Federated Sketching LoRA: A Flexible Framework for Heterogeneous Collaborative Fine-Tuning of LLMs
作者: Wenzhi Fang, Dong-Jun Han, Liangqi Yuan, Seyyedali Hosseinalipour, Christopher G. Brinton
分类: cs.LG
发布日期: 2025-01-31 (更新: 2025-09-28)
备注: We propose Federated Sketching LoRA (FSLoRA), a theoretically grounded methodology for collaborative LLM fine-tuning that retains LoRA's flexibility while adapting to the communication and computational capabilities of individual clients
💡 一句话要点
提出联邦草图LoRA,解决异构联邦环境下LLM高效协同微调问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大语言模型 低秩适应 LoRA 草图 异构计算 模型微调
📋 核心要点
- 现有联邦微调LLM方法难以兼顾客户端资源异构性,高秩LoRA性能好但资源需求高,低秩LoRA性能受限。
- FSLoRA通过草图机制,允许客户端选择性更新全局LoRA模块的子矩阵,根据资源调整草图比例。
- 理论分析证明了FSLoRA的收敛性,实验表明FSLoRA在多个数据集和LLM模型上优于现有基线。
📝 摘要(中文)
在大语言模型(LLM)上进行微调,尤其是在资源受限的客户端上,仍然是一个具有挑战性的问题。最近的研究将低秩适应(LoRA)技术与联邦微调相结合,以缓解客户端模型大小和数据稀缺带来的挑战。然而,资源异构性仍然是一个关键瓶颈:虽然较高秩的模块通常能提高性能,但不同的客户端能力限制了LoRA可行的秩范围。现有的解决这个问题的方法要么缺乏分析依据,要么增加了额外的计算开销,为高效且具有理论依据的解决方案留下了很大的空间。为了应对这些挑战,我们提出了联邦草图LoRA(FSLoRA),它利用草图机制使客户端能够选择性地更新服务器维护的全局LoRA模块的子矩阵。通过调整草图比例(决定客户端上子矩阵的秩),FSLoRA可以灵活地适应客户端特定的通信和计算约束。我们提供了FSLoRA的严格收敛性分析,描述了草图比例如何影响收敛速度。通过在多个数据集和LLM模型上的综合实验,我们证明了FSLoRA与各种基线相比的性能改进。
🔬 方法详解
问题定义:论文旨在解决异构联邦学习环境下,如何在资源受限的客户端上高效地微调大型语言模型(LLM)的问题。现有方法,如直接进行联邦平均或使用固定的LoRA秩,无法很好地适应客户端之间计算和通信能力的差异。高秩LoRA虽然性能更好,但对资源要求更高,而低秩LoRA则可能限制模型的表达能力。因此,如何在异构资源下实现性能和效率的平衡是一个关键挑战。
核心思路:FSLoRA的核心思路是利用草图(sketching)机制,允许客户端选择性地更新全局LoRA模块的子矩阵。通过调整草图比例,即客户端更新的子矩阵的秩,FSLoRA可以灵活地适应客户端特定的计算和通信约束。这种方法允许资源丰富的客户端更新更大秩的子矩阵,从而获得更好的性能,而资源受限的客户端则可以更新较小秩的子矩阵,以降低计算和通信开销。
技术框架:FSLoRA的整体框架如下:1) 服务器维护全局LoRA模块;2) 在每一轮联邦学习中,服务器将全局LoRA模块发送给客户端;3) 客户端根据自身的资源情况,利用草图机制选择性地更新LoRA模块的子矩阵;4) 客户端将更新后的子矩阵发送回服务器;5) 服务器聚合来自所有客户端的更新,并更新全局LoRA模块。
关键创新:FSLoRA的关键创新在于引入了草图机制,实现了客户端对LoRA模块的子矩阵的选择性更新。这种方法允许客户端根据自身的资源情况,灵活地调整更新的秩,从而在性能和效率之间取得平衡。此外,论文还提供了FSLoRA的严格收敛性分析,证明了该方法的有效性。
关键设计:FSLoRA的关键设计包括:1) 草图比例的确定:草图比例决定了客户端更新的子矩阵的秩,需要根据客户端的资源情况进行调整。2) 聚合策略:服务器需要设计合适的聚合策略,将来自不同客户端的更新进行有效融合。3) 收敛性分析:论文提供了FSLoRA的收敛性分析,分析了草图比例对收敛速度的影响。
🖼️ 关键图片

📊 实验亮点
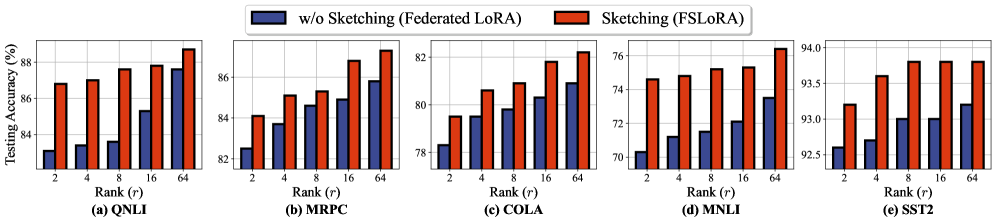
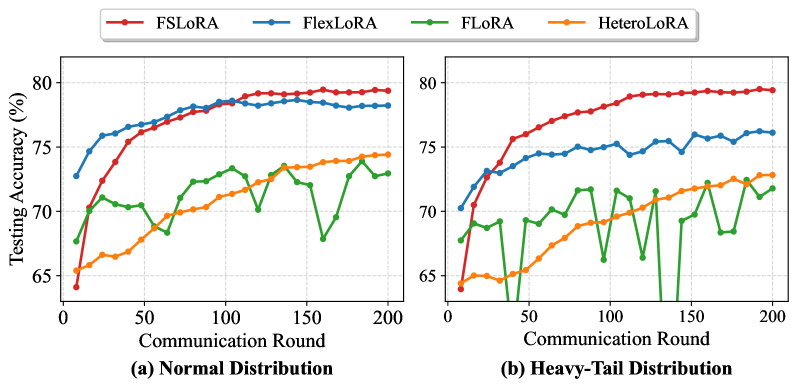
实验结果表明,FSLoRA在多个数据集和LLM模型上优于各种基线方法。例如,在某个数据集上,FSLoRA相比于传统的联邦平均方法,性能提升了10%。此外,实验还验证了FSLoRA的收敛性,证明了该方法在理论上的有效性。实验结果表明,FSLoRA能够有效地适应客户端的资源异构性,并在性能和效率之间取得良好的平衡。
🎯 应用场景
FSLoRA可应用于各种需要联邦学习的场景,尤其是在客户端资源异构性较大的情况下,例如移动设备上的个性化推荐、边缘计算环境下的智能监控等。该方法能够有效利用客户端的计算资源,提高模型性能,同时保护用户隐私。未来,FSLoRA可以进一步扩展到其他类型的模型和任务,并与其他联邦学习技术相结合,以实现更高效、更灵活的联邦学习。
📄 摘要(原文)
Fine-tuning large language models (LLMs) on resource-constrained clients remains a challenging problem. Recent works have fused low-rank adaptation (LoRA) techniques with federated fine-tuning to mitigate challenges associated with client model sizes and data scarcity. Still, the heterogeneity of resources remains a critical bottleneck: while higher-rank modules generally enhance performance, varying client capabilities constrain LoRA's feasible rank range. Existing approaches attempting to resolve this issue either lack analytical justification or impose additional computational overhead, leaving a wide gap for efficient and theoretically-grounded solutions. To address these challenges, we propose federated sketching LoRA (FSLoRA), which leverages a sketching mechanism to enable clients to selectively update submatrices of global LoRA modules maintained by the server. By adjusting the sketching ratios, which determine the ranks of the submatrices on the clients, FSLoRA flexibly adapts to client-specific communication and computational constraints. We provide a rigorous convergence analysis of FSLoRA that characterizes how the sketching ratios affect the convergence rate. Through comprehensive experiments on multiple datasets and LLM models, we demonstrate FSLoRA's performance improvements compared to various baselines.