Large Language Models for Cryptocurrency Transaction Analysis: A Bitcoin Case Study
作者: Yuchen Lei, Yuexin Xiang, Qin Wang, Rafael Dowsley, Tsz Hon Yuen, Kim-Kwang Raymond Choo, Jiangshan Yu
分类: cs.CR, cs.LG
发布日期: 2025-01-30 (更新: 2025-09-04)
💡 一句话要点
提出LLM4TG框架,利用大语言模型分析比特币交易图,提升网络犯罪检测能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 加密货币交易分析 比特币 图神经网络 网络犯罪检测 可解释性 LLM4TG CETraS
📋 核心要点
- 现有加密货币交易分析方法依赖黑盒模型,缺乏可解释性,难以捕捉细微行为模式,限制了网络犯罪检测能力。
- 提出LLM4TG框架,结合连接性增强采样CETraS算法,降低LLM分析交易图的token需求,提升分析效率。
- 实验表明,LLM在交易图分析中表现出色,节点识别准确率超过98.50%,分类top-3准确率达到72.43%(含解释)。
📝 摘要(中文)
加密货币被广泛使用,但当前交易分析方法通常依赖不透明的黑盒模型。这些模型虽然性能高,但输出难以解释和调整,难以捕捉细微的行为模式。大型语言模型(LLM)有潜力解决这些问题,但其在网络犯罪检测等领域的应用仍未被充分探索。本文通过将LLM应用于真实的加密货币交易图(以比特币为例)来验证这一假设。我们提出了一个三层框架来评估LLM的能力:基础指标、特征概述和上下文解释。该框架包括一种新的、人类可读的图表示格式LLM4TG,以及一种连接性增强的交易图采样算法CETraS。它们显著降低了token需求,使得利用LLM分析多个中等规模的交易图成为可能。实验结果表明,LLM在基础指标和特征概述方面表现出色,节点级别识别准确率超过98.50%,获得有意义特征的比例达到95.00%。在上下文解释方面,LLM在分类任务中也表现出强大的性能,即使在非常有限的标记数据下,top-3准确率也达到了72.43%,并能给出解释。虽然解释并不总是完全准确,但突出了LLM在该领域的巨大潜力。同时,仍然存在一些局限性,我们在文中讨论了这些局限性以及未来的研究方向。
🔬 方法详解
问题定义:现有加密货币交易分析方法,特别是用于检测网络犯罪的,依赖于黑盒模型,这些模型虽然可能具有较高的预测准确率,但缺乏可解释性。这使得理解模型的决策过程、调整模型以适应新的犯罪模式以及在法律和监管环境中应用这些模型变得困难。此外,现有方法难以捕捉交易行为中细微的模式和上下文信息。
核心思路:利用大型语言模型(LLM)强大的自然语言处理和推理能力,将加密货币交易图转换为LLM可以理解的文本表示,然后利用LLM进行分析和推理。核心在于将图结构数据转化为文本数据,并设计合适的提示工程(prompt engineering)来引导LLM完成特定的分析任务。
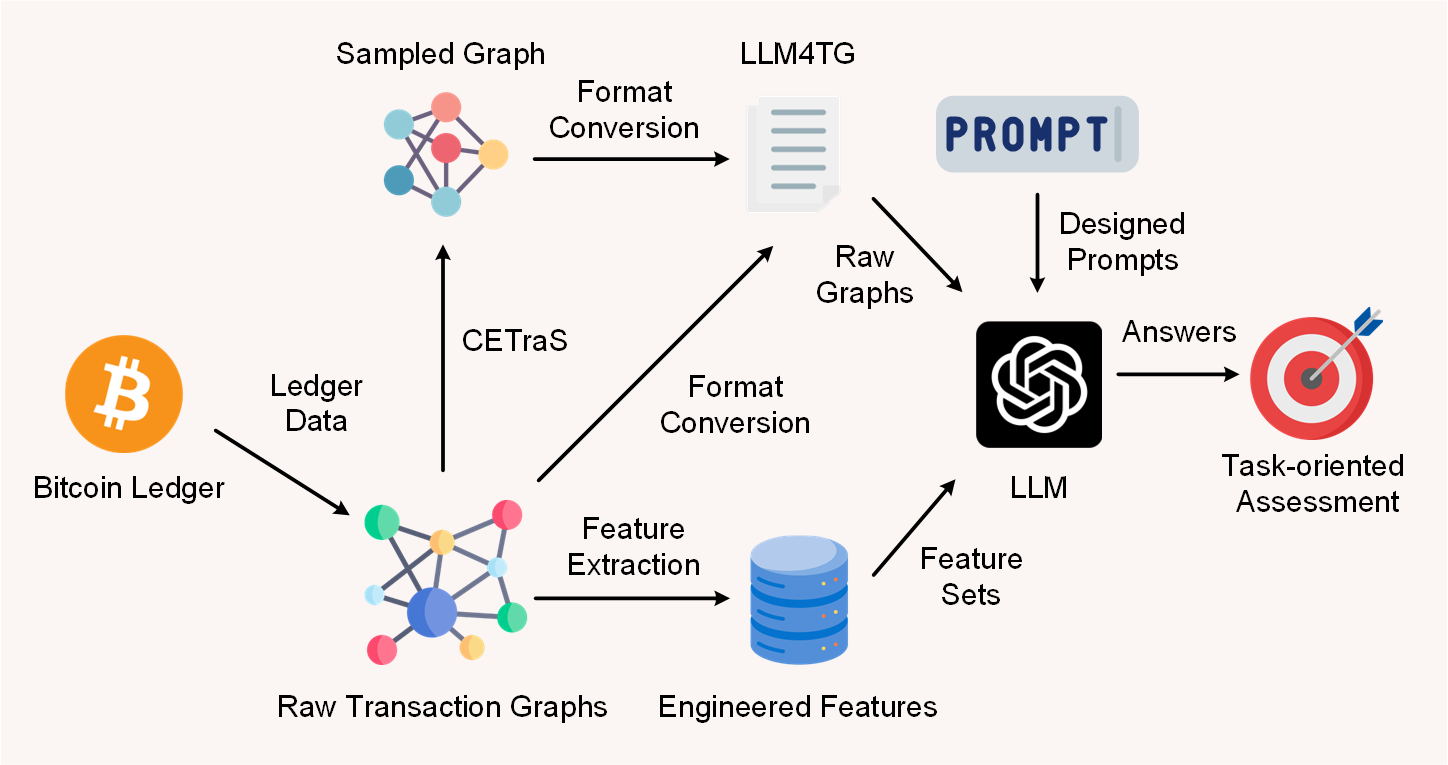
技术框架:该论文提出了一个三层框架,包括:1) 基础指标评估:评估LLM识别节点基本信息的能力;2) 特征概述:评估LLM提取交易图中关键特征的能力;3) 上下文解释:评估LLM在分类任务中进行推理和提供解释的能力。为了支持这个框架,论文还提出了LLM4TG图表示格式和CETraS采样算法。整体流程是:首先使用CETraS对交易图进行采样,然后使用LLM4TG将采样后的图转换为文本表示,最后将文本输入LLM进行分析。
关键创新:关键创新在于将LLM应用于加密货币交易图分析,并提出了LLM4TG这种人类可读的图表示格式,以及CETraS连接性增强的交易图采样算法。LLM4TG使得LLM能够更好地理解交易图的结构和语义信息,而CETraS则能够在保证图结构完整性的前提下,显著降低token需求,使得LLM能够处理更大规模的交易图。与现有方法相比,该方法具有更强的可解释性和灵活性。
关键设计:LLM4TG是一种人类可读的图表示格式,它将交易图中的节点和边表示为文本,并包含节点的属性信息(如交易金额、时间戳等)和边的连接关系。CETraS是一种连接性增强的交易图采样算法,它优先选择具有较高连接度的节点进行采样,以保证采样后的图能够保留原始图的关键结构信息。论文中使用了GPT-3.5和GPT-4等LLM,并设计了针对不同分析任务的提示工程(prompt engineering),例如,对于分类任务,提示工程包括任务描述、输入示例和输出格式等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM在基础指标和特征概述方面表现出色,节点级别识别准确率超过98.50%,获得有意义特征的比例达到95.00%。在上下文解释方面,即使在非常有限的标记数据下,LLM在分类任务中的top-3准确率也达到了72.43%,并能给出解释。这些结果表明LLM在加密货币交易分析领域具有巨大的潜力。
🎯 应用场景
该研究成果可应用于加密货币交易监控、反洗钱、网络犯罪检测等领域。通过利用LLM的可解释性和推理能力,可以更有效地识别和预防非法交易活动,提升金融安全。未来,该方法还可以扩展到其他类型的图数据分析,例如社交网络分析、知识图谱推理等。
📄 摘要(原文)
Cryptocurrencies are widely used, yet current methods for analyzing transactions often rely on opaque, black-box models. While these models may achieve high performance, their outputs are usually difficult to interpret and adapt, making it challenging to capture nuanced behavioral patterns. Large language models (LLMs) have the potential to address these gaps, but their capabilities in this area remain largely unexplored, particularly in cybercrime detection. In this paper, we test this hypothesis by applying LLMs to real-world cryptocurrency transaction graphs, with a focus on Bitcoin, one of the most studied and widely adopted blockchain networks. We introduce a three-tiered framework to assess LLM capabilities: foundational metrics, characteristic overview, and contextual interpretation. This includes a new, human-readable graph representation format, LLM4TG, and a connectivity-enhanced transaction graph sampling algorithm, CETraS. Together, they significantly reduce token requirements, transforming the analysis of multiple moderately large-scale transaction graphs with LLMs from nearly impossible to feasible under strict token limits. Experimental results demonstrate that LLMs have outstanding performance on foundational metrics and characteristic overview, where the accuracy of recognizing most basic information at the node level exceeds 98.50% and the proportion of obtaining meaningful characteristics reaches 95.00%. Regarding contextual interpretation, LLMs also demonstrate strong performance in classification tasks, even with very limited labeled data, where top-3 accuracy reaches 72.43% with explanations. While the explanations are not always fully accurate, they highlight the strong potential of LLMs in this domain. At the same time, several limitations persist, which we discuss along with directions for future research.