Offline Learning for Combinatorial Multi-armed Bandits
作者: Xutong Liu, Xiangxiang Dai, Jinhang Zuo, Siwei Wang, Carlee Joe-Wong, John C. S. Lui, Wei Chen
分类: cs.LG
发布日期: 2025-01-31 (更新: 2025-05-29)
💡 一句话要点
提出Off-CMAB框架,解决组合多臂老虎机离线学习问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 组合多臂老虎机 离线学习 下置信界 序列决策 学习排序
📋 核心要点
- 现有CMAB研究主要集中于在线学习,忽略了在线交互成本和丰富的离线数据。
- 论文提出Off-CMAB框架,核心是CLCB算法,结合悲观奖励估计和组合求解器。
- 实验表明,Off-CMAB在学习排序、LLM缓存和社会影响力最大化等任务上表现优异。
📝 摘要(中文)
组合多臂老虎机(CMAB)是一个重要的序列决策框架,过去十年受到了广泛研究。然而,现有工作主要集中于在线设置,忽略了在线交互的巨大成本和容易获得的离线数据集。为了克服这些限制,我们提出了Off-CMAB,这是第一个用于CMAB的离线学习框架。我们框架的核心是组合下置信界(CLCB)算法,它将悲观奖励估计与组合求解器相结合。为了描述离线数据集的质量,我们提出了两种新的数据覆盖条件,并证明在这些条件下,CLCB实现了接近最优的次优性差距,在对数因子范围内匹配了理论下界。我们通过实际应用验证了Off-CMAB,包括学习排序、大型语言模型(LLM)缓存和社会影响力最大化,展示了其处理非线性奖励函数、通用反馈模型以及排除最优甚至可行动作的分布外动作样本的能力。在合成和真实世界数据集上的大量实验进一步突出了CLCB的优越性能。
🔬 方法详解
问题定义:论文旨在解决组合多臂老虎机(CMAB)的离线学习问题。传统的CMAB研究主要集中于在线学习,需要大量的在线交互,成本高昂。而现实中往往存在大量的离线数据集,如何利用这些数据进行有效的CMAB学习是一个挑战。现有方法无法有效利用离线数据,并且难以处理非线性奖励函数和分布外动作样本。
核心思路:论文的核心思路是利用离线数据,通过悲观的奖励估计来学习CMAB策略。具体来说,通过构建奖励的下置信界(Lower Confidence Bound, LCB),保证算法在探索未知动作时保持谨慎,避免选择可能导致负面结果的动作。同时,结合组合求解器,在动作空间中高效地搜索最优动作组合。
技术框架:Off-CMAB框架主要包含以下几个阶段:1) 离线数据集收集:收集包含动作和奖励信息的离线数据。2) 奖励估计:利用离线数据估计每个动作组合的奖励,并计算奖励的下置信界。3) 组合求解:使用组合求解器,在满足约束条件的前提下,选择具有最大下置信界的动作组合。4) 策略评估与更新:根据实际奖励反馈,评估当前策略的性能,并利用新的数据更新奖励估计和下置信界。
关键创新:论文的关键创新在于提出了第一个用于CMAB的离线学习框架Off-CMAB,并设计了CLCB算法。此外,论文还提出了两种新的数据覆盖条件,用于刻画离线数据集的质量,并证明了在这些条件下,CLCB算法能够实现接近最优的性能。与现有方法相比,Off-CMAB能够有效利用离线数据,处理非线性奖励函数和分布外动作样本。
关键设计:CLCB算法的关键设计在于下置信界的构建方式。论文采用了一种基于置信区间的悲观估计方法,利用离线数据估计每个动作组合的奖励均值和方差,然后根据置信水平计算下置信界。此外,论文还设计了一种高效的组合求解器,用于在动作空间中搜索最优动作组合。具体参数设置包括置信水平的选择、奖励估计的正则化参数等。损失函数的设计目标是最小化次优性差距,即最小化算法选择的动作组合与最优动作组合之间的奖励差异。
🖼️ 关键图片
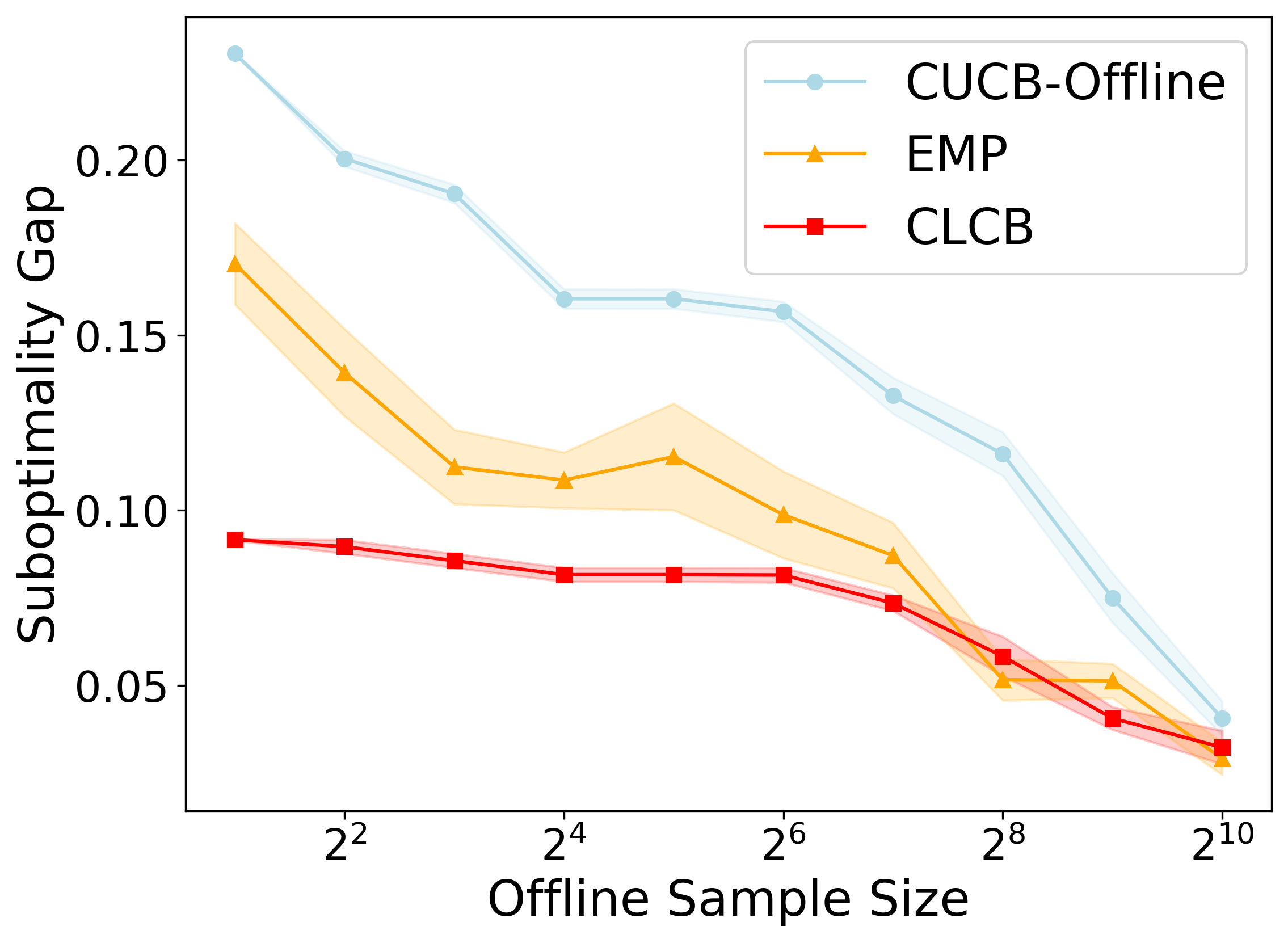
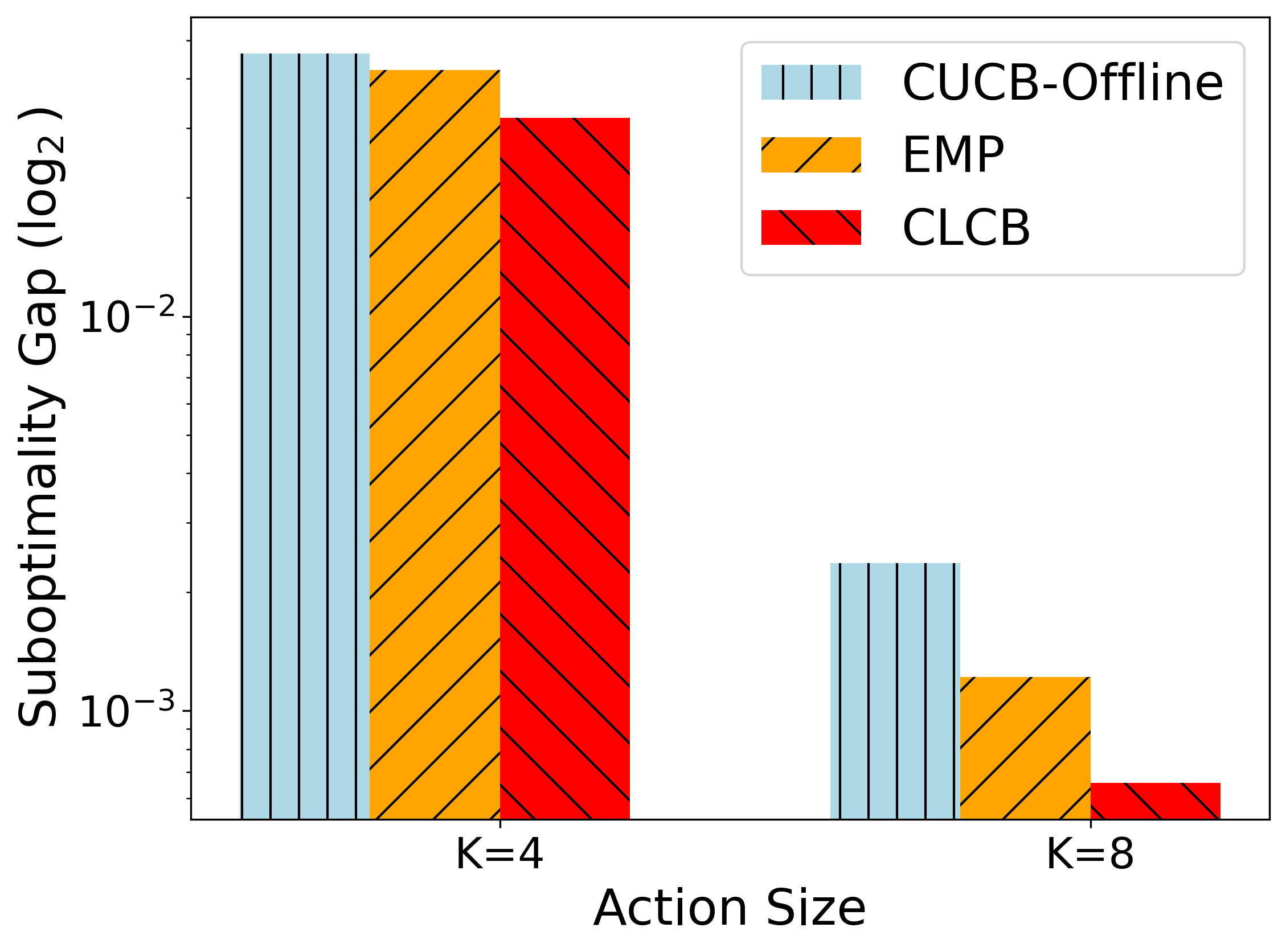
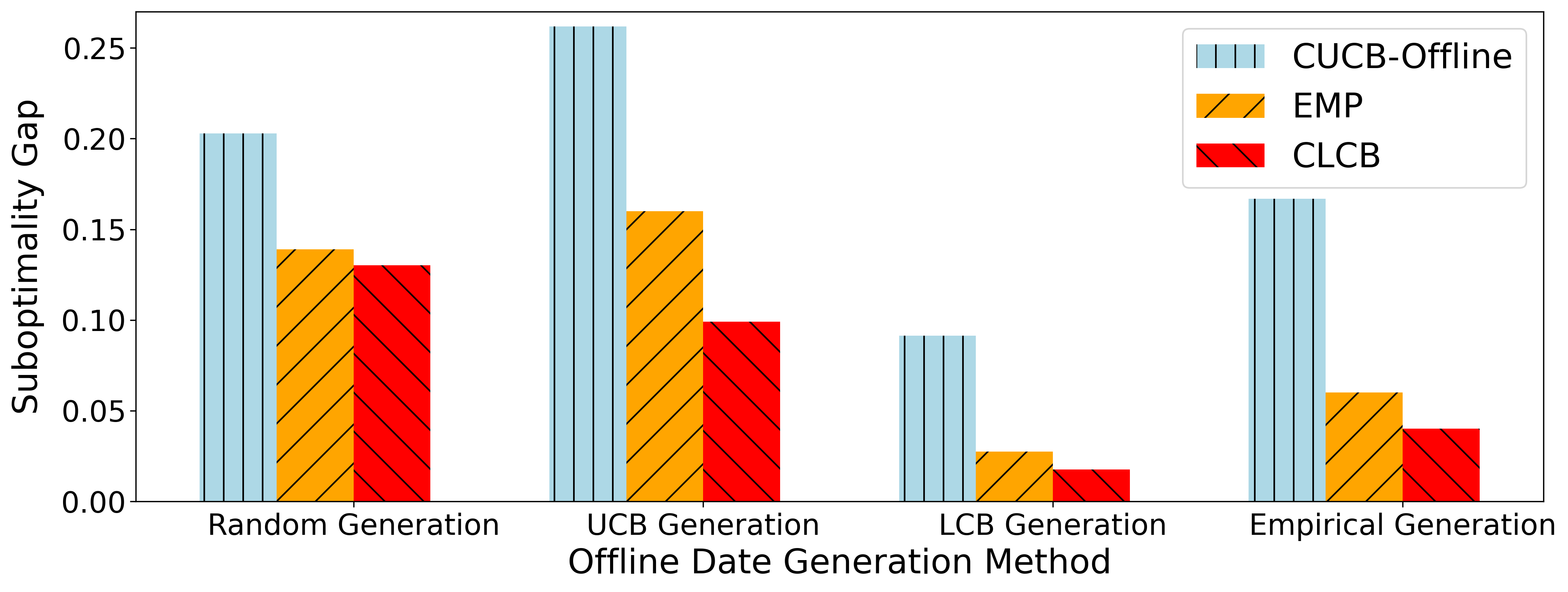
📊 实验亮点
实验结果表明,Off-CMAB在合成数据集和真实数据集上均取得了优异的性能。在学习排序任务中,Off-CMAB相比于现有基线方法,显著提高了排序准确率和用户满意度。在LLM缓存任务中,Off-CMAB有效降低了缓存未命中率,提高了系统性能。在社会影响力最大化任务中,Off-CMAB成功选择了更具影响力的用户,提高了信息传播范围。
🎯 应用场景
该研究具有广泛的应用前景,例如:学习排序(根据用户历史行为优化搜索结果排序)、大型语言模型(LLM)缓存(根据历史访问记录优化缓存策略)、社会影响力最大化(根据历史传播数据选择最具影响力的用户)。该研究能够降低在线交互成本,提高决策效率,具有重要的实际价值和未来影响。
📄 摘要(原文)
The combinatorial multi-armed bandit (CMAB) is a fundamental sequential decision-making framework, extensively studied over the past decade. However, existing work primarily focuses on the online setting, overlooking the substantial costs of online interactions and the readily available offline datasets. To overcome these limitations, we introduce Off-CMAB, the first offline learning framework for CMAB. Central to our framework is the combinatorial lower confidence bound (CLCB) algorithm, which combines pessimistic reward estimations with combinatorial solvers. To characterize the quality of offline datasets, we propose two novel data coverage conditions and prove that, under these conditions, CLCB achieves a near-optimal suboptimality gap, matching the theoretical lower bound up to a logarithmic factor. We validate Off-CMAB through practical applications, including learning to rank, large language model (LLM) caching, and social influence maximization, showing its ability to handle nonlinear reward functions, general feedback models, and out-of-distribution action samples that excludes optimal or even feasible actions. Extensive experiments on synthetic and real-world datasets further highlight the superior performance of CLCB.