Reward-aware Preference Optimization: A Unified Mathematical Framework for Model Alignment
作者: Shengyang Sun, Yian Zhang, Alexander Bukharin, David Mosallanezhad, Jiaqi Zeng, Soumye Singhal, Gerald Shen, Adithya Renduchintala, Tugrul Konuk, Yi Dong, Zhilin Wang, Dmitry Chichkov, Olivier Delalleau, Oleksii Kuchaiev
分类: cs.LG, cs.CL
发布日期: 2025-01-31 (更新: 2025-02-07)
备注: 8 pages, 4 figures; update author names
💡 一句话要点
RPO:统一的奖励感知偏好优化框架,用于模型对齐
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型对齐 偏好优化 奖励模型 强化学习 消融研究
📋 核心要点
- 现有大语言模型对齐算法繁多,缺乏统一框架,难以评估和比较不同方法的有效性。
- 提出奖励感知偏好优化(RPO)框架,统一多种偏好优化技术,便于系统研究设计选择的影响。
- 通过消融实验,揭示了影响模型对齐的关键因素,为改进LLM对齐提供了实践指导。
📝 摘要(中文)
大型语言模型(LLM)对齐算法的快速发展导致了一个复杂且分散的格局,不同方法的有效性及其相互联系尚不明确。本文提出了奖励感知偏好优化(RPO),这是一个统一的数学框架,它统一了LLM对齐中流行的偏好优化技术,包括DPO、IPO、SimPO和REINFORCE(LOO)等。RPO提供了一种结构化的方法来分解和系统地研究各种设计选择的影响,例如优化目标、每个提示的响应数量以及隐式与显式奖励模型的使用,从而影响LLM偏好优化。此外,我们提出了一种新的实验设置,可以干净且直接地消融这些设计选择。通过RPO框架内的大量消融研究,我们深入了解了影响模型对齐的关键因素,为改进LLM对齐的最有效策略提供了实践指导。
🔬 方法详解
问题定义:现有的大语言模型对齐算法种类繁多,缺乏一个统一的理论框架来理解和比较它们。这使得研究人员难以确定哪些设计选择(例如,优化目标、每个提示的响应数量、奖励模型的类型)对模型对齐的最终效果影响最大。现有方法之间缺乏清晰的联系,阻碍了该领域的进一步发展。
核心思路:RPO的核心思路是将各种偏好优化方法视为在统一的数学框架下的不同实现。通过将这些方法形式化地表示为奖励感知的优化过程,RPO能够 disentangle 各种设计选择的影响,并系统地研究它们之间的相互作用。这种统一的视角使得研究人员能够更好地理解不同方法的优缺点,并为设计更有效的对齐算法提供指导。
技术框架:RPO框架包含以下主要组成部分:1) 一个奖励模型,用于评估模型生成的响应的质量;2) 一个偏好优化目标,用于指导模型的训练;3) 一组设计选择,例如优化算法、每个提示的响应数量以及奖励模型的类型。该框架允许研究人员通过改变这些设计选择来探索不同的对齐策略,并评估它们对模型性能的影响。
关键创新:RPO最重要的技术创新在于其统一性。它提供了一个通用的数学框架,可以用来表示和比较各种现有的偏好优化方法。这种统一性使得研究人员能够更好地理解不同方法之间的联系,并为设计新的、更有效的对齐算法提供指导。此外,RPO还提出了一种新的实验设置,可以干净且直接地消融各种设计选择的影响。
关键设计:RPO框架的关键设计包括:1) 使用奖励模型来评估模型生成的响应的质量;2) 使用偏好优化目标来指导模型的训练;3) 提供一组设计选择,例如优化算法、每个提示的响应数量以及奖励模型的类型,以便研究人员可以探索不同的对齐策略。具体的损失函数和网络结构取决于所使用的具体偏好优化方法,例如DPO、IPO或SimPO。RPO框架本身并不限定特定的实现细节,而是提供了一个通用的框架,可以用来研究各种不同的设计选择。
🖼️ 关键图片
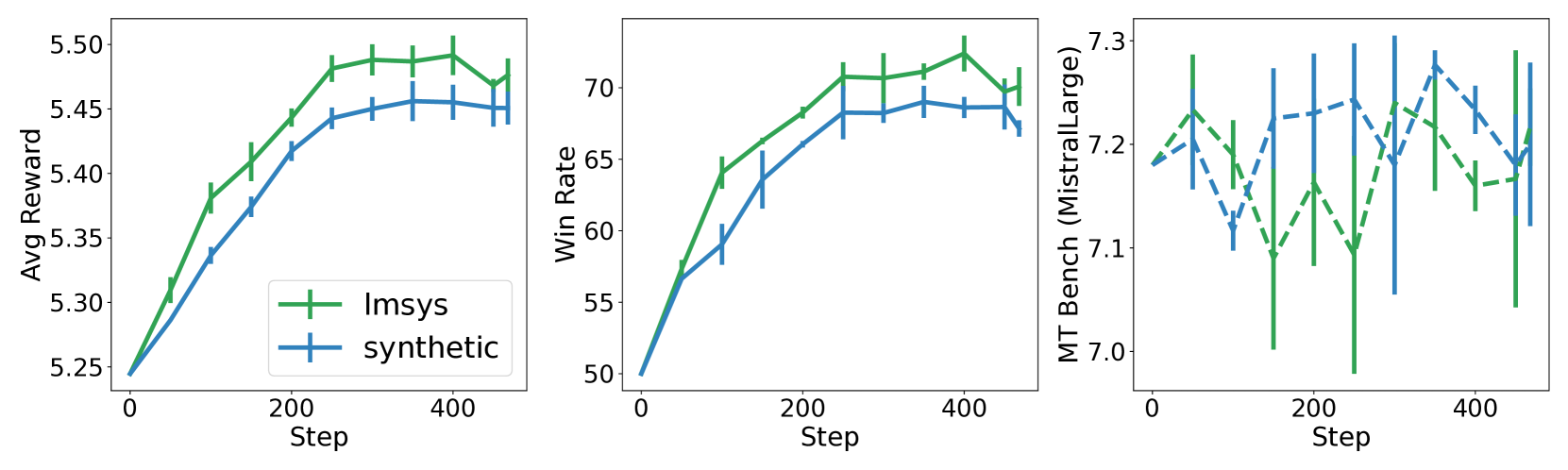
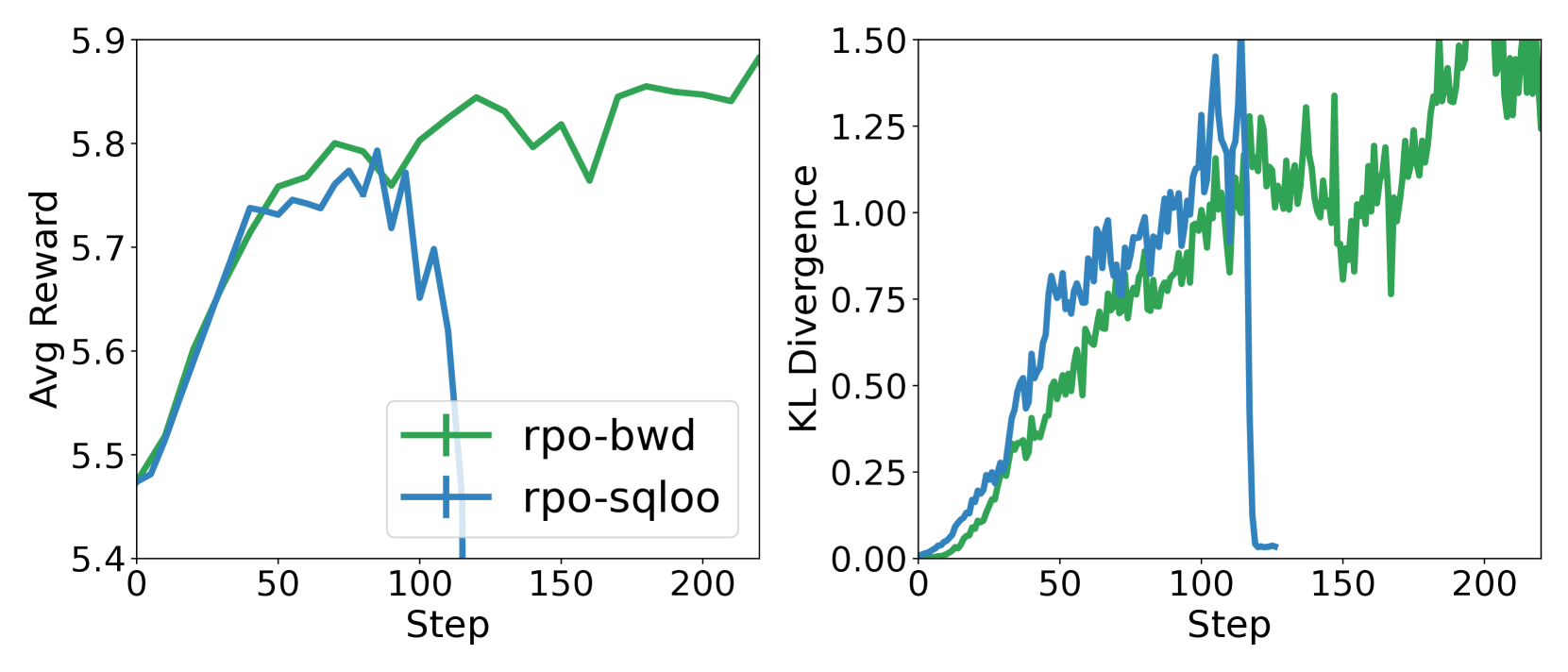
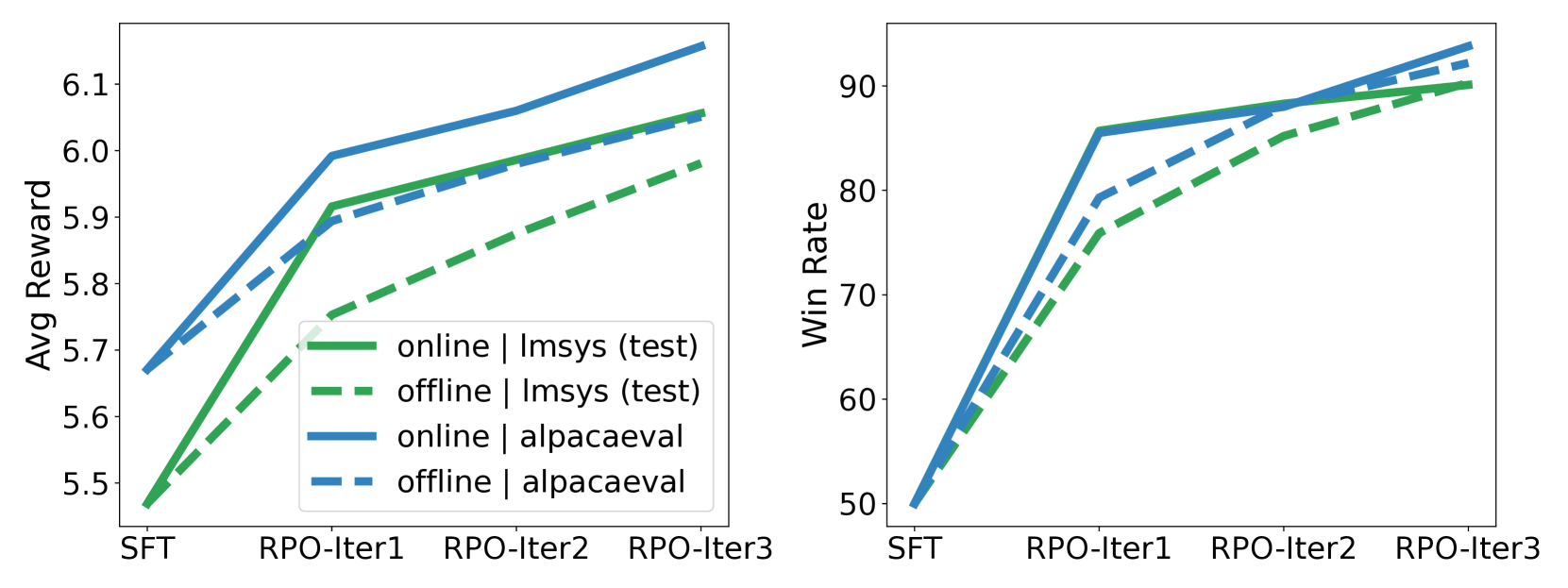
📊 实验亮点
该论文通过大量的消融实验,深入分析了不同设计选择对模型对齐的影响。实验结果表明,优化目标、每个提示的响应数量以及奖励模型的类型等因素都会显著影响模型性能。RPO框架能够有效地统一和比较不同的偏好优化方法,为改进LLM对齐提供了实践指导。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的对齐训练,提升模型输出结果的安全性、可靠性和符合人类价值观的程度。通过RPO框架,开发者可以更高效地探索和优化模型对齐策略,加速LLM在对话系统、内容生成、智能助手等领域的应用。
📄 摘要(原文)
The rapid development of large language model (LLM) alignment algorithms has resulted in a complex and fragmented landscape, with limited clarity on the effectiveness of different methods and their inter-connections. This paper introduces Reward-Aware Preference Optimization (RPO), a mathematical framework that unifies popular preference optimization techniques in LLM alignment, including DPO, IPO, SimPO, and REINFORCE (LOO), among others. RPO provides a structured approach to disentangle and systematically study the impact of various design choices, such as the optimization objective, the number of responses per prompt, and the use of implicit versus explicit reward models, on LLM preference optimization. We additionally propose a new experimental setup that enables the clean and direct ablation of such design choices. Through an extensive series of ablation studies within the RPO framework, we gain insights into the critical factors shaping model alignment, offering practical guidance on the most effective strategies for improving LLM alignment.