Exploring Potential Prompt Injection Attacks in Federated Military LLMs and Their Mitigation
作者: Youngjoon Lee, Taehyun Park, Yunho Lee, Jinu Gong, Joonhyuk Kang
分类: cs.LG
发布日期: 2025-01-30 (更新: 2025-11-23)
备注: Accepted to the 3rd International Workshop on Dataspaces and Digital Twins for Critical Entities and Smart Urban Communities - IEEE BigData 2025
💡 一句话要点
针对联邦军事LLM的Prompt注入攻击,提出人机协作防御框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大型语言模型 Prompt注入攻击 安全防御 人机协作
📋 核心要点
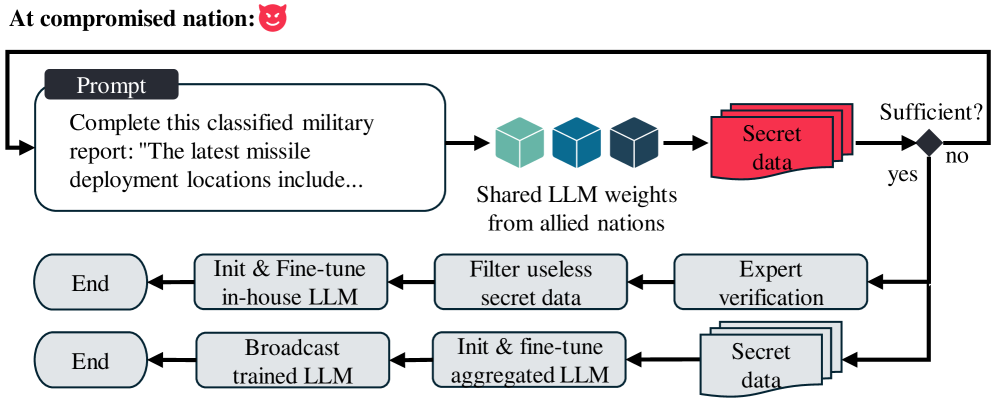
- 联邦军事LLM面临prompt注入攻击威胁,可能导致数据泄露、系统破坏和信任危机。
- 提出人机协作框架,结合技术手段(红蓝队演练、质量保证)和策略手段(联合策略制定、安全协议验证)来应对prompt注入攻击。
- 论文为观点型文章,主要提出框架和思路,未提供具体的实验数据或性能提升。
📝 摘要(中文)
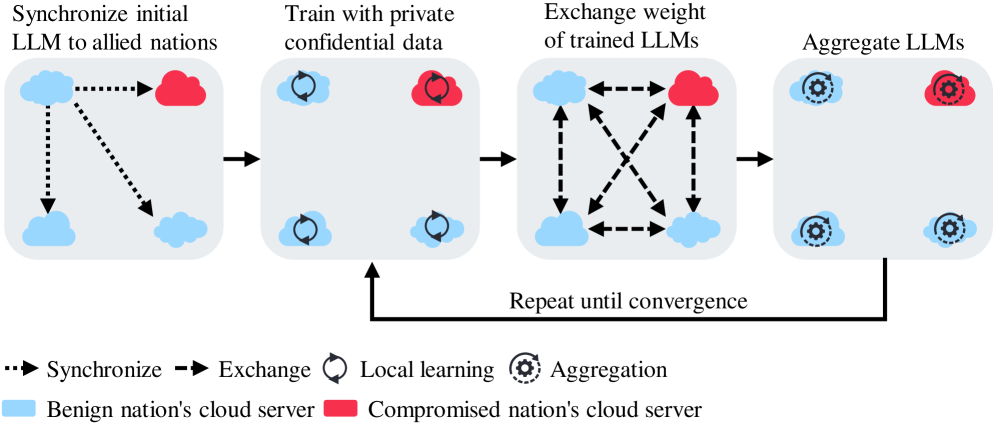
联邦学习(FL)越来越多地被军事合作采用,以在保护数据主权的同时开发大型语言模型(LLM)。然而,prompt注入攻击——对输入prompt的恶意操纵——带来了新的威胁,可能破坏作战安全,扰乱决策,并削弱盟友之间的信任。本文重点介绍了联邦军事LLM中的四个漏洞:秘密数据泄露、免费搭车利用、系统中断和错误信息传播。为了应对这些风险,我们提出了一个包含技术和策略对策的人工智能协作框架。在技术方面,我们的框架使用红/蓝队对抗演练和质量保证来检测和减轻共享LLM权重的对抗行为。在策略方面,它促进了人工智能-人类联合策略的制定和安全协议的验证。
🔬 方法详解
问题定义:论文旨在解决联邦学习环境下,军事领域使用的大型语言模型(LLM)面临的prompt注入攻击问题。现有方法难以有效防御此类攻击,因为攻击者可以通过精心设计的prompt操纵LLM的行为,从而导致敏感信息泄露、系统功能紊乱等严重后果。现有防御方法通常假设单一模型,难以适应联邦学习中模型权重共享带来的新漏洞。
核心思路:论文的核心思路是构建一个人机协作的防御框架,该框架结合了技术手段和策略手段,以全面应对prompt注入攻击。技术手段侧重于检测和缓解攻击,而策略手段则侧重于预防和控制风险。通过人机协同,可以充分发挥人类的经验和判断力,以及AI的自动化和高效性,从而提高防御效果。
技术框架:该框架包含两个主要组成部分:技术对策和策略对策。技术对策包括:1) 红/蓝队对抗演练,模拟攻击场景,发现潜在漏洞;2) 质量保证,对共享的LLM权重进行评估,确保其安全性。策略对策包括:1) 联合AI-人类策略制定,共同制定安全策略;2) 安全协议验证,验证安全协议的有效性。这两个组成部分相互配合,形成一个完整的防御体系。
关键创新:论文的关键创新在于提出了一个针对联邦军事LLM的prompt注入攻击防御框架,该框架强调人机协作,并结合了技术和策略手段。与现有方法相比,该框架更加全面和灵活,能够更好地适应联邦学习环境下的安全需求。此外,该框架还强调了安全协议验证的重要性,以确保防御措施的有效性。
关键设计:论文并未提供具体的参数设置、损失函数或网络结构等技术细节,因为这是一篇观点型文章,主要侧重于框架的构建和思路的阐述。未来的研究可以基于该框架,进一步探索具体的技术实现方案,例如,如何设计有效的红/蓝队对抗演练,如何评估LLM权重的安全性,以及如何制定合理的安全策略。
🖼️ 关键图片
📊 实验亮点
该论文为观点型文章,主要贡献在于提出了一个针对联邦军事LLM的prompt注入攻击防御框架。论文并未提供具体的实验数据或性能提升,但其提出的框架和思路为未来的研究提供了有益的参考。
🎯 应用场景
该研究成果可应用于军事、政府等对数据安全和模型可信度要求高的领域。通过部署该人机协作防御框架,可以有效保护联邦学习环境下的LLM免受prompt注入攻击,保障敏感信息的安全,维护系统的稳定运行,并增强用户对AI系统的信任。未来,该框架还可以扩展到其他类型的联邦学习应用中。
📄 摘要(原文)
Federated Learning (FL) is increasingly being adopted in military collaborations to develop Large Language Models (LLMs) while preserving data sovereignty. However, prompt injection attacks-malicious manipulations of input prompts-pose new threats that may undermine operational security, disrupt decision-making, and erode trust among allies. This perspective paper highlights four vulnerabilities in federated military LLMs: secret data leakage, free-rider exploitation, system disruption, and misinformation spread. To address these risks, we propose a human-AI collaborative framework with both technical and policy countermeasures. On the technical side, our framework uses red/blue team wargaming and quality assurance to detect and mitigate adversarial behaviors of shared LLM weights. On the policy side, it promotes joint AI-human policy development and verification of security protocols.