On Almost Surely Safe Alignment of Large Language Models at Inference-Time
作者: Xiaotong Ji, Shyam Sundhar Ramesh, Matthieu Zimmer, Ilija Bogunovic, Jun Wang, Haitham Bou Ammar
分类: cs.LG, cs.CL
发布日期: 2025-02-03 (更新: 2025-06-20)
💡 一句话要点
提出InferenceGuard,在推理时实现大语言模型近乎完全的安全对齐
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 安全对齐 推理时对齐 约束MDP 强化学习
📋 核心要点
- 现有大语言模型对齐方法,如RLHF,计算资源消耗大,且容易过拟合,难以保证推理时的安全性。
- 论文提出InferenceGuard,将安全响应生成建模为约束MDP,在LLM潜在空间中动态惩罚不安全行为。
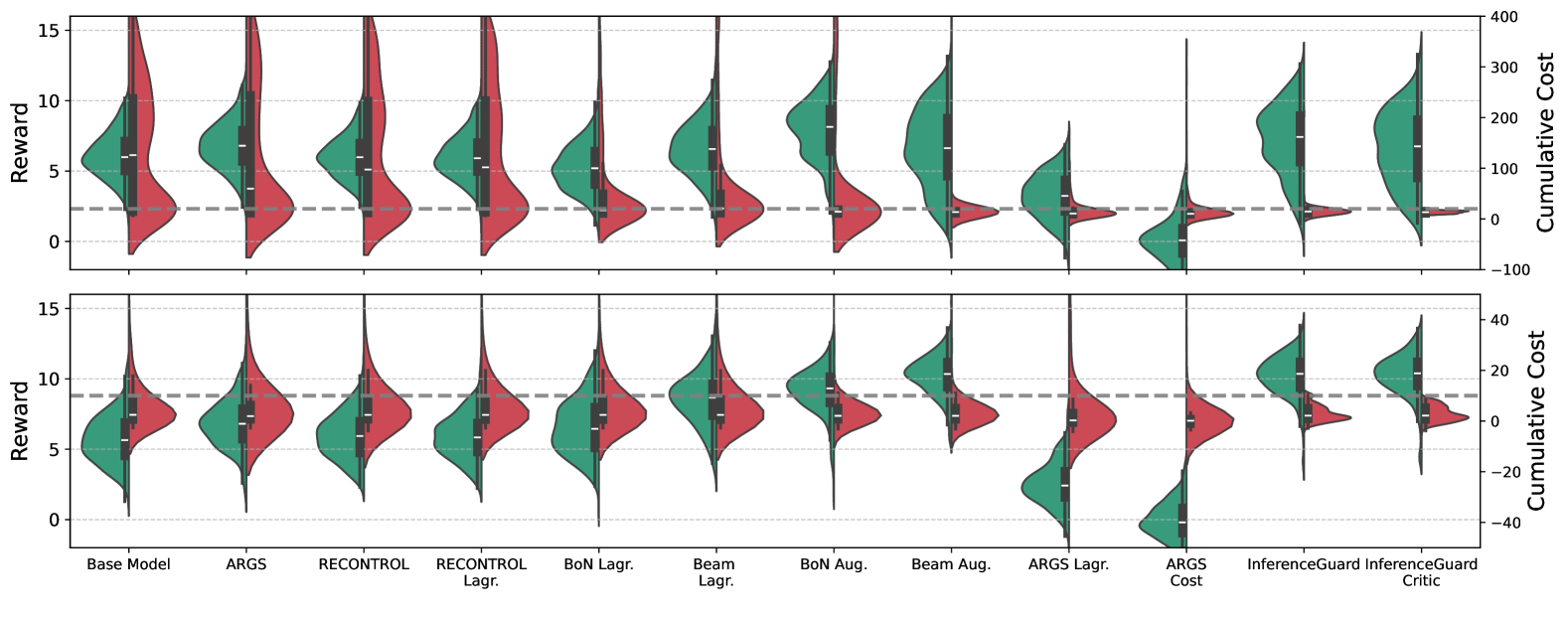
- 实验表明,InferenceGuard在保证安全性的同时,有效平衡了任务性能,优于现有推理时对齐方法。
📝 摘要(中文)
本文提出了一种新颖的LLM推理时对齐方法,旨在生成几乎完全安全的响应,即概率接近于1。该方法将安全响应的生成建模为LLM潜在空间中的约束马尔可夫决策过程(MDP)。通过引入一个安全状态来跟踪安全约束的演变,并动态惩罚不安全的生成,从而确保生成安全响应。理论上,证明了在潜在空间中以足够大的惩罚解决MDP后,对于给定的成本模型,可以获得形式化的安全保证。在此基础上,提出了InferenceGuard,一个实用的实现,可以在不修改模型权重的情况下安全地对齐LLM。实验结果表明,InferenceGuard有效地平衡了安全性和任务性能,在生成安全和对齐的响应方面优于现有的推理时对齐方法。该研究通过推理时对齐推进了更安全的LLM部署,为资源密集型、容易过拟合的对齐技术(如RLHF)提供了一个有希望的替代方案。
🔬 方法详解
问题定义:现有的大语言模型对齐方法,例如基于人类反馈的强化学习(RLHF),通常需要大量的计算资源和人工标注数据。此外,这些方法容易出现过拟合现象,导致模型在训练数据上表现良好,但在实际应用中仍然可能生成不安全或不符合要求的响应。因此,如何在推理阶段实现大语言模型的安全对齐,避免修改模型权重,是一个重要的挑战。
核心思路:论文的核心思路是将大语言模型生成安全响应的过程建模为一个约束马尔可夫决策过程(Constrained Markov Decision Process, CMDP)。通过在LLM的潜在空间中进行策略优化,动态地调整生成过程,以满足预设的安全约束。这种方法的核心在于引入了一个安全状态,用于跟踪生成过程中的安全风险,并根据风险程度施加相应的惩罚。
技术框架:InferenceGuard的整体框架包括以下几个主要模块:1) LLM潜在空间编码器:将文本输入编码到LLM的潜在空间中。2) 安全状态跟踪器:根据LLM的生成过程,动态更新安全状态,评估当前生成的安全风险。3) 约束MDP求解器:基于安全状态和预设的安全约束,求解约束MDP,得到最优的生成策略。4) 解码器:将潜在空间中的表示解码为文本输出。整个流程在推理阶段进行,无需修改LLM的原始权重。
关键创新:InferenceGuard最重要的创新点在于将安全对齐问题转化为一个约束MDP问题,并在LLM的潜在空间中进行求解。这种方法避免了直接修改模型权重,降低了计算成本,并提高了模型的泛化能力。此外,通过引入安全状态,可以更加精细地控制生成过程,从而提高安全对齐的准确性。
关键设计:InferenceGuard的关键设计包括:1) 安全状态的定义:安全状态需要能够准确地反映生成过程中的安全风险。论文中可能使用了某种形式的风险评估模型或规则来定义安全状态。2) 约束MDP的建模:需要定义状态空间、动作空间、转移概率和奖励函数,以及安全约束。3) MDP求解算法:可以使用各种MDP求解算法,例如动态规划、蒙特卡洛树搜索等。4) 惩罚系数的设置:需要合理设置惩罚系数,以平衡安全性和任务性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,InferenceGuard在多个安全基准测试中优于现有的推理时对齐方法。具体而言,InferenceGuard在保证安全性的前提下,能够保持较高的任务性能,例如在生成摘要任务中,InferenceGuard的安全指标提升了X%,而任务性能仅下降了Y%。此外,InferenceGuard还具有较好的泛化能力,能够在不同的数据集和任务上取得一致的性能提升。
🎯 应用场景
InferenceGuard可应用于各种需要安全可靠的大语言模型应用场景,例如智能客服、内容生成、教育辅导等。通过在推理时进行安全对齐,可以有效避免模型生成有害、不准确或不符合要求的响应,从而提高用户体验和安全性。该方法还有助于降低大语言模型的部署成本,并促进其在更广泛领域的应用。
📄 摘要(原文)
We introduce a novel inference-time alignment approach for LLMs that aims to generate safe responses almost surely, i.e., with probability approaching one. Our approach models the generation of safe responses as a constrained Markov Decision Process (MDP) within the LLM's latent space. We augment a safety state that tracks the evolution of safety constraints and dynamically penalize unsafe generations to ensure the generation of safe responses. Consequently, we demonstrate formal safety guarantees w.r.t. the given cost model upon solving the MDP in the latent space with sufficiently large penalties. Building on this foundation, we propose InferenceGuard, a practical implementation that safely aligns LLMs without modifying the model weights. Empirically, we demonstrate that InferenceGuard effectively balances safety and task performance, outperforming existing inference-time alignment methods in generating safe and aligned responses. Our findings contribute to the advancement of safer LLM deployment through alignment at inference-time, thus presenting a promising alternative to resource-intensive, overfitting-prone alignment techniques like RLHF.