Elucidating Subspace Perturbation in Zeroth-Order Optimization: Theory and Practice at Scale
作者: Sihwan Park, Jihun Yun, SungYub Kim, Souvik Kundu, Eunho Yang
分类: cs.LG
发布日期: 2025-01-31 (更新: 2025-05-23)
备注: 49 pages, 9 figures
💡 一句话要点
提出MeZO-BCD,加速零阶优化在大语言模型微调中的应用,提升高达2.77倍。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零阶优化 子空间扰动 块坐标下降 大语言模型 黑盒优化
📋 核心要点
- 零阶优化在高维黑盒优化中应用广泛,但其随机梯度估计器方差大,收敛慢。
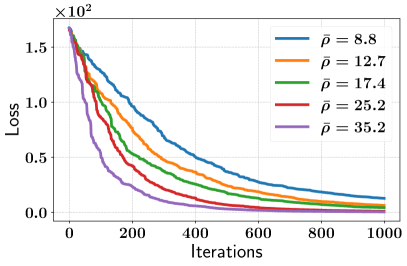
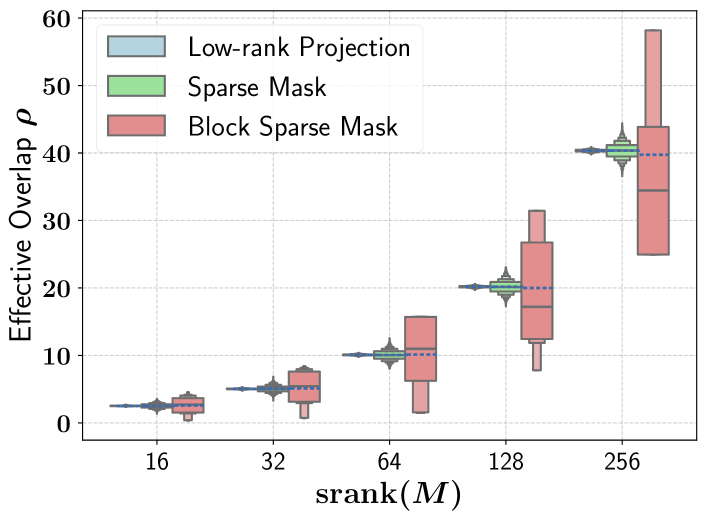
- 论文提出统一理论框架,分析子空间扰动对零阶优化的影响,强调子空间对齐的重要性。
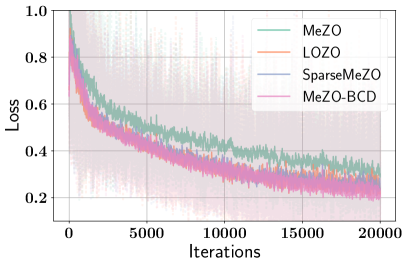
- 提出MeZO-BCD算法,利用块坐标下降策略,在OPT-13B上实现了显著的加速效果。
📝 摘要(中文)
零阶(ZO)优化已成为一种有前景的替代梯度反向传播方法,特别是在黑盒优化和大型语言模型(LLM)微调方面。然而,由于高方差的随机梯度估计器,ZO方法通常收敛速度较慢。虽然已经探索了诸如稀疏性和低秩约束等子空间扰动来缓解这个问题,但它们的效果仍然知之甚少。在这项工作中,我们开发了一个统一的理论框架,分析了子空间扰动下ZO优化的收敛性和泛化特性。我们表明,高维是主要的瓶颈,并引入了子空间对齐的概念,以解释子空间扰动如何减少梯度噪声并加速收敛。我们的分析进一步表明,广泛的子空间扰动表现出相似的收敛速度,这促使我们在实际算法设计中优先考虑实际因素。基于这些见解,我们提出了一种使用块坐标下降(MeZO-BCD)的高效ZO方法,该方法在每个步骤中仅扰动和更新参数的子集。大量的实验表明,MeZO-BCD显著加速了优化,在OPT-13B上实现了高达2.77倍的壁钟时间加速,同时保持了相当的迭代复杂度和微调性能。
🔬 方法详解
问题定义:论文旨在解决零阶优化在高维空间中收敛速度慢的问题,尤其是在大型语言模型微调等场景下。现有的零阶优化方法由于需要估计梯度,在高维空间中梯度估计的方差会显著增大,导致收敛速度缓慢,计算成本高昂。即使引入子空间扰动(如稀疏性或低秩约束)来降低维度,其有效性也缺乏理论支撑。
核心思路:论文的核心思路是通过理论分析揭示子空间扰动在零阶优化中的作用机制,并基于此设计更高效的算法。论文认为,高维是零阶优化收敛慢的主要瓶颈,而子空间扰动通过降低维度、减少梯度噪声来加速收敛。关键在于子空间与真实梯度的对齐程度,对齐程度越高,收敛速度越快。基于此,论文提出了一种基于块坐标下降的零阶优化方法,MeZO-BCD。
技术框架:MeZO-BCD算法的核心流程如下: 1. 参数分组:将模型参数划分为若干个块。 2. 块选择:在每个迭代步骤中,随机选择一个参数块进行扰动和更新。 3. 零阶梯度估计:使用零阶优化方法估计所选块的梯度。 4. 参数更新:根据估计的梯度更新所选块的参数。 5. 迭代:重复步骤2-4,直到收敛。
关键创新:MeZO-BCD的关键创新在于: 1. 理论支撑:论文提供了统一的理论框架,分析了子空间扰动对零阶优化的影响,并提出了“子空间对齐”的概念。 2. 高效性:通过块坐标下降策略,MeZO-BCD每次只更新部分参数,显著降低了计算复杂度,提高了优化速度。 3. 实用性:MeZO-BCD易于实现,并且可以应用于各种零阶优化问题,尤其是在大型语言模型微调等高维场景下。
关键设计:MeZO-BCD的关键设计包括: 1. 块大小的选择:块大小的选择会影响算法的收敛速度和计算复杂度。较小的块可以更快地收敛,但每次迭代的计算量较小;较大的块可以减少迭代次数,但每次迭代的计算量较大。论文可能探讨了块大小选择的策略。 2. 梯度估计方法:MeZO-BCD可以使用各种零阶梯度估计方法,例如随机搜索或有限差分。论文可能比较了不同梯度估计方法的效果。 3. 学习率设置:学习率的选择对算法的收敛性至关重要。论文可能采用了自适应学习率调整策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MeZO-BCD算法在OPT-13B模型上实现了高达2.77倍的壁钟时间加速,同时保持了与MeZO相当的迭代复杂度和微调性能。这表明MeZO-BCD在实际应用中具有显著的优势,能够有效地加速大型语言模型的微调过程。
🎯 应用场景
该研究成果可广泛应用于黑盒优化问题,尤其是在计算资源受限或无法获取梯度信息的场景下。例如,在大型语言模型微调、强化学习、超参数优化、对抗攻击等领域具有重要的应用价值。MeZO-BCD算法能够显著加速优化过程,降低计算成本,推动相关领域的发展。
📄 摘要(原文)
Zeroth-order (ZO) optimization has emerged as a promising alternative to gradient-based backpropagation methods, particularly for black-box optimization and large language model (LLM) fine-tuning. However, ZO methods often suffer from slow convergence due to high-variance stochastic gradient estimators. While subspace perturbations, such as sparsity and low-rank constraints, have been explored to mitigate this issue, their effectiveness remains poorly understood. In this work, we develop a \emph{unified theoretical framework} that analyzes both the convergence and generalization properties of ZO optimization under subspace perturbations. We show that high dimensionality is the primary bottleneck and introduce the notion of \textit{subspace alignment} to explain how the subspace perturbations reduce gradient noise and accelerate convergence. Our analysis further shows that a broad class of subspace perturbations exhibits a similar convergence rate, motivating us to prioritize practical considerations in real-world algorithm design. Building on these insights, we propose an efficient ZO method using block coordinate descent (MeZO-BCD), which perturbs and updates only a subset of parameters at each step. Extensive experiments show that MeZO-BCD significantly accelerates optimization, achieving up to $\mathbf{\times2.77}$ speedup in wall-clock time over MeZO on OPT-13B, while maintaining comparable iteration complexity and fine-tuning performance.