Should You Use Your Large Language Model to Explore or Exploit?
作者: Keegan Harris, Aleksandrs Slivkins
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-01-31 (更新: 2025-09-30)
💡 一句话要点
评估LLM在探索-利用权衡中的能力,发现其在探索语义化动作空间中具有潜力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 探索-利用权衡 上下文bandit 动作空间探索 语义理解
📋 核心要点
- 现有方法在探索-利用权衡问题中,难以有效处理具有复杂语义的大型动作空间。
- 利用LLM的语义理解能力,为探索过程提供候选动作建议,从而提升探索效率。
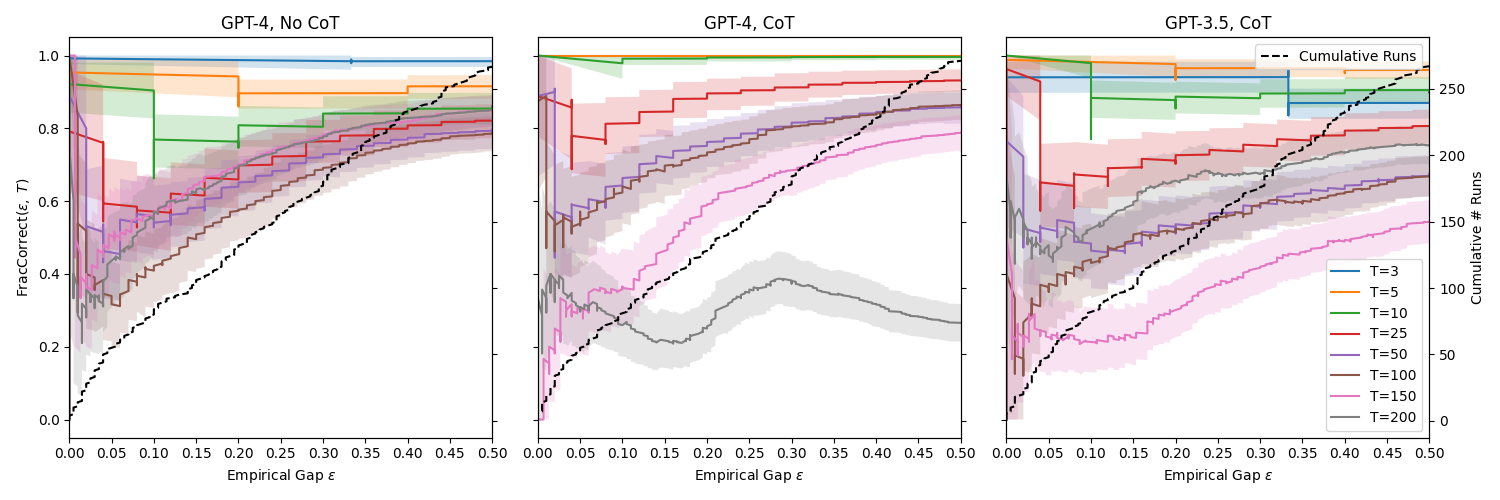
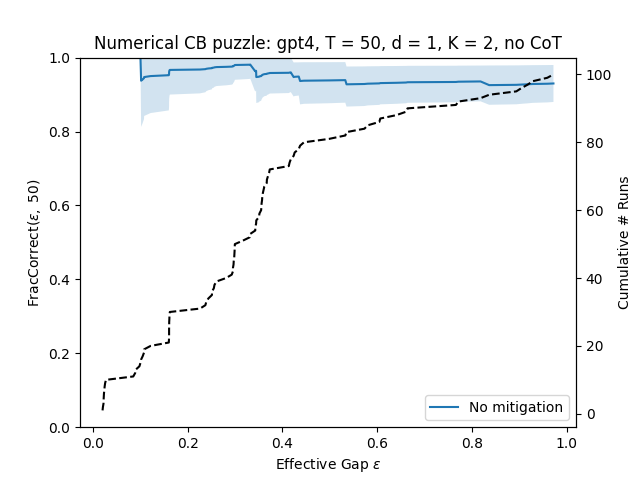
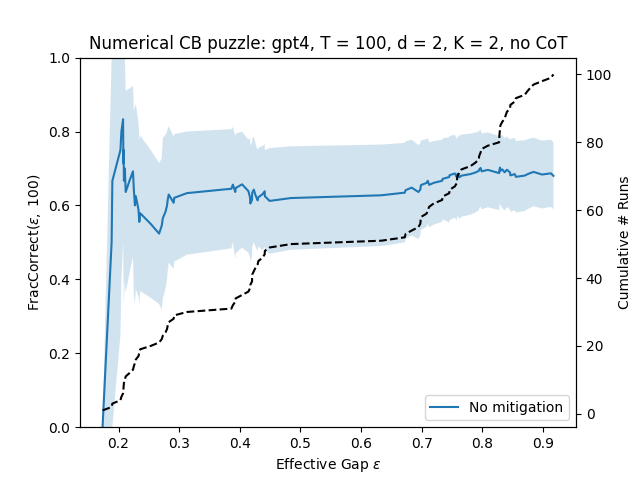
- 实验表明,LLM在探索阶段表现出潜力,但在利用阶段不如传统方法,需要进一步优化。
📝 摘要(中文)
本文评估了当前大型语言模型(LLM)在面临探索-利用权衡时,辅助决策代理的能力。研究人员在各种(上下文)bandit任务中,分别使用LLM进行探索和利用。结果表明,当前的LLM在利用方面表现不佳,但可以通过上下文缓解措施来显著提高小规模任务的性能。然而,即使如此,LLM的性能仍然不如简单的线性回归。另一方面,研究发现LLM在探索具有内在语义的大型动作空间时有所帮助,能够建议合适的探索候选对象。
🔬 方法详解
问题定义:论文研究的是在探索-利用权衡问题中,如何利用大型语言模型(LLM)来辅助决策代理。传统的bandit算法在面对具有复杂语义的大型动作空间时,探索效率较低,难以找到最优动作。现有方法通常依赖于随机探索或基于模型的探索,但在高维语义空间中效果不佳。
核心思路:论文的核心思路是利用LLM的语义理解和生成能力,将LLM作为探索阶段的候选动作生成器。LLM可以根据上下文信息,生成具有语义相关性的候选动作,从而缩小搜索空间,提高探索效率。在利用阶段,则评估LLM直接进行决策的能力。
技术框架:整体框架分为探索和利用两个阶段。在探索阶段,LLM接收上下文信息,并生成一组候选动作。然后,代理从这些候选动作中选择一个进行执行,并观察奖励。在利用阶段,LLM直接根据上下文信息选择动作,目标是最大化累积奖励。研究人员使用了不同的上下文bandit任务来评估LLM的性能。
关键创新:论文的关键创新在于将LLM引入到探索-利用框架中,并将其作为探索阶段的候选动作生成器。这种方法利用了LLM的语义理解能力,可以有效地探索具有复杂语义的大型动作空间。与传统的随机探索或基于模型的探索方法相比,LLM可以生成更具信息量的候选动作。
关键设计:论文使用了不同的LLM,并探索了不同的上下文缓解措施,以提高LLM在利用阶段的性能。例如,研究人员使用了in-context learning,通过提供一些示例来指导LLM进行决策。此外,研究人员还比较了LLM与简单的线性回归模型在利用阶段的性能。在探索阶段,关键的设计在于如何有效地利用LLM生成候选动作,以及如何平衡探索和利用之间的权衡。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM在探索具有内在语义的大型动作空间时有所帮助,能够建议合适的探索候选对象。然而,在利用阶段,LLM的性能不如简单的线性回归模型。通过上下文缓解措施,可以显著提高LLM在小规模任务中的性能。这些结果表明,LLM在探索阶段具有潜力,但在利用阶段仍需进一步优化。
🎯 应用场景
该研究成果可应用于推荐系统、对话系统、机器人控制等领域。例如,在推荐系统中,可以利用LLM生成候选推荐物品,从而提高推荐的多样性和相关性。在对话系统中,可以利用LLM生成候选回复,从而提高对话的流畅性和自然性。在机器人控制中,可以利用LLM生成候选动作,从而提高机器人的自主性和适应性。
📄 摘要(原文)
We evaluate the ability of the current generation of large language models (LLMs) to help a decision-making agent facing an exploration-exploitation tradeoff. We use LLMs to explore and exploit in silos in various (contextual) bandit tasks. We find that while the current LLMs often struggle to exploit, in-context mitigations may be used to substantially improve performance for small-scale tasks. However even then, LLMs perform worse than a simple linear regression. On the other hand, we find that LLMs do help at exploring large action spaces with inherent semantics, by suggesting suitable candidates to explore.