aligned by optimizing a reward model. In the second RLHF stage, a well-known challenge is reward hacking, where the LM over-optimizes the reward model. Such phenomenon is in line with Goodhart's law and can lead to degraded performance on the true objective. In this paper, we investigate whether a similar phenomenon, that we call teacher hacking, can occur during knowledge distillation. This could arise because the teacher LM is itself an imperfect approximation of the true distribution. To study this, we propose a controlled experimental setup involving: (i) an oracle LM representing the ground-truth distribution, (ii) a teacher LM distilled from the oracle, and (iii) a student LM distilled from the teacher. Our experiments reveal the following insights. When using a fixed offline dataset for distillation, teacher hacking occurs; moreover, we can detect it by observing when the optimization process deviates from polynomial convergence laws. In contrast, employing online data generation techniques effectively mitigates teacher hacking. More precisely, we identify data diversity as the key factor in preventing hacking. Overall, our findings provide a deeper understanding of the benefits and limitations of distillation for building robust and efficient LMs.