Vintix: Action Model via In-Context Reinforcement Learning
作者: Andrey Polubarov, Nikita Lyubaykin, Alexander Derevyagin, Ilya Zisman, Denis Tarasov, Alexander Nikulin, Vladislav Kurenkov
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-01-31 (更新: 2025-09-29)
备注: ICML 2025, Poster
🔗 代码/项目: GITHUB
💡 一句话要点
Vintix:通过上下文强化学习实现跨领域通用动作模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文强化学习 算法蒸馏 跨领域学习 通用智能体 动作模型
📋 核心要点
- 现有ICRL方法在复杂任务和多领域泛化方面存在挑战,难以扩展到实际应用。
- 论文提出使用算法蒸馏框架,训练一个固定的跨领域模型,通过上下文学习实现行为学习。
- 实验结果表明,算法蒸馏是专家蒸馏之外,构建通用动作模型的有效替代方案。
📝 摘要(中文)
上下文强化学习(ICRL)为开发通用智能体提供了一种有前景的范例,它类似于大型语言模型在上下文中进行适应,但侧重于奖励最大化,通过试错交互在推理时进行学习。然而,ICRL在玩具任务和单领域设置之外的可扩展性仍然是一个公开的挑战。在这项工作中,我们提出了扩展ICRL的第一步,引入了一个固定的、跨领域的模型,该模型能够通过上下文强化学习来学习行为。我们的结果表明,算法蒸馏(Algorithm Distillation)是一种旨在促进ICRL的框架,为构建通用的动作模型提供了一种引人注目且具有竞争力的专家蒸馏替代方案。这些发现突出了ICRL作为通用决策系统的一种可扩展方法的潜力。
🔬 方法详解
问题定义:论文旨在解决上下文强化学习(ICRL)在复杂任务和跨领域泛化方面的可扩展性问题。现有的ICRL方法通常难以处理超出玩具任务和单领域环境的场景,限制了其在实际应用中的潜力。这些方法往往需要针对特定任务进行定制,缺乏通用性和适应性。
核心思路:论文的核心思路是利用算法蒸馏(Algorithm Distillation)框架,训练一个固定的、跨领域的动作模型。该模型通过上下文学习,即在推理时根据提供的上下文信息(例如,历史状态、动作和奖励序列)来学习新的行为。这种方法旨在提高ICRL的泛化能力和适应性,使其能够处理更复杂和多样的任务。
技术框架:Vintix的整体框架基于算法蒸馏。首先,使用多个领域的专家策略生成训练数据。然后,使用这些数据训练一个固定的动作模型,该模型能够根据上下文信息预测动作。在推理时,该模型接收历史状态、动作和奖励序列作为输入,并预测下一步的动作。该框架的关键组成部分包括:1) 数据生成模块,用于生成训练数据;2) 动作模型,用于根据上下文信息预测动作;3) 训练模块,用于训练动作模型。
关键创新:论文最重要的技术创新点在于使用算法蒸馏来构建一个固定的、跨领域的ICRL模型。与传统的专家蒸馏方法不同,算法蒸馏侧重于学习专家的策略,而不是简单地模仿专家的行为。这使得模型能够更好地泛化到新的任务和领域。此外,该模型是固定的,这意味着它不需要在推理时进行微调,从而提高了效率和可扩展性。
关键设计:论文中关于算法蒸馏的具体实现细节(例如,损失函数、网络结构、参数设置)在摘要中没有详细说明,属于未知信息。但是,可以推断,损失函数可能包括模仿学习损失(例如,交叉熵损失或均方误差损失)和强化学习损失(例如,策略梯度损失或Q学习损失)。网络结构可能采用Transformer或其他序列模型,以处理上下文信息。参数设置可能需要根据具体任务进行调整。
🖼️ 关键图片
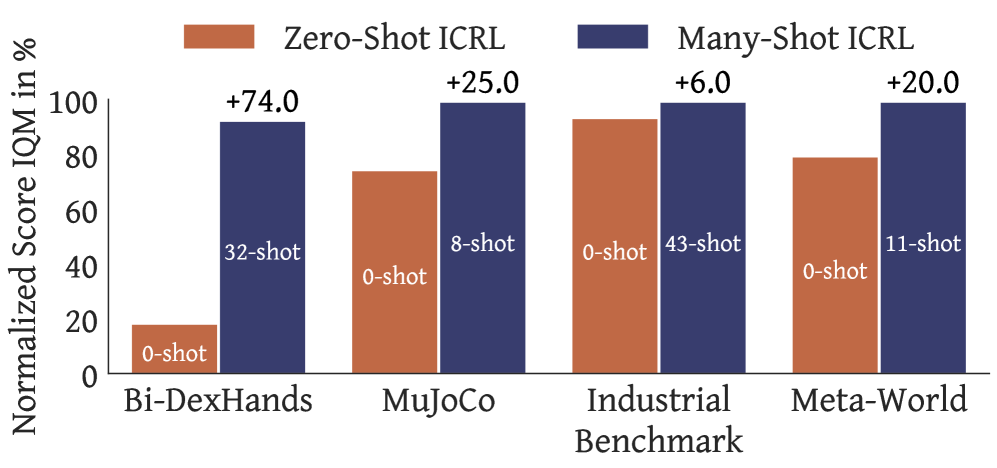
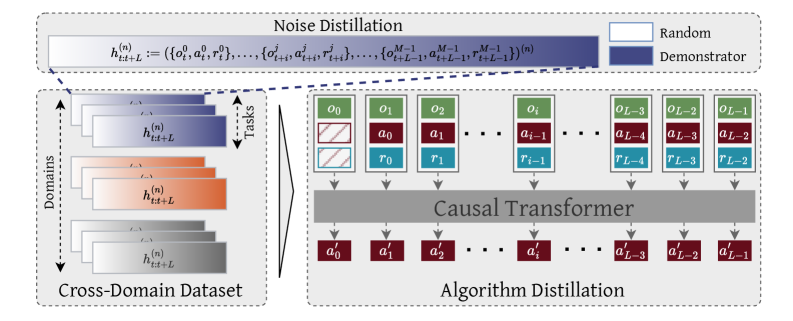
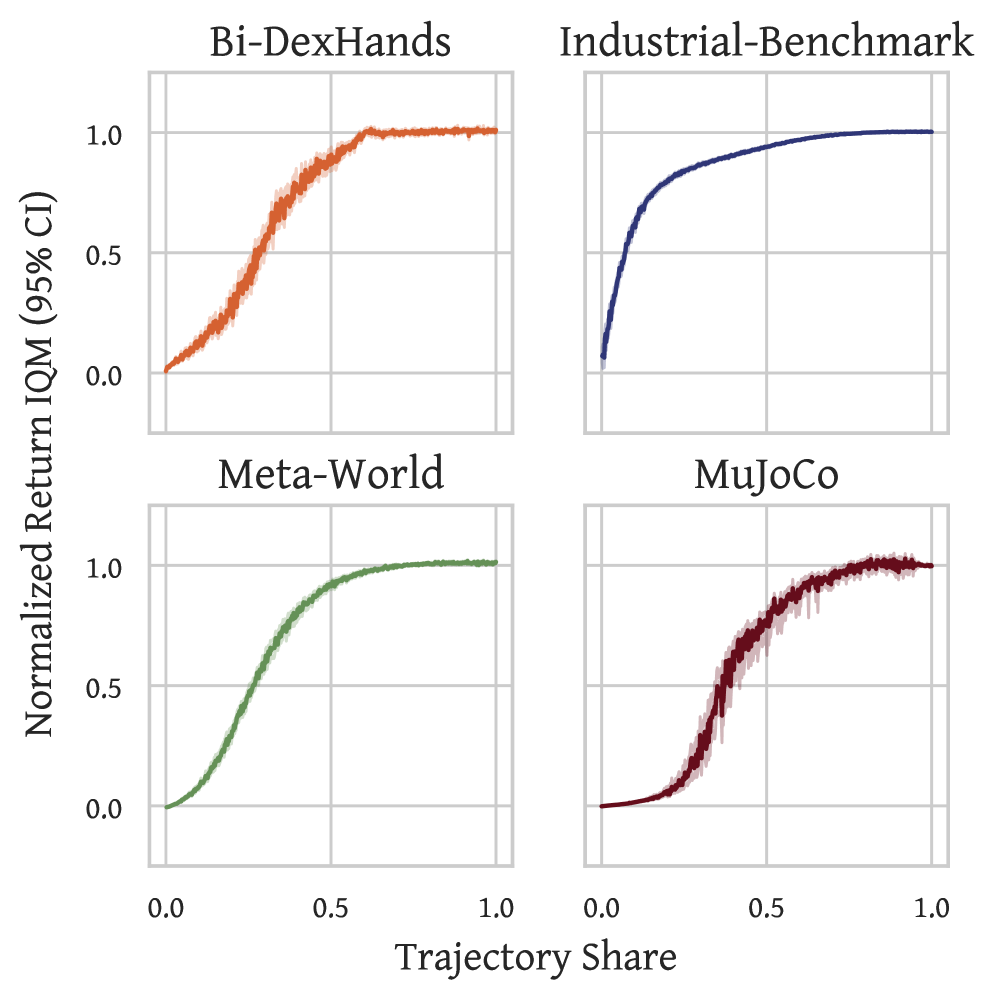
📊 实验亮点
论文结果表明,算法蒸馏为构建通用动作模型提供了一种引人注目且具有竞争力的专家蒸馏替代方案。虽然摘要中没有提供具体的性能数据和提升幅度,但强调了该方法在扩展ICRL方面的潜力,并为通用决策系统的发展提供了新的思路。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、自动驾驶等领域。通过ICRL,智能体可以在未知环境中快速学习和适应,无需预先进行大量的训练。这对于需要高度灵活性和适应性的应用场景具有重要价值,例如,在新的环境中操作的机器人或在不断变化的游戏规则下进行游戏的AI。
📄 摘要(原文)
In-Context Reinforcement Learning (ICRL) represents a promising paradigm for developing generalist agents that learn at inference time through trial-and-error interactions, analogous to how large language models adapt contextually, but with a focus on reward maximization. However, the scalability of ICRL beyond toy tasks and single-domain settings remains an open challenge. In this work, we present the first steps toward scaling ICRL by introducing a fixed, cross-domain model capable of learning behaviors through in-context reinforcement learning. Our results demonstrate that Algorithm Distillation, a framework designed to facilitate ICRL, offers a compelling and competitive alternative to expert distillation to construct versatile action models. These findings highlight the potential of ICRL as a scalable approach for generalist decision-making systems. Code released at https://github.com/dunnolab/vintix