BRiTE: Bootstrapping Reinforced Thinking Process to Enhance Language Model Reasoning
作者: Han Zhong, Yutong Yin, Shenao Zhang, Xiaojun Xu, Yuanxin Liu, Yifei Zuo, Zhihan Liu, Boyi Liu, Sirui Zheng, Hongyi Guo, Liwei Wang, Mingyi Hong, Zhaoran Wang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-01-31 (更新: 2025-06-06)
备注: ICML 2025
💡 一句话要点
BRiTE:通过自举强化思维过程提升语言模型推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型推理 强化学习 自举学习 奖励塑造 概率模型
📋 核心要点
- 现有LLM在推理任务中面临挑战,难以生成可靠的推理过程,限制了其应用。
- BRiTE算法通过强化学习近似最优思维过程,并利用奖励塑造机制生成高质量的推理链。
- 实验表明,BRiTE在数学和编码基准上显著提升了LLM的性能,无需人工标注数据。
📝 摘要(中文)
大型语言模型(LLM)在复杂推理任务中表现出卓越的能力,但生成可靠的推理过程仍然是一个重大挑战。本文提出了一个统一的概率框架,通过一个包含潜在思维过程和评估信号的新型图模型来形式化LLM推理。在此框架内,我们引入了自举强化思维过程(BRiTE)算法,该算法分两步进行。首先,它通过强化学习近似最优思维过程,使用一种新颖的奖励塑造机制来生成高质量的理由。其次,它通过最大化关于模型参数的理由生成的联合概率来增强基础LLM。理论上,我们证明了BRiTE以1/T的速率收敛,其中T表示迭代次数。在数学和编码基准上的经验评估表明,我们的方法始终提高不同基础模型的性能,而不需要人工标注的思维过程。此外,与使用拒绝抽样等替代方法来引导思维过程的现有算法相比,BRiTE表现出卓越的性能,甚至可以匹配或超过通过人工标注数据进行监督微调所获得的结果。
🔬 方法详解
问题定义:现有大型语言模型在复杂推理任务中表现出色,但生成可靠的推理过程仍然是一个挑战。现有的方法,如直接生成或使用人工标注数据进行微调,要么难以保证推理过程的正确性,要么需要大量的人工标注成本。因此,如何有效地引导LLM生成高质量的推理过程,同时避免对人工标注数据的依赖,是本文要解决的关键问题。
核心思路:BRiTE的核心思路是利用强化学习来优化LLM的推理过程。具体来说,它将LLM的推理过程视为一个策略,通过与环境的交互(即推理任务)来学习最优的推理路径。为了加速学习过程,BRiTE引入了一种新颖的奖励塑造机制,该机制能够更有效地指导LLM生成高质量的推理链。此外,BRiTE还通过最大化理由生成的联合概率来增强基础LLM,从而进一步提升其推理能力。
技术框架:BRiTE算法包含两个主要步骤:1) 基于强化学习的理由生成;2) 基于概率模型的LLM增强。在理由生成阶段,BRiTE使用强化学习算法(如策略梯度)来优化LLM的推理策略。为了提高学习效率,BRiTE设计了一种奖励塑造机制,该机制根据推理过程的中间步骤和最终结果来给予奖励。在LLM增强阶段,BRiTE通过最大化理由生成的联合概率来微调LLM的参数。这可以通过梯度下降等优化算法来实现。
关键创新:BRiTE的关键创新在于其将强化学习与概率模型相结合,从而实现对LLM推理过程的有效引导和优化。与传统的监督学习方法相比,BRiTE无需人工标注的推理过程,而是通过与环境的交互来学习最优的推理策略。与现有的基于强化学习的方法相比,BRiTE引入了一种新颖的奖励塑造机制,该机制能够更有效地指导LLM生成高质量的推理链。
关键设计:BRiTE的关键设计包括:1) 奖励塑造机制:该机制根据推理过程的中间步骤和最终结果来给予奖励,以鼓励LLM生成更合理的推理链。具体的奖励函数可以根据不同的推理任务进行设计。2) 概率模型:BRiTE使用一个概率模型来描述LLM的推理过程,该模型可以用于计算理由生成的联合概率。3) 强化学习算法:BRiTE可以使用各种强化学习算法来优化LLM的推理策略,如策略梯度、Actor-Critic等。具体的算法选择可以根据不同的任务和模型进行调整。
🖼️ 关键图片
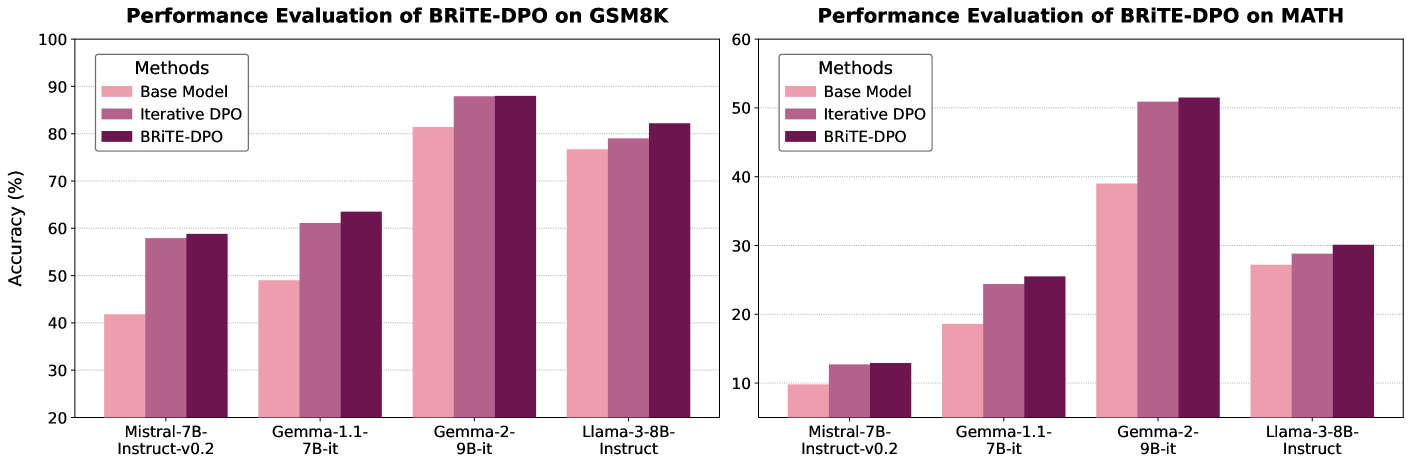
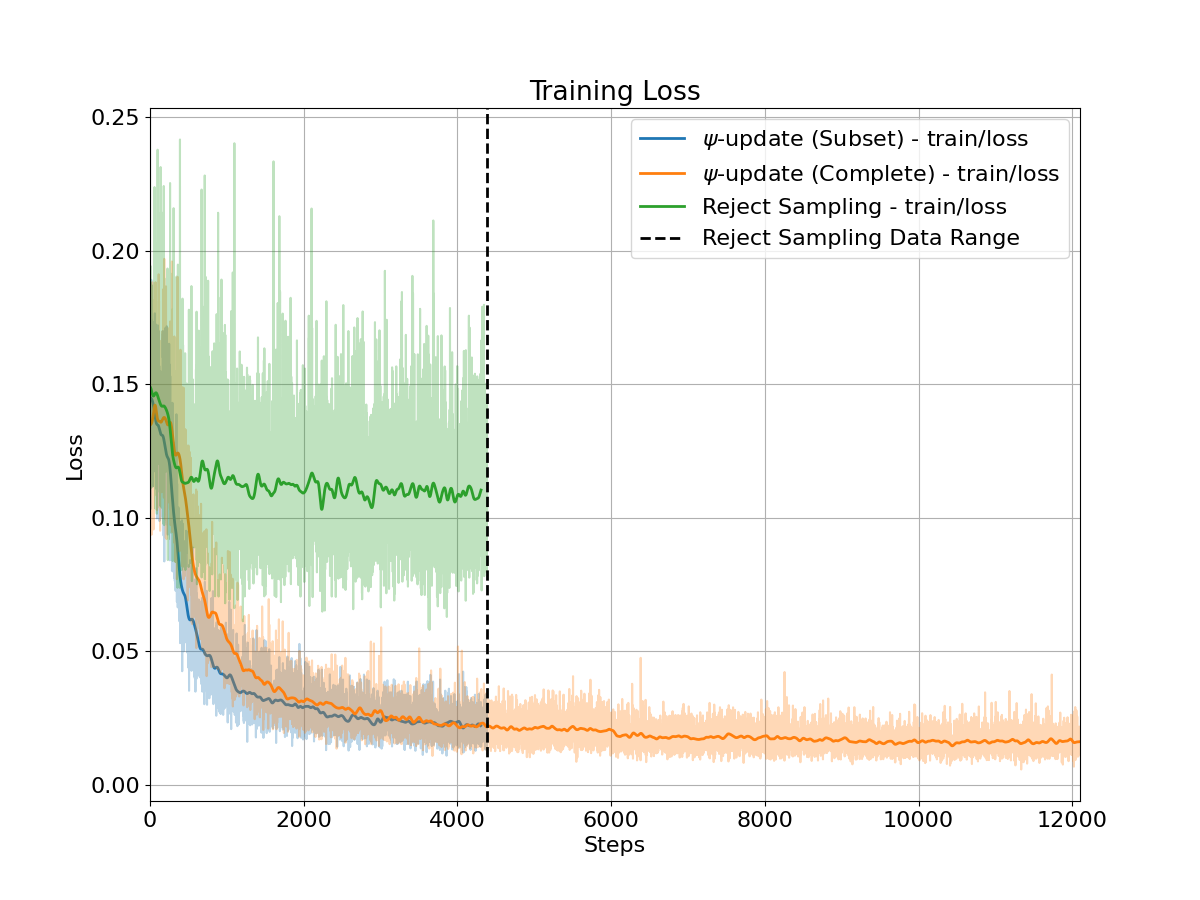

📊 实验亮点
实验结果表明,BRiTE算法在数学和编码基准上显著提升了LLM的性能。例如,在某些基准上,BRiTE算法的性能甚至可以匹配或超过通过人工标注数据进行监督微调所获得的结果。此外,BRiTE算法还表现出优于现有基于拒绝抽样的自举方法的性能,证明了其有效性和优越性。
🎯 应用场景
BRiTE算法具有广泛的应用前景,可以应用于各种需要复杂推理的任务,如数学问题求解、代码生成、知识图谱推理等。该算法可以提升LLM在这些任务上的性能,使其能够更好地解决实际问题。此外,BRiTE算法还可以用于开发更智能的对话系统和智能助手,使其能够更好地理解用户的意图并提供更准确的回答。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities in complex reasoning tasks, yet generating reliable reasoning processes remains a significant challenge. We present a unified probabilistic framework that formalizes LLM reasoning through a novel graphical model incorporating latent thinking processes and evaluation signals. Within this framework, we introduce the Bootstrapping Reinforced Thinking Process (BRiTE) algorithm, which works in two steps. First, it generates high-quality rationales by approximating the optimal thinking process through reinforcement learning, using a novel reward shaping mechanism. Second, it enhances the base LLM by maximizing the joint probability of rationale generation with respect to the model's parameters. Theoretically, we demonstrate BRiTE's convergence at a rate of $1/T$ with $T$ representing the number of iterations. Empirical evaluations on math and coding benchmarks demonstrate that our approach consistently improves performance across different base models without requiring human-annotated thinking processes. In addition, BRiTE demonstrates superior performance compared to existing algorithms that bootstrap thinking processes use alternative methods such as rejection sampling, and can even match or exceed the results achieved through supervised fine-tuning with human-annotated data.