Deceptive Sequential Decision-Making via Regularized Policy Optimization
作者: Yerin Kim, Alexander Benvenuti, Bo Chen, Mustafa Karabag, Abhishek Kulkarni, Nathaniel D. Bastian, Ufuk Topcu, Matthew Hale
分类: cs.LG, math.OC
发布日期: 2025-01-30 (更新: 2025-08-20)
备注: 16 pages, 3 figures
💡 一句话要点
提出基于正则化策略优化的欺骗性序列决策框架,应对逆强化学习攻击。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 欺骗性决策 逆强化学习 策略优化 正则化 对抗环境
📋 核心要点
- 现有自主系统易受攻击者通过观察系统行为推断敏感信息,缺乏有效的防御机制。
- 论文提出通过正则化策略优化,主动欺骗攻击者,使其对系统奖励产生错误认知。
- 实验表明,提出的欺骗策略能有效误导攻击者,同时保持接近最优的累积奖励。
📝 摘要(中文)
本文提出了一种欺骗性序列决策框架,旨在对抗通过观察系统行为来推断敏感信息的对抗者。我们将自主系统建模为马尔可夫决策过程,并假设对抗者使用逆强化学习来推断奖励函数。为了对抗这种威胁,我们提出了三种针对策略综合问题的正则化策略,这些策略能够主动地欺骗对抗者,使其对系统的奖励产生错误的认知。这三种策略分别是“转移性欺骗”、“目标性欺骗”和“模棱两可的欺骗”。我们展示了如何在策略优化问题中实现每种形式的欺骗,并从理论上界定了欺骗所导致的累积奖励损失。最后,我们在多智能体环境中评估了这些方法,结果表明,这三种欺骗策略都能够有效地引导对抗者产生错误的信念,同时仍然能够获得至少为其最优非欺骗值的97%的累积奖励。
🔬 方法详解
问题定义:论文旨在解决自主系统在对抗环境中,如何防止攻击者通过观察系统行为,使用逆强化学习推断出系统的真实奖励函数的问题。现有方法缺乏主动欺骗机制,使得攻击者能够相对容易地推断出敏感信息,从而对系统构成威胁。
核心思路:论文的核心思路是通过在策略优化过程中引入正则化项,使得学习到的策略不仅能够最大化真实奖励,同时也能诱导攻击者相信一个虚假的奖励函数。这种欺骗性策略能够误导攻击者,使其无法准确推断出系统的真实目标。
技术框架:该框架基于马尔可夫决策过程(MDP)建模自主系统,并假设攻击者使用逆强化学习(IRL)来估计奖励函数。核心模块包括:1) 真实环境的MDP建模;2) 逆强化学习攻击模型;3) 正则化策略优化,包含三种欺骗策略(转移性、目标性、模棱两可);4) 性能评估,包括欺骗效果和奖励损失。
关键创新:论文的关键创新在于提出了三种不同的欺骗策略,每种策略都旨在以不同的方式误导攻击者。转移性欺骗旨在使攻击者得出任何错误的结论;目标性欺骗旨在使攻击者得出特定的错误结论;模棱两可的欺骗旨在使攻击者认为真实奖励和虚假奖励都能解释系统的行为。
关键设计:论文的关键设计包括:1) 正则化项的设计,用于衡量策略与虚假奖励函数下最优策略的相似度;2) 损失函数的设计,需要在最大化真实奖励和欺骗攻击者之间进行权衡;3) 针对不同欺骗策略,正则化项的具体形式有所不同,例如,目标性欺骗需要指定一个特定的虚假奖励函数。
🖼️ 关键图片
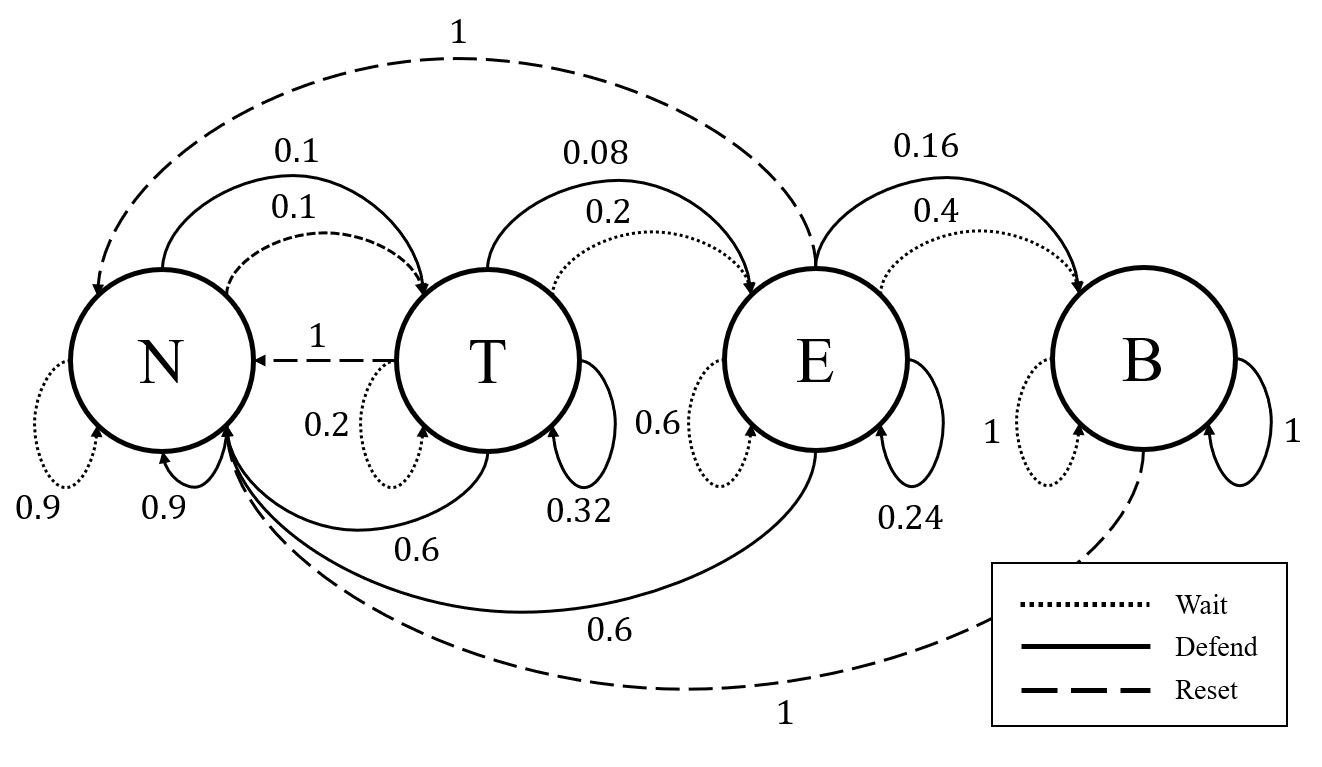
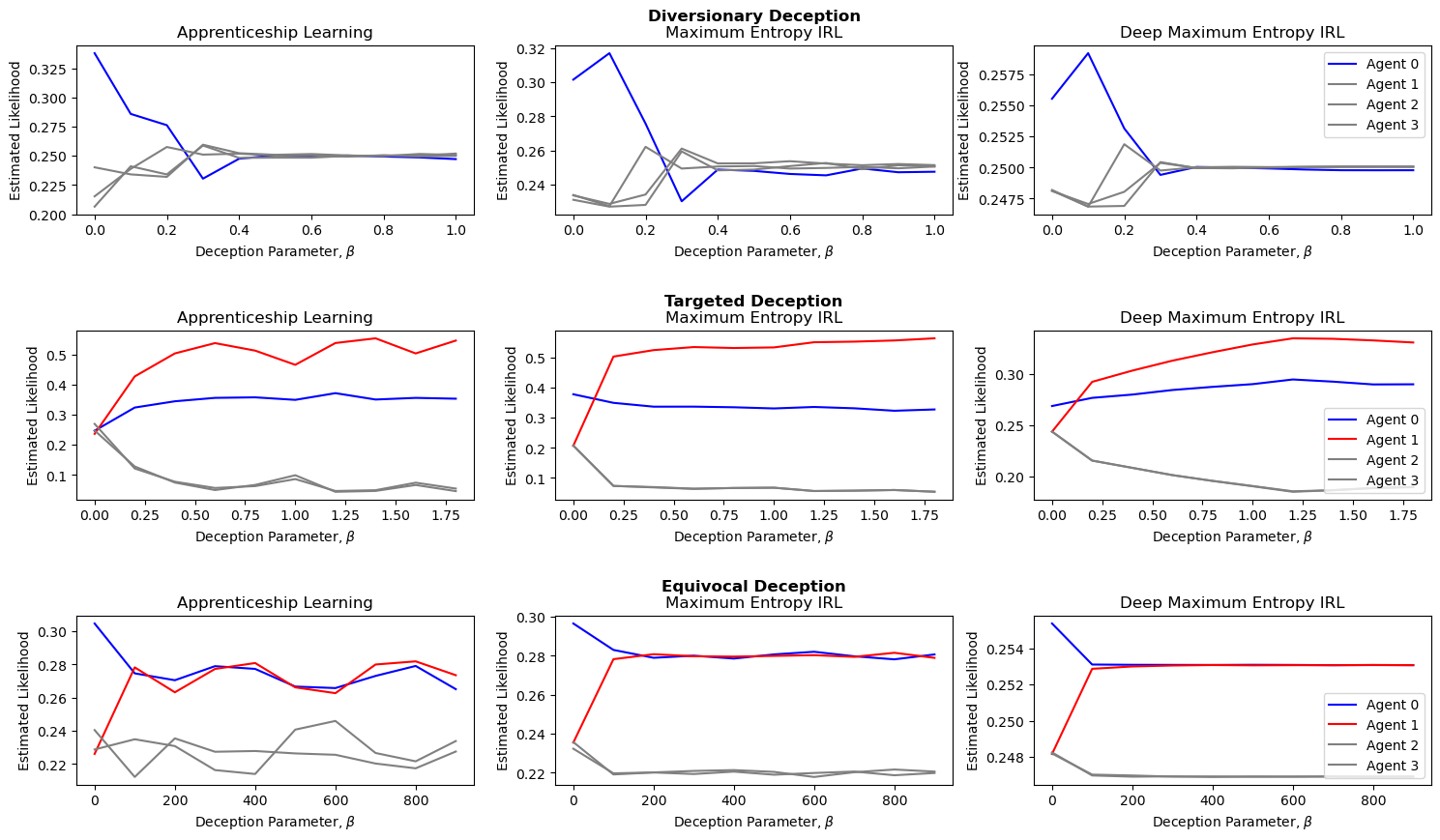
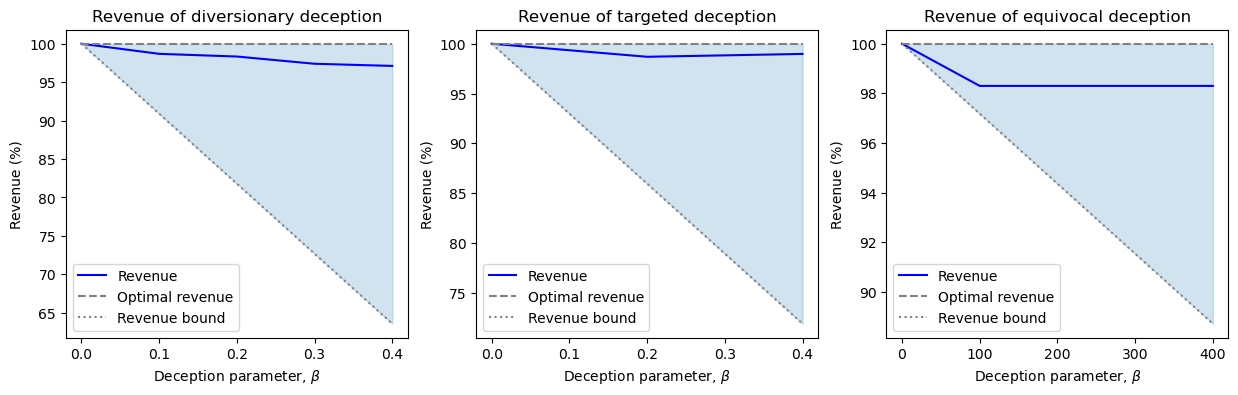
📊 实验亮点
实验结果表明,提出的三种欺骗策略(转移性、目标性、模棱两可)都能够有效地引导攻击者产生错误的信念。更重要的是,这些欺骗策略在实现欺骗的同时,仍然能够保持较高的性能,累积奖励至少达到最优非欺骗值的97%。这表明该方法能够在安全性和性能之间取得良好的平衡。
🎯 应用场景
该研究成果可应用于各种需要在对抗环境中运行的自主系统,例如自动驾驶、机器人导航、网络安全等。通过主动欺骗潜在的攻击者,可以有效保护系统的敏感信息,提高系统的安全性和鲁棒性。未来的研究可以探索更复杂的欺骗策略,以及在更复杂的对抗环境中的应用。
📄 摘要(原文)
Autonomous systems are increasingly expected to operate in the presence of adversaries, though adversaries may infer sensitive information simply by observing a system. Therefore, present a deceptive sequential decision-making framework that not only conceals sensitive information, but actively misleads adversaries about it. We model autonomous systems as Markov decision processes, with adversaries using inverse reinforcement learning to recover reward functions. To counter them, we present three regularization strategies for policy synthesis problems that actively deceive an adversary about a system's reward.
Diversionary deception'' leads an adversary to draw any false conclusion about the system's reward function.Targeted deception'' leads an adversary to draw a specific false conclusion about the system's reward function. ``Equivocal deception'' leads an adversary to infer that the real reward and a false reward both explain the system's behavior. We show how each form of deception can be implemented in policy optimization problems and analytically bound the loss in total accumulated reward induced by deception. Next, we evaluate these developments in a multi-agent setting. We show that diversionary, targeted, and equivocal deception all steer the adversary to false beliefs while still attaining a total accumulated reward that is at least 97% of its optimal, non-deceptive value.