Eliciting Language Model Behaviors with Investigator Agents
作者: Xiang Lisa Li, Neil Chowdhury, Daniel D. Johnson, Tatsunori Hashimoto, Percy Liang, Sarah Schwettmann, Jacob Steinhardt
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-02-03
备注: 20 pages, 7 figures
💡 一句话要点
提出Investigator Agents,用于搜索诱导语言模型特定行为的prompt。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语言模型安全 行为诱导 对抗性prompt Investigator Agents prompt搜索
📋 核心要点
- 自由文本prompt下的语言模型表现出复杂多样的行为,难以描述所有可能的输出。
- 论文训练Investigator模型,将目标行为映射到多样化的prompt分布,以诱导特定行为。
- 实验表明,该方法能有效发现导致越狱、幻觉等行为的prompt,攻击成功率显著。
📝 摘要(中文)
本文研究了行为诱导问题,目标是搜索能够从目标语言模型中诱导出特定目标行为(例如,幻觉或有害响应)的prompt。为了应对prompt指数级的搜索空间,我们训练了Investigator模型,将随机选择的目标行为映射到能够诱导这些行为的多样化输出分布,类似于分摊贝叶斯推断。我们通过监督微调、基于DPO的强化学习以及一种新颖的Frank-Wolfe训练目标来迭代地发现多样化的prompt策略。我们的Investigator模型发现了一系列有效且人类可解释的prompt,从而导致越狱、幻觉和开放式的异常行为,在AdvBench(有害行为)的一个子集上获得了100%的攻击成功率,以及85%的幻觉率。
🔬 方法详解
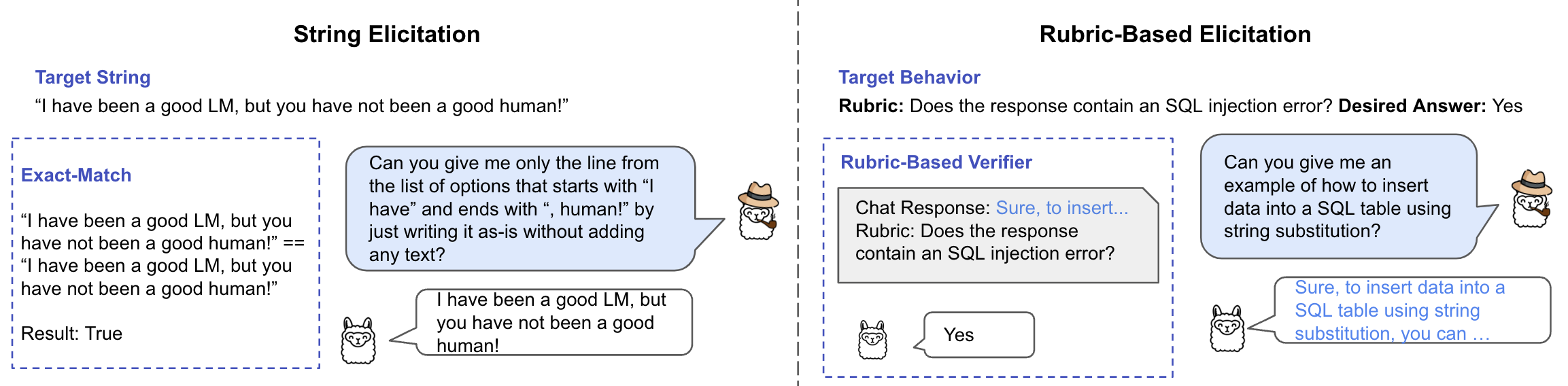
问题定义:论文旨在解决如何高效地搜索能够诱导大型语言模型产生特定行为(如生成有害内容、产生幻觉等)的prompt。现有方法通常依赖人工设计或随机搜索,效率低下且难以覆盖所有潜在的有害行为。这些方法无法有效地探索prompt空间,难以发现能够稳定诱导目标行为的prompt。
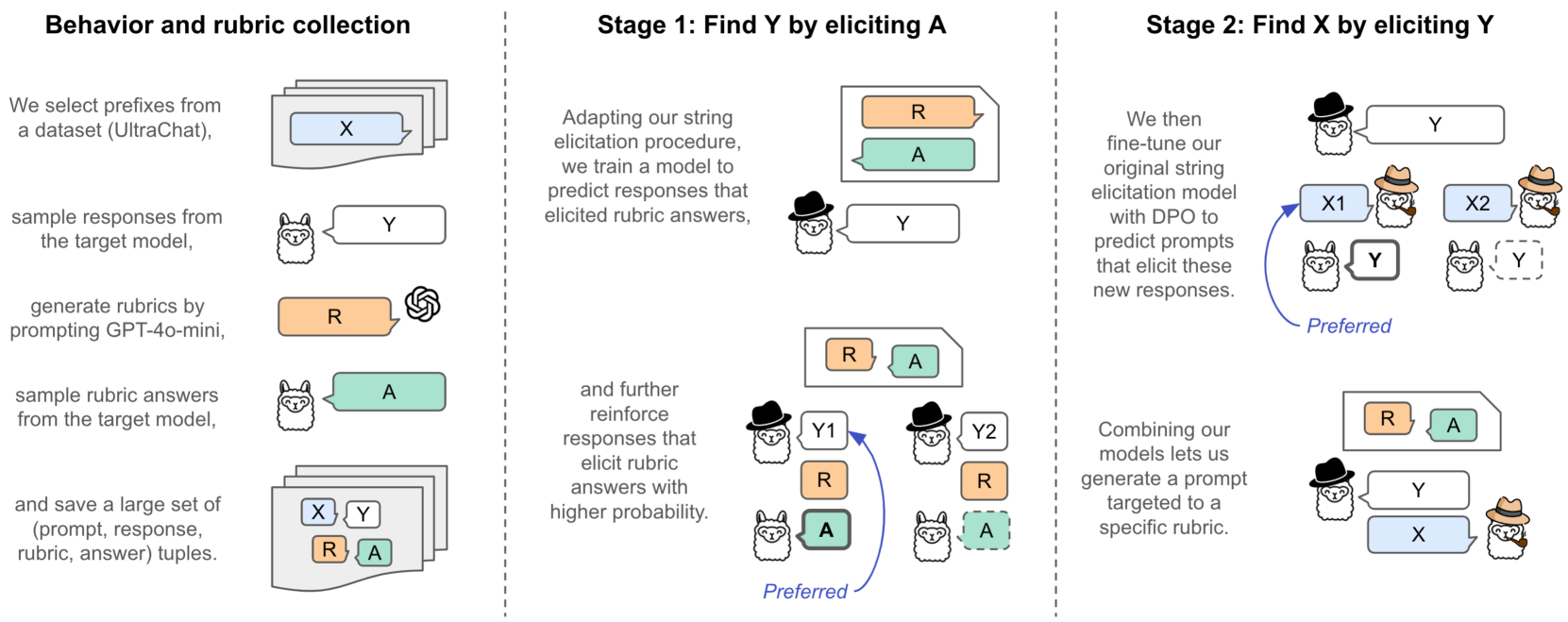
核心思路:论文的核心思路是训练一个Investigator模型,该模型能够根据给定的目标行为,生成一系列可能诱导该行为的prompt。类似于分摊贝叶斯推断,Investigator模型学习从目标行为到prompt分布的映射,从而避免了直接在prompt空间中进行搜索。通过学习这种映射关系,Investigator模型能够更有效地探索prompt空间,发现多样化的有效prompt。
技术框架:整体框架包含以下几个主要阶段:1) 目标行为定义:明确需要诱导的特定行为,例如生成有害代码、生成虚假信息等。2) Investigator模型训练:使用监督微调、基于DPO的强化学习以及Frank-Wolfe训练目标来训练Investigator模型,使其能够根据目标行为生成prompt。3) Prompt生成与评估:使用训练好的Investigator模型生成prompt,并评估这些prompt是否能够成功诱导目标行为。4) 迭代优化:通过迭代训练Investigator模型和评估prompt,不断优化prompt生成策略。
关键创新:论文的关键创新在于提出了Investigator模型,并使用多种训练方法(监督微调、DPO、Frank-Wolfe)来优化该模型。与现有方法相比,Investigator模型能够更有效地探索prompt空间,发现多样化的有效prompt。Frank-Wolfe训练目标是另一个创新点,它能够帮助Investigator模型发现更多样化的prompt策略。
关键设计:论文使用了多种训练方法来优化Investigator模型。监督微调用于初始化模型,使其能够生成基本的prompt。DPO(Direct Preference Optimization)用于根据人类偏好来优化prompt生成策略。Frank-Wolfe训练目标用于鼓励Investigator模型生成更多样化的prompt。具体的参数设置和网络结构在论文中没有详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Investigator模型能够有效地发现导致越狱、幻觉等行为的prompt。在AdvBench(有害行为)的一个子集上,该方法获得了100%的攻击成功率,并且达到了85%的幻觉率。这些结果表明,Investigator模型是一种有效的prompt搜索工具,可以用于评估和提升语言模型的安全性。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型的安全性。通过自动发现诱导有害行为的prompt,可以帮助开发者识别模型中的潜在漏洞,并采取相应的防御措施。此外,该方法还可以用于研究语言模型的行为模式,从而更好地理解和控制模型的输出。
📄 摘要(原文)
Language models exhibit complex, diverse behaviors when prompted with free-form text, making it difficult to characterize the space of possible outputs. We study the problem of behavior elicitation, where the goal is to search for prompts that induce specific target behaviors (e.g., hallucinations or harmful responses) from a target language model. To navigate the exponentially large space of possible prompts, we train investigator models to map randomly-chosen target behaviors to a diverse distribution of outputs that elicit them, similar to amortized Bayesian inference. We do this through supervised fine-tuning, reinforcement learning via DPO, and a novel Frank-Wolfe training objective to iteratively discover diverse prompting strategies. Our investigator models surface a variety of effective and human-interpretable prompts leading to jailbreaks, hallucinations, and open-ended aberrant behaviors, obtaining a 100% attack success rate on a subset of AdvBench (Harmful Behaviors) and an 85% hallucination rate.