Improving Multi-Label Contrastive Learning by Leveraging Label Distribution
作者: Ning Chen, Shen-Huan Lyu, Tian-Shuang Wu, Yanyan Wang, Bin Tang
分类: cs.LG, cs.AI, cs.CV
发布日期: 2025-01-31
💡 一句话要点
提出基于标签分布的多标签对比学习方法,提升表征学习效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多标签学习 对比学习 标签分布 表征学习 径向基函数
📋 核心要点
- 现有方法在多标签对比学习中,正负样本选择复杂,且忽略了不同标签的重要性。
- 该方法仅需考虑标签交集来选择正负样本,并利用标签分布建模标签间关系。
- 实验结果表明,该方法在多个多标签数据集上,显著优于现有技术水平。
📝 摘要(中文)
在多标签学习中,利用对比学习来学习更好的表征面临一个关键挑战:如何选择正负样本并有效利用标签信息。以往的研究基于标签之间的重叠来选择正负样本,并使用它们进行标签级别的损失平衡。然而,这些方法选择过程复杂,并且未能考虑不同标签的重要性差异。为了解决这些问题,我们提出了一种新颖的方法,通过标签分布来改进多标签对比学习。具体来说,在选择正负样本时,我们只需要考虑标签之间是否存在交集。为了建模标签之间的关系,我们引入了两种方法来从逻辑标签中恢复标签分布,分别基于径向基函数(RBF)和对比损失。我们在九个广泛使用的多标签数据集(包括图像和向量数据集)上评估了我们的方法。结果表明,我们的方法在六个评估指标上优于最先进的方法。
🔬 方法详解
问题定义:多标签学习中的对比学习旨在学习更好的数据表征,但如何有效选择正负样本以及充分利用标签信息是一个关键挑战。现有方法通常基于标签重叠度来选择正负样本,并进行标签级别的损失平衡。然而,这种选择过程较为复杂,计算成本高,并且忽略了不同标签的重要性差异,导致表征学习效果不佳。
核心思路:该论文的核心思路是通过引入标签分布的概念来改进多标签对比学习。不再依赖复杂的标签重叠度计算,而是简化正负样本的选择过程,仅考虑标签之间是否存在交集。同时,通过学习标签分布,建模标签之间的关系,从而更有效地利用标签信息,提升表征学习的质量。
技术框架:该方法主要包含以下几个阶段:1) 数据预处理:对输入数据进行必要的预处理操作。2) 标签分布恢复:利用径向基函数(RBF)或对比损失,从原始的逻辑标签中恢复标签分布。3) 对比学习:基于恢复的标签分布,进行对比学习,学习数据表征。4) 模型训练与评估:使用多标签数据集训练模型,并使用多个评估指标评估模型性能。
关键创新:该论文的关键创新在于:1) 简化了正负样本的选择过程,仅考虑标签交集,降低了计算复杂度。2) 提出了两种标签分布恢复方法(基于RBF和对比损失),能够有效建模标签之间的关系。3) 将标签分布引入到多标签对比学习中,提升了表征学习的效果。
关键设计:在标签分布恢复方面,论文提出了两种方法:基于RBF的方法和基于对比损失的方法。基于RBF的方法利用RBF函数来平滑标签之间的关系,而基于对比损失的方法则通过最小化正样本之间的距离,最大化负样本之间的距离来学习标签分布。在对比学习方面,论文采用了InfoNCE损失函数,并根据恢复的标签分布对损失函数进行加权,以平衡不同标签的重要性。
🖼️ 关键图片


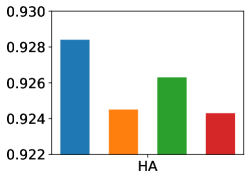
📊 实验亮点
该方法在九个多标签数据集上进行了评估,包括图像和向量数据集。实验结果表明,该方法在六个评估指标上优于最先进的方法。例如,在某些数据集上,该方法在平均精度(Mean Average Precision, MAP)指标上取得了显著的提升,最高提升幅度超过5%。这些结果充分证明了该方法的有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于图像分类、文本分类、视频分析等领域,尤其是在需要处理具有多个标签的数据的场景下。例如,在图像分类中,一张图片可能同时包含多个物体;在文本分类中,一篇文章可能涉及多个主题。该方法能够有效提升多标签分类的准确性和效率,具有重要的实际应用价值和潜在的商业前景。
📄 摘要(原文)
In multi-label learning, leveraging contrastive learning to learn better representations faces a key challenge: selecting positive and negative samples and effectively utilizing label information. Previous studies selected positive and negative samples based on the overlap between labels and used them for label-wise loss balancing. However, these methods suffer from a complex selection process and fail to account for the varying importance of different labels. To address these problems, we propose a novel method that improves multi-label contrastive learning through label distribution. Specifically, when selecting positive and negative samples, we only need to consider whether there is an intersection between labels. To model the relationships between labels, we introduce two methods to recover label distributions from logical labels, based on Radial Basis Function (RBF) and contrastive loss, respectively. We evaluate our method on nine widely used multi-label datasets, including image and vector datasets. The results demonstrate that our method outperforms state-of-the-art methods in six evaluation metrics.