Partially Rewriting a Transformer in Natural Language
作者: Gonçalo Paulo, Nora Belrose
分类: cs.LG, cs.CL
发布日期: 2025-01-31
💡 一句话要点
提出一种部分重写Transformer的方法,旨在用自然语言解释替换网络组件,提升模型可解释性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可解释性 Transformer 自然语言解释 大型语言模型 稀疏激活 神经元模拟 机械可解释性
📋 核心要点
- 机械可解释性的目标是用人类易于理解的形式重写深度神经网络,但现有方法难以在保持性能的同时实现。
- 该论文提出一种方法,使用自然语言解释来部分重写Transformer模型,通过LLM模拟神经元激活。
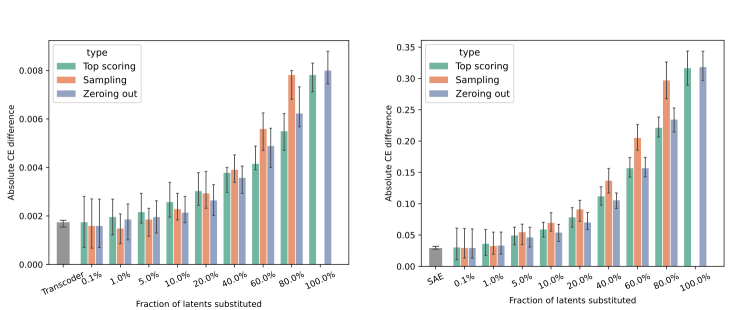
- 实验结果表明,当前方法引起的性能下降与直接移除对应模块相当,表明需要更精细的解释。
📝 摘要(中文)
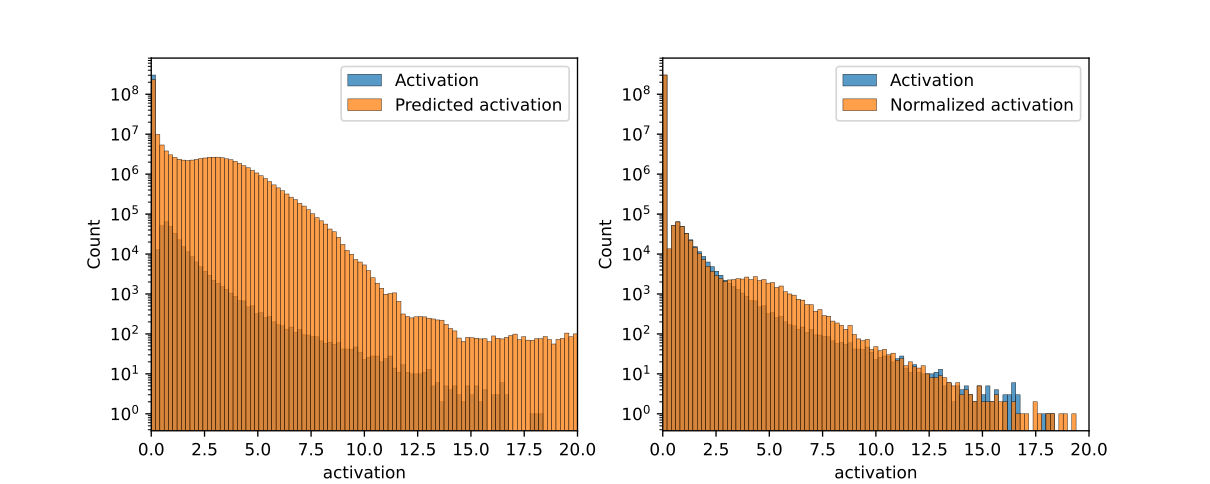
本文旨在通过自然语言解释部分重写大型语言模型,以提高其可理解性并保持性能。研究者首先使用一个更宽的、神经元稀疏激活的MLP(转码器)来近似LLM中的一个前馈网络,并利用自动可解释性流程为这些神经元生成解释。然后,他们用基于LLM的模拟器替换该稀疏MLP的第一层,该模拟器根据神经元的解释和上下文预测其激活。最后,他们评估这些修改对模型最终输出的影响。结果表明,该方法引起的损失增加与直接将稀疏MLP的输出替换为零向量在统计上相似。研究者还使用稀疏自编码器对同一层的残差流进行了类似实验,结果相似。这些结果表明,需要更详细的解释才能显著提高性能,使其超过零消融基线。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)可解释性差的问题。现有方法难以将LLM内部的复杂计算过程转化为人类可理解的形式,这限制了我们对模型行为的理解和控制。直接修改或替换模型组件可能导致性能显著下降,因此需要一种在保持性能的同时提高可解释性的方法。
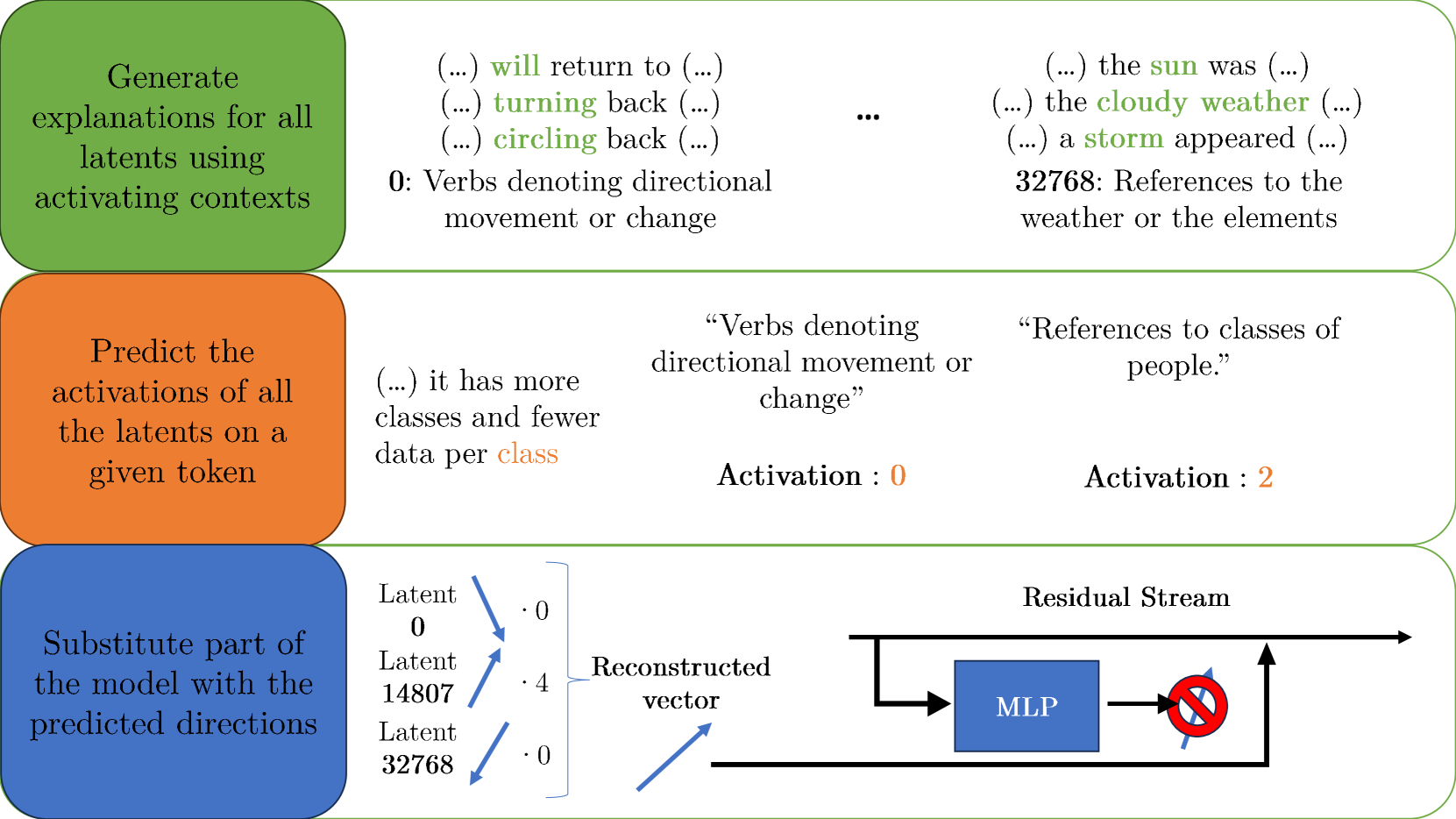
核心思路:论文的核心思路是用自然语言解释来表示LLM中的部分组件,并使用另一个LLM来模拟这些组件的行为。具体来说,首先将LLM中的一个前馈网络用一个稀疏激活的MLP(转码器)来近似,然后为该MLP的神经元生成自然语言解释。接着,使用一个LLM作为模拟器,根据神经元的解释和上下文来预测其激活值。最后,用模拟器的输出替换原始MLP的输出,并评估对模型性能的影响。这种方法的目的是将复杂的数值计算转化为基于自然语言的推理过程,从而提高模型的可解释性。
技术框架:整体框架包含以下几个主要步骤: 1. 转码器训练:使用一个更宽的、神经元稀疏激活的MLP(转码器)来近似LLM中的一个前馈网络。 2. 解释生成:利用自动可解释性流程为转码器中的神经元生成自然语言解释。 3. 模拟器训练:训练一个基于LLM的模拟器,该模拟器以神经元的解释和上下文作为输入,预测其激活值。 4. 组件替换:用模拟器的输出替换原始MLP的输出。 5. 性能评估:评估替换后的模型性能,并与基线模型进行比较。
关键创新:该论文的关键创新在于使用自然语言解释作为连接LLM内部组件和外部可解释性工具的桥梁。通过将神经元的激活与自然语言解释联系起来,可以将复杂的数值计算转化为基于自然语言的推理过程。此外,使用LLM作为模拟器,可以利用LLM强大的语言理解和生成能力,从而更准确地模拟神经元的行为。
关键设计: * 稀疏激活的MLP(转码器):使用稀疏激活的MLP可以减少需要解释的神经元数量,从而降低解释生成的难度。 * 自动可解释性流程:使用自动可解释性流程可以自动化生成神经元的自然语言解释,从而提高效率。 * 基于LLM的模拟器:使用LLM作为模拟器可以利用LLM强大的语言理解和生成能力,从而更准确地模拟神经元的行为。 * 损失函数:使用交叉熵损失函数来训练模拟器,目标是最小化预测激活值与实际激活值之间的差异。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用自然语言解释替换Transformer模型中的部分组件后,模型性能的下降与直接移除这些组件相当。具体来说,模型损失的增加与将稀疏MLP的输出替换为零向量在统计上相似。这表明,当前方法生成的自然语言解释的质量仍有待提高,需要更详细、更准确的解释才能显著提升模型的可解释性和性能。
🎯 应用场景
该研究成果可应用于提高大型语言模型的可解释性和可控性。通过将模型内部的计算过程转化为人类可理解的自然语言解释,可以帮助研究人员和开发者更好地理解模型的行为,并进行有针对性的修改和优化。此外,该方法还可以用于构建更安全、更可靠的AI系统,例如,可以利用自然语言解释来检测和纠正模型中的偏差和错误。
📄 摘要(原文)
The greatest ambition of mechanistic interpretability is to completely rewrite deep neural networks in a format that is more amenable to human understanding, while preserving their behavior and performance. In this paper, we attempt to partially rewrite a large language model using simple natural language explanations. We first approximate one of the feedforward networks in the LLM with a wider MLP with sparsely activating neurons - a transcoder - and use an automated interpretability pipeline to generate explanations for these neurons. We then replace the first layer of this sparse MLP with an LLM-based simulator, which predicts the activation of each neuron given its explanation and the surrounding context. Finally, we measure the degree to which these modifications distort the model's final output. With our pipeline, the model's increase in loss is statistically similar to entirely replacing the sparse MLP output with the zero vector. We employ the same protocol, this time using a sparse autoencoder, on the residual stream of the same layer and obtain similar results. These results suggest that more detailed explanations are needed to improve performance substantially above the zero ablation baseline.