CLoQ: Enhancing Fine-Tuning of Quantized LLMs via Calibrated LoRA Initialization
作者: Yanxia Deng, Aozhong Zhang, Selcuk Gurses, Naigang Wang, Zi Yang, Penghang Yin
分类: cs.LG, cs.AI
发布日期: 2025-01-30 (更新: 2025-08-14)
期刊: Transactions on Machine Learning Research (TMLR), 2025
💡 一句话要点
CLoQ:通过校准LoRA初始化增强量化LLM的微调效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量化 大语言模型 LoRA 微调 模型压缩 低比特量化 校准初始化
📋 核心要点
- 量化LLM的LoRA微调面临精度降低的挑战,现有方法难以有效适应量化权重。
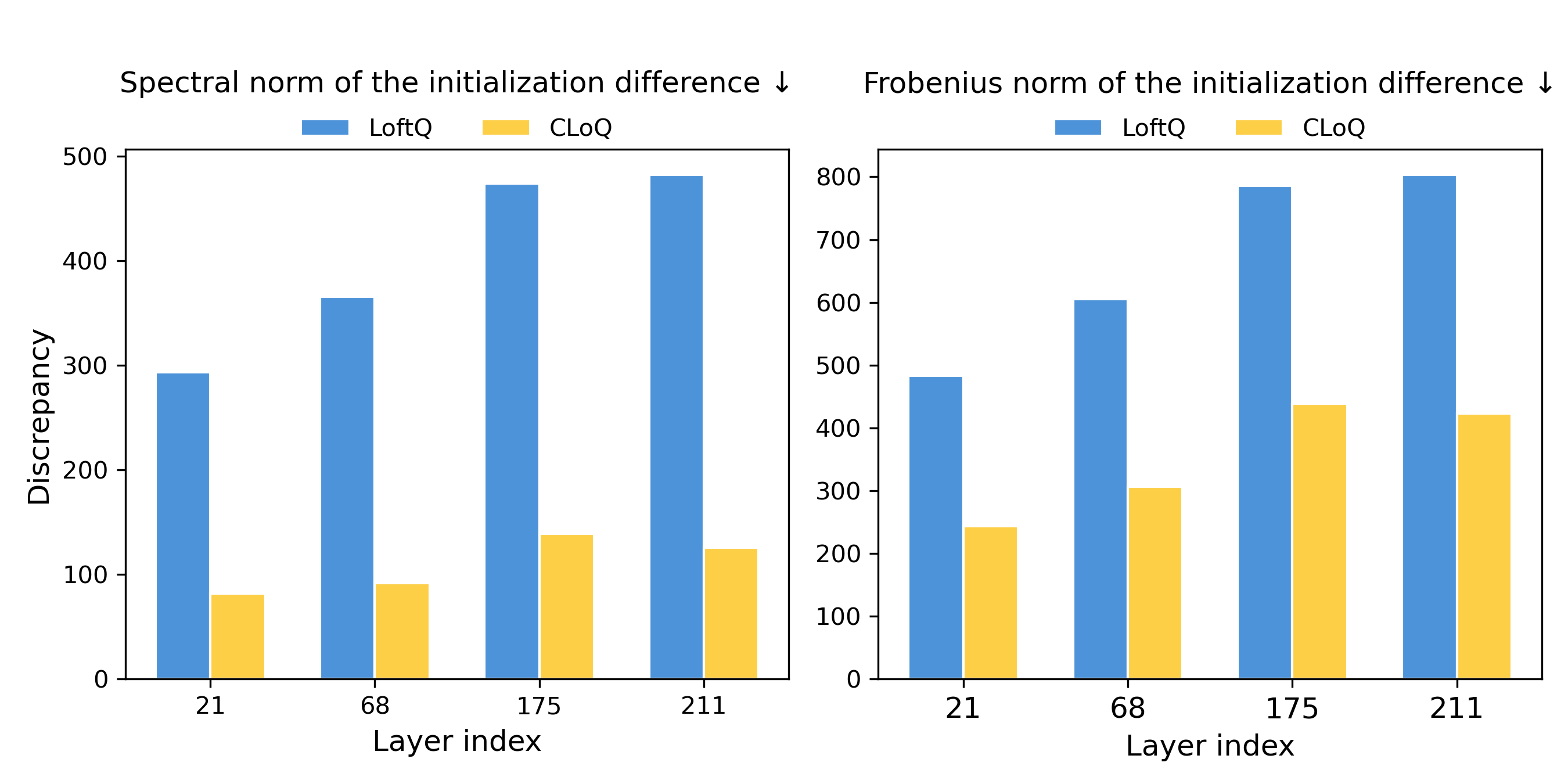
- CLoQ通过校准LoRA初始化,最小化原始模型和量化模型之间的差异,为后续微调提供更好的起点。
- 实验证明,CLoQ在多个任务上优于现有LoRA微调方法,尤其在超低比特宽度下性能提升显著。
📝 摘要(中文)
本文提出CLoQ(Calibrated LoRA initialization for Quantized LLMs),一种简易的初始化策略,旨在克服量化LLM中LoRA微调的挑战。该方法专注于最小化原始LLM及其带有LoRA组件的量化版本在初始化时的层间差异。CLoQ利用小型校准数据集量化预训练LLM,并确定每层的最优LoRA组件,为后续微调奠定坚实基础。本文的一个关键贡献是提出了一个新颖的理论结果,能够准确且以闭式解的形式构建这些最优LoRA组件。实验结果表明,CLoQ在语言生成、算术推理和常识推理等多个任务中,始终优于现有的量化LLM的LoRA微调方法,尤其是在超低比特宽度下。
🔬 方法详解
问题定义:论文旨在解决量化大语言模型(LLM)在使用LoRA进行微调时遇到的精度损失问题。由于量化操作降低了模型的表示能力,直接应用LoRA可能导致微调效果不佳,尤其是在超低比特量化的情况下。现有方法通常忽略了量化对LoRA初始化带来的影响,导致微调过程难以收敛到最优解。
核心思路:CLoQ的核心思路是在LoRA初始化阶段,通过校准LoRA参数,最小化原始LLM和量化LLM之间的差异。具体来说,CLoQ旨在找到一组LoRA参数,使得将这些参数添加到量化后的LLM后,其输出尽可能接近原始LLM的输出。这样做的目的是为后续的微调提供一个更好的起点,从而提高量化LLM的微调效果。
技术框架:CLoQ的整体框架包括以下几个步骤:1) 使用一个小的校准数据集;2) 量化预训练的LLM;3) 使用校准数据集,针对每一层,计算最优的LoRA参数,以最小化原始LLM和量化LLM之间的输出差异;4) 使用校准后的LoRA参数初始化量化LLM,并进行后续的微调。
关键创新:CLoQ的关键创新在于提出了一个理论结果,该结果允许以闭式解的形式计算最优的LoRA参数。这意味着可以直接计算出最优的LoRA参数,而无需通过迭代优化。这种方法不仅提高了计算效率,而且保证了LoRA参数的最优性。
关键设计:CLoQ的关键设计包括:1) 使用均方误差(MSE)作为损失函数,衡量原始LLM和量化LLM之间的输出差异;2) 推导出了一个闭式解,用于计算最小化MSE的LoRA参数;3) 针对每一层独立地进行LoRA参数的校准,以适应不同层的量化误差。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CLoQ在语言生成、算术推理和常识推理等多个任务上,显著优于现有的量化LLM的LoRA微调方法。尤其是在超低比特宽度(例如,2比特或3比特)下,CLoQ的性能提升更为明显。例如,在某些任务上,CLoQ可以将量化LLM的性能提升到接近甚至超过原始LLM的水平。
🎯 应用场景
CLoQ技术可应用于资源受限场景下的大语言模型部署,例如移动设备、边缘计算等。通过降低模型大小和计算复杂度,CLoQ使得在这些平台上运行高性能LLM成为可能。此外,该技术还可以应用于对模型大小和能耗有严格要求的应用场景,例如嵌入式系统和物联网设备。
📄 摘要(原文)
Fine-tuning large language models (LLMs) using low-rank adaptation (LoRA) has become a highly efficient approach for downstream tasks, particularly in scenarios with limited computational resources. However, applying LoRA techniques to quantized LLMs poses unique challenges due to the reduced representational precision of quantized weights. In this paper, we introduce CLoQ (Calibrated LoRA initialization for Quantized LLMs), a simplistic initialization strategy designed to overcome these challenges. Our approach focuses on minimizing the layer-wise discrepancy between the original LLM and its quantized counterpart with LoRA components during initialization. By leveraging a small calibration dataset, CLoQ quantizes a pre-trained LLM and determines the optimal LoRA components for each layer, ensuring a strong foundation for subsequent fine-tuning. A key contribution of this work is a novel theoretical result that enables the accurate and closed-form construction of these optimal LoRA components. We validate the efficacy of CLoQ across multiple tasks such as language generation, arithmetic reasoning, and commonsense reasoning, demonstrating that it consistently outperforms existing LoRA fine-tuning methods for quantized LLMs, especially at ultra low-bit widths.