Fault Localization via Fine-tuning Large Language Models with Mutation Generated Stack Traces
作者: Neetha Jambigi, Bartosz Bogacz, Moritz Mueller, Thomas Bach, Michael Felderer
分类: cs.SE, cs.LG
发布日期: 2025-01-29 (更新: 2025-02-11)
备注: I do not have the necessary approvals to out the paper on Arxiv from my organization yet. I was too soon to do this
💡 一句话要点
通过微调大型语言模型与变异生成的堆栈跟踪来实现故障定位
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 故障定位 大型语言模型 代码变异 堆栈跟踪 软件崩溃
📋 核心要点
- 现有故障定位方法依赖测试失败或源代码,在生产环境仅有崩溃日志和堆栈跟踪时失效。
- 利用代码变异生成大量合成崩溃数据,微调大型语言模型,仅基于堆栈跟踪定位故障根源。
- 实验表明,该方法在HANA、SQLite和DuckDB上均优于基线,准确率分别达到66.9%、63%和74%。
📝 摘要(中文)
软件的突然和意外终止被称为软件崩溃。分析这些崩溃可能具有挑战性。找到根本原因需要大量的人工努力和专业知识来连接堆栈跟踪、源代码和日志等信息源。典型的故障定位方法需要测试失败或源代码。在生产环境中发生的崩溃,例如SAP HANA的崩溃,仅提供崩溃日志和堆栈跟踪。我们提出了一种新颖的方法,仅基于堆栈跟踪信息来定位故障,无需额外的运行时信息,通过微调大型语言模型(LLM)。我们解决了复杂的情况,即崩溃的根本原因与技术原因不同,并且不在堆栈跟踪的最内层帧中。由于历史崩溃的数量不足以微调LLM,我们通过利用代码变异器将合成崩溃注入到代码库中来扩充我们的数据集。通过对由HANA代码库的410万次变异产生的64,369次崩溃进行微调,我们可以正确预测崩溃的根本原因位置,准确率为66.9%,而基线方法仅达到12.6%和10.6%。我们通过在另外两个开源数据库SQLite和DuckDB上进行评估来证实我们方法的通用性,分别实现了63%和74%的准确率。在我们所有的实验中,微调始终优于提示非微调的LLM,以定位我们数据集中的故障。
🔬 方法详解
问题定义:论文旨在解决生产环境中软件崩溃后,仅有堆栈跟踪信息的情况下,如何准确快速地定位导致崩溃的根本原因。现有方法依赖于测试用例或源代码,无法直接应用于此类场景。此外,崩溃的根本原因可能不在堆栈跟踪的最内层,增加了定位难度。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的代码理解和推理能力,通过微调使其能够从堆栈跟踪中推断出导致崩溃的根本原因。为了解决训练数据不足的问题,采用代码变异技术生成大量的合成崩溃数据,用于LLM的微调。
技术框架:整体框架包括以下几个主要阶段:1)代码变异:使用代码变异器在代码库中注入各种错误,模拟真实崩溃场景。2)崩溃生成:运行变异后的代码,生成包含堆栈跟踪的崩溃日志。3)数据增强:将生成的崩溃日志和对应的根本原因位置作为训练数据,扩充数据集。4)模型微调:使用扩充后的数据集微调大型语言模型。5)故障定位:将实际崩溃的堆栈跟踪输入微调后的LLM,预测根本原因位置。
关键创新:该方法最重要的创新点在于:1)利用代码变异技术生成合成崩溃数据,解决了训练数据不足的问题。2)提出了一种仅基于堆栈跟踪信息,无需额外运行时信息即可定位故障的方法。3)通过微调LLM,使其能够处理根本原因不在堆栈跟踪最内层的情况。
关键设计:论文的关键设计包括:1)选择合适的代码变异器,以生成具有代表性的崩溃场景。2)设计有效的提示工程(prompt engineering),引导LLM学习堆栈跟踪与根本原因之间的关系。3)选择合适的LLM架构和微调策略,以获得最佳的故障定位性能。具体参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

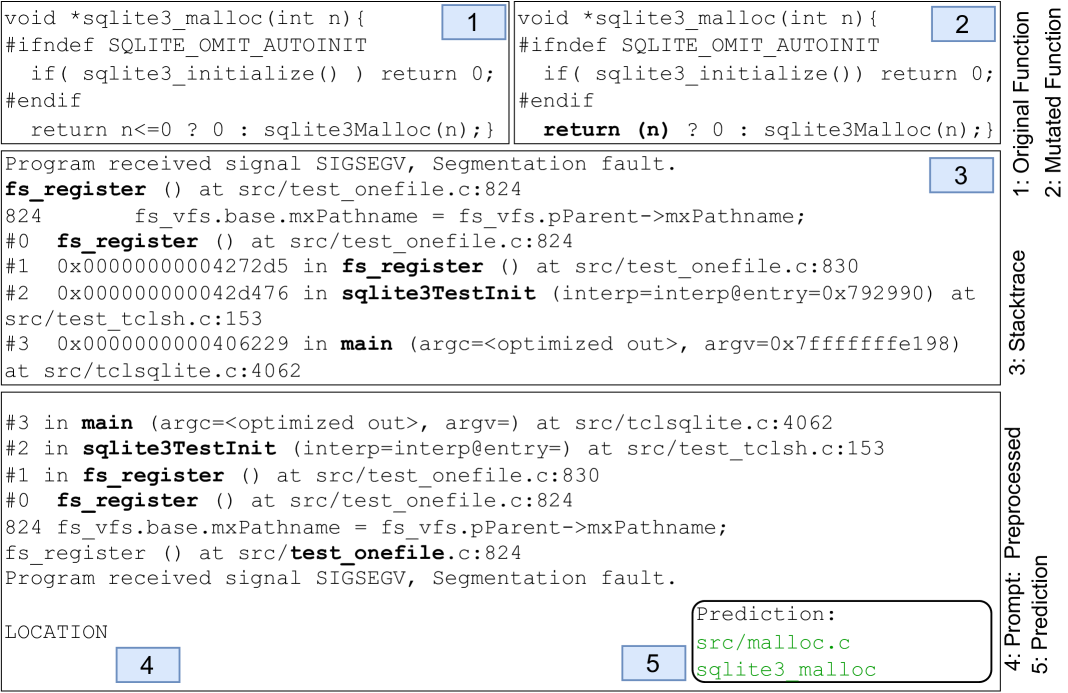
📊 实验亮点
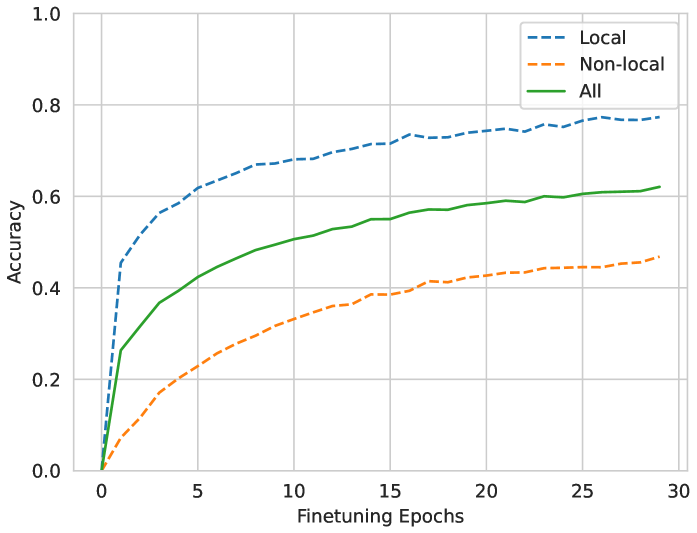
实验结果表明,通过在HANA代码库的410万次变异产生的64,369次崩溃数据上进行微调,该方法可以正确预测崩溃的根本原因位置,准确率为66.9%,而基线方法仅达到12.6%和10.6%。在SQLite和DuckDB上的评估也取得了显著的成果,分别实现了63%和74%的准确率。微调始终优于提示非微调的LLM。
🎯 应用场景
该研究成果可应用于软件开发和维护的各个阶段,尤其是在生产环境中快速定位和修复软件崩溃。通过自动化故障定位,可以显著减少人工分析工作量,缩短修复时间,提高软件质量和可靠性。未来可扩展到其他类型的软件系统和编程语言。
📄 摘要(原文)
Abrupt and unexpected terminations of software are termed as software crashes. They can be challenging to analyze. Finding the root cause requires extensive manual effort and expertise to connect information sources like stack traces, source code, and logs. Typical approaches to fault localization require either test failures or source code. Crashes occurring in production environments, such as that of SAP HANA, provide solely crash logs and stack traces. We present a novel approach to localize faults based only on the stack trace information and no additional runtime information, by fine-tuning large language models (LLMs). We address complex cases where the root cause of a crash differs from the technical cause, and is not located in the innermost frame of the stack trace. As the number of historic crashes is insufficient to fine-tune LLMs, we augment our dataset by leveraging code mutators to inject synthetic crashes into the code base. By fine-tuning on 64,369 crashes resulting from 4.1 million mutations of the HANA code base, we can correctly predict the root cause location of a crash with an accuracy of 66.9\% while baselines only achieve 12.6% and 10.6%. We substantiate the generalizability of our approach by evaluating on two additional open-source databases, SQLite and DuckDB, achieving accuracies of 63% and 74%, respectively. Across all our experiments, fine-tuning consistently outperformed prompting non-finetuned LLMs for localizing faults in our datasets.