Towards the Worst-case Robustness of Large Language Models
作者: Huanran Chen, Yinpeng Dong, Zeming Wei, Hang Su, Jun Zhu
分类: cs.LG
发布日期: 2025-01-31 (更新: 2025-10-08)
💡 一句话要点
提出针对大语言模型的最坏情况鲁棒性评估方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 对抗攻击 鲁棒性评估 随机防御 机器学习
📋 核心要点
- 大语言模型在对抗攻击下表现出脆弱性,现有防御方法的鲁棒性普遍较低,几乎接近0%。
- 本文提出了一种基于分数背包和0-1背包求解器的随机平滑下界方法,以评估模型的最坏情况鲁棒性。
- 通过理论分析,本文为多种经验防御提供了下界证明,展示了均匀核平滑在特定攻击下的有效性。
📝 摘要(中文)
近期研究揭示了大语言模型在对抗攻击下的脆弱性,攻击者通过特定输入序列诱导模型产生有害、暴力、私密或错误的输出。本文研究了其最坏情况鲁棒性,即是否存在导致这些不良输出的对抗样本。通过更强的白盒攻击,我们对最坏情况鲁棒性进行了上界限制,表明大多数现有的确定性防御方法的鲁棒性接近0%。我们提出了一种通用的随机平滑下界,利用分数背包求解器或0-1背包求解器来界定所有随机防御的最坏情况鲁棒性,并为几种先前的经验防御提供了理论下界。以均匀核平滑为例,我们证明了其对任何可能攻击的鲁棒性,平均$ ext{l}_0$扰动为2.02,平均后缀长度为6.41。
🔬 方法详解
问题定义:本文旨在解决大语言模型在对抗攻击下的最坏情况鲁棒性问题。现有方法普遍缺乏有效的鲁棒性评估,导致防御效果不佳。
核心思路:我们提出了一种基于分数背包和0-1背包求解器的通用下界方法,能够有效评估随机防御的最坏情况鲁棒性。通过这种方法,我们可以更准确地界定模型在对抗攻击下的脆弱性。
技术框架:整体框架包括对抗攻击的生成、鲁棒性评估和防御策略的验证。首先生成对抗样本,然后利用背包求解器计算鲁棒性下界,最后验证不同防御策略的有效性。
关键创新:本文的主要创新在于提出了一种新的鲁棒性评估方法,利用背包问题的求解器为随机防御提供理论下界。这一方法与传统的经验性防御评估方法有本质区别,能够提供更为准确的鲁棒性界限。
关键设计:在设计中,我们设置了特定的参数以优化求解器的性能,并选择了适当的损失函数来衡量模型的输出与目标之间的差异。网络结构方面,采用了均匀核平滑策略,以确保在对抗攻击下的鲁棒性。
🖼️ 关键图片
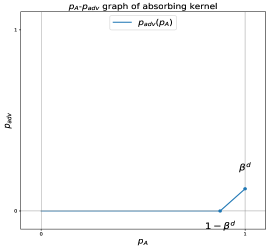
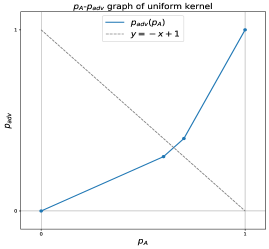
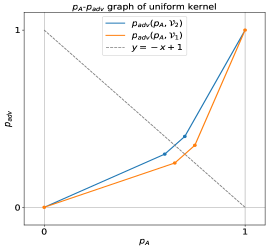
📊 实验亮点
实验结果表明,利用均匀核平滑的鲁棒性在特定攻击下表现出色,平均$ ext{l}_0$扰动为2.02,平均后缀长度为6.41,显著优于现有的防御方法。这一结果验证了我们提出的理论下界的有效性,并为未来的防御策略提供了新的思路。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、对话系统和自动文本生成等。通过提高大语言模型的鲁棒性,可以有效减少模型在实际应用中受到对抗攻击的风险,提升用户信任度和系统安全性。未来,该方法有望推广至其他类型的机器学习模型,增强其在复杂环境下的稳定性和可靠性。
📄 摘要(原文)
Recent studies have revealed the vulnerability of large language models to adversarial attacks, where adversaries craft specific input sequences to induce harmful, violent, private, or incorrect outputs. In this work, we study their worst-case robustness, i.e., whether an adversarial example exists that leads to such undesirable outputs. We upper bound the worst-case robustness using stronger white-box attacks, indicating that most current deterministic defenses achieve nearly 0\% worst-case robustness. We propose a general tight lower bound for randomized smoothing using fractional knapsack solvers or 0-1 knapsack solvers, and using them to bound the worst-case robustness of all stochastic defenses. Based on these solvers, we provide theoretical lower bounds for several previous empirical defenses. For example, we certify the robustness of a specific case, smoothing using a uniform kernel, against \textit{any possible attack} with an average $\ell_0$ perturbation of 2.02 or an average suffix length of 6.41.