Spend Wisely: Maximizing Post-Training Gains in Iterative Synthetic Data Bootstrapping
作者: Pu Yang, Yunzhen Feng, Ziyuan Chen, Yuhang Wu, Zhuoyuan Li
分类: cs.LG
发布日期: 2025-01-31 (更新: 2025-10-16)
备注: NeurIPS 2025 (spotlight)
💡 一句话要点
优化迭代合成数据自举训练:最大化后训练阶段性能提升
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成数据 自举训练 预算分配 后训练 迭代优化
📋 核心要点
- 现有后训练方法在迭代合成数据自举过程中,缺乏对生成和训练预算分配的有效策略。
- 论文提出一种理论框架,分析不同预算分配策略对模型性能的影响,特别是递增策略的优势。
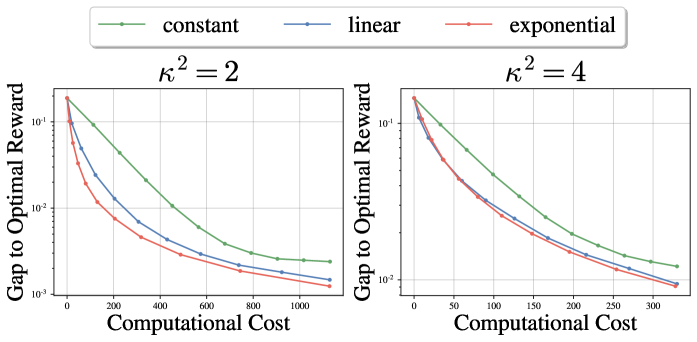
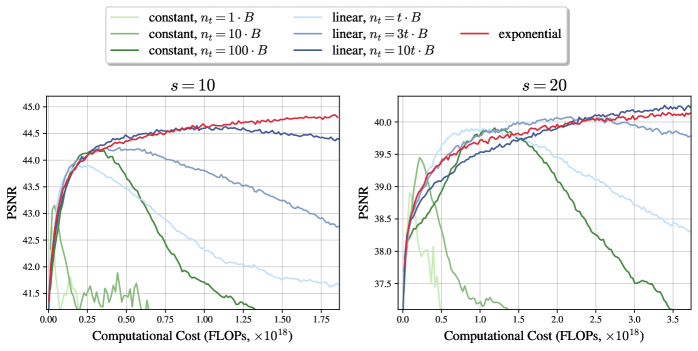
- 实验结果表明,指数增长策略在图像去噪和数学推理任务中,性能优于恒定策略,且更稳定。
📝 摘要(中文)
现代基础模型通常在后训练阶段经历迭代“自举”过程:模型生成合成数据,外部验证器过滤掉低质量样本,高质量子集用于进一步微调。经过多次迭代,模型性能提高,从而产生一个关键问题:如何分配生成和训练的总预算,以在多次迭代中最大化最终性能?本文开发了一个理论框架来分析预算分配策略。具体而言,我们表明,恒定策略在高概率下无法收敛,而递增策略(尤其是指数增长策略)表现出显著的理论优势。在扩散概率模型的图像去噪和大型语言模型的数学推理实验表明,指数和多项式增长策略始终优于恒定策略,并且指数策略通常提供更稳定的性能。
🔬 方法详解
问题定义:论文旨在解决在迭代合成数据自举训练中,如何有效地分配生成和训练的总预算,以最大化最终模型性能的问题。现有方法,如采用恒定预算策略,可能无法充分利用迭代过程中的信息增益,导致模型性能提升受限。
核心思路:论文的核心思路是,通过理论分析不同预算分配策略对模型收敛性的影响,发现递增策略,尤其是指数增长策略,能够更有效地利用迭代过程中的数据,从而实现更好的模型性能。这种策略允许模型在后续迭代中利用先前迭代的知识,逐步提升生成数据的质量和模型自身的性能。
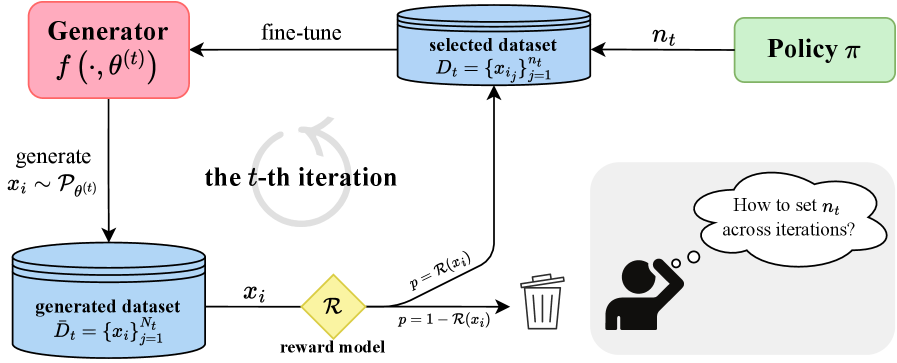
技术框架:整体框架包含以下几个主要阶段:1) 模型生成合成数据;2) 外部验证器对生成的数据进行质量评估和过滤;3) 使用高质量的合成数据子集对模型进行微调;4) 重复以上步骤进行多次迭代。关键在于,每次迭代中分配给生成和训练的预算不是固定的,而是根据预定的策略(如恒定、多项式增长或指数增长)进行调整。
关键创新:论文最重要的技术创新在于,提出了一个理论框架来分析不同预算分配策略的收敛性,并证明了递增策略,尤其是指数增长策略,在理论上具有显著优势。这与以往主要关注数据质量或模型架构的工作不同,而是从资源分配的角度优化迭代训练过程。
关键设计:论文的关键设计在于对不同预算分配策略的建模和分析。具体而言,论文考虑了恒定策略、多项式增长策略和指数增长策略,并分析了它们在不同条件下的收敛性。此外,论文还设计了相应的实验来验证理论分析的有效性,并比较了不同策略在实际任务中的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在图像去噪和数学推理任务中,指数增长策略始终优于恒定策略,并且通常提供更稳定的性能。例如,在图像去噪任务中,采用指数增长策略的模型相比于采用恒定策略的模型,性能提升了显著的百分比(具体数值未知,论文中应有详细数据)。这些实验结果验证了理论分析的有效性,并表明指数增长策略是一种有效的预算分配策略。
🎯 应用场景
该研究成果可广泛应用于各种需要迭代合成数据自举训练的场景,例如图像生成、自然语言处理和强化学习等领域。通过优化预算分配策略,可以显著提升模型的性能和训练效率,降低训练成本,加速模型开发周期。该研究对于推动人工智能技术的实际应用具有重要意义。
📄 摘要(原文)
Modern foundation models often undergo iterative ``bootstrapping'' in their post-training phase: a model generates synthetic data, an external verifier filters out low-quality samples, and the high-quality subset is used for further fine-tuning. Over multiple iterations, the model performance improves, raising a crucial question: How should the total budget for generation and training be allocated across iterations to maximize final performance? In this work, we develop a theoretical framework for analyzing budget allocation strategies. Specifically, we show that constant policies fail to converge with high probability, while increasing policies -- particularly exponential growth policies -- exhibit significant theoretical advantages. Experiments on image denoising with diffusion probabilistic models and math reasoning with large language models show that both exponential and polynomial growth policies consistently outperform constant policies, with exponential policies often providing more stable performance.