DReSS: Data-driven Regularized Structured Streamlining for Large Language Models
作者: Mingkuan Feng, Jinyang Wu, Shuai Zhang, Pengpeng Shao, Ruihan Jin, Zhengqi Wen, Jianhua Tao, Feihu Che
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-01-29 (更新: 2025-06-29)
💡 一句话要点
DReSS:数据驱动的正则化结构化精简方法,用于高效压缩大型语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型剪枝 正则化 数据驱动 模型压缩 结构化精简 低延迟 高吞吐量
📋 核心要点
- 现有LLM剪枝方法采用“先剪枝后微调”范式,直接移除参数导致信息损失,微调成本高昂。
- DReSS 提出“正则化-剪枝-微调”新范式,利用少量数据正则化待剪枝参数,提前转移重要信息。
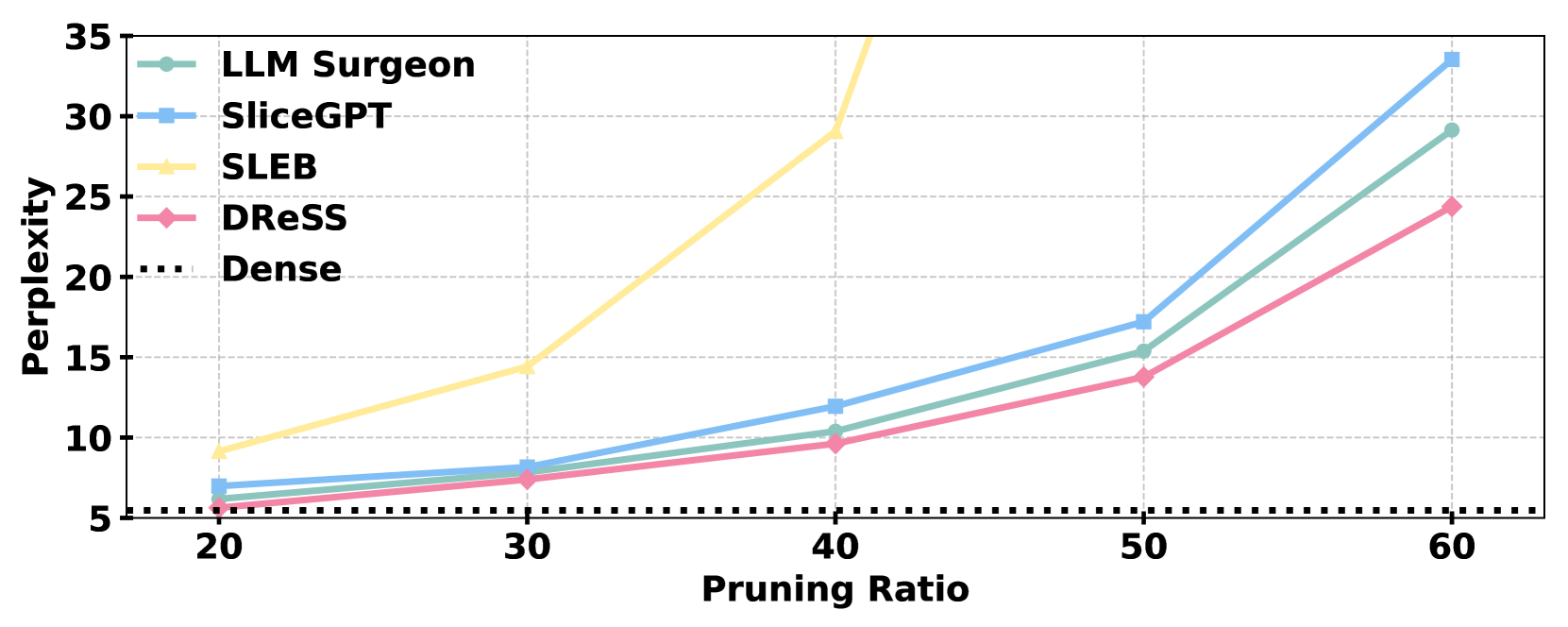
- 实验表明,DReSS 在高剪枝率下显著优于现有方法,降低延迟并提高吞吐量。
📝 摘要(中文)
大型语言模型(LLMs)在各个领域取得了显著进展,但其不断增长的规模导致了高昂的计算和内存成本。最近的研究表明,LLMs 具有稀疏性,为通过剪枝技术减小模型尺寸提供了可能。然而,现有的剪枝方法通常遵循先剪枝后微调的范式。由于被剪枝的组件仍然包含有价值的信息,直接移除它们往往会导致不可逆转的性能下降,从而给微调期间的性能恢复带来巨大的计算负担。在本文中,我们提出了一种新的范式,即首先应用正则化,然后进行剪枝,最后进行微调。基于此范式,我们引入了 DReSS,一种简单而有效的数据驱动的正则化结构化精简方法,用于 LLMs。通过利用少量数据来正则化要剪枝的组件,DReSS 提前将重要的信息显式地转移到模型的剩余部分。与直接剪枝相比,这可以减少因参数移除而造成的信息损失,从而增强其语言建模能力。实验结果表明,即使在极端的剪枝率下,DReSS 也明显优于现有的剪枝方法,从而显著降低了延迟并提高了吞吐量。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)剪枝过程中,直接移除参数导致的信息损失和后续微调成本高昂的问题。现有方法通常采用“先剪枝后微调”的范式,忽略了被剪枝部分所包含的有用信息,导致性能下降,需要大量的计算资源进行微调才能恢复性能。
核心思路:DReSS 的核心思路是在剪枝之前,先通过数据驱动的正则化方法,将待剪枝部分的重要信息迁移到模型的剩余部分。这样,即使剪枝后,模型也能保留大部分关键信息,从而减少性能损失,降低后续微调的难度和计算成本。
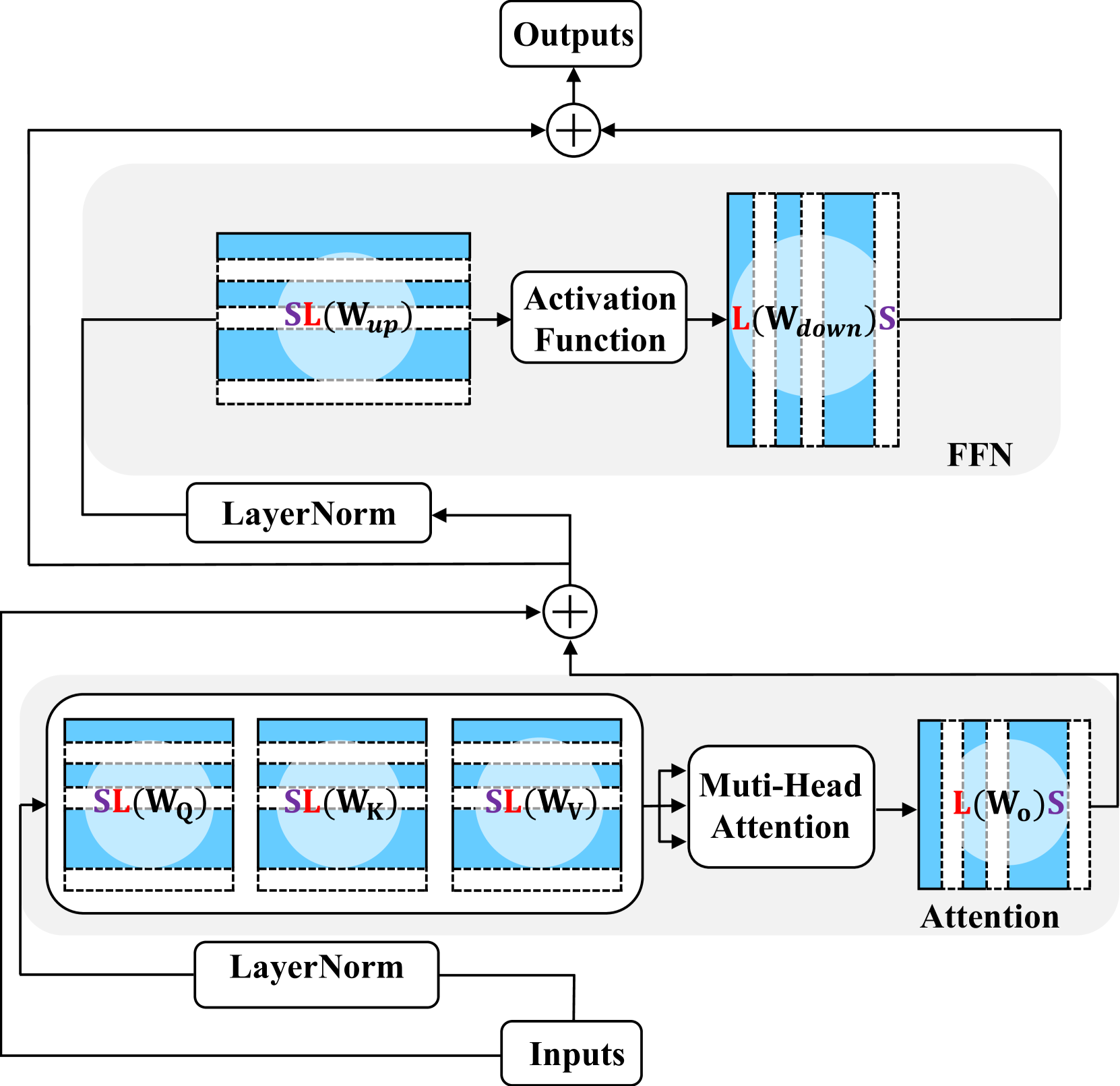
技术框架:DReSS 包含三个主要阶段:1) 正则化阶段:利用少量数据,通过特定的正则化策略,促使待剪枝部分的参数学习到剩余部分参数的信息。2) 剪枝阶段:根据预设的剪枝策略,移除正则化后的部分参数。3) 微调阶段:对剪枝后的模型进行微调,进一步提升性能。
关键创新:DReSS 的关键创新在于提出了“正则化-剪枝-微调”的新范式。与传统的“先剪枝后微调”方法相比,DReSS 通过正则化步骤,显式地将信息从待剪枝部分转移到剩余部分,从而减少了剪枝带来的信息损失。这种方法能够更有效地保留模型的语言建模能力,并降低微调的计算负担。
关键设计:DReSS 的关键设计包括:1) 数据驱动的正则化策略:使用少量数据来指导正则化过程,确保正则化能够有效地将重要信息迁移到剩余参数。2) 结构化剪枝:采用结构化剪枝方法,例如剪枝整个神经元或通道,以保证剪枝后的模型结构规整,易于部署和加速。3) 损失函数设计:损失函数包含正则化项,用于约束待剪枝参数的学习过程,促使其将信息传递给剩余参数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DReSS 在各种剪枝率下均优于现有的剪枝方法。即使在极高的剪枝率下,DReSS 也能保持较好的性能,并显著降低延迟和提高吞吐量。具体性能数据在论文中给出,与基线方法相比,DReSS 在语言建模任务上取得了显著的性能提升。
🎯 应用场景
DReSS 具有广泛的应用前景,可用于在资源受限的设备上部署大型语言模型,例如移动设备、嵌入式系统等。通过降低模型的计算和内存成本,DReSS 能够使 LLMs 在这些设备上实现高效的推理,从而为各种应用场景提供支持,例如智能助手、机器翻译、文本摘要等。此外,DReSS 还可以用于加速 LLMs 的训练和推理,提高开发效率。
📄 摘要(原文)
Large language models (LLMs) have achieved significant progress across various domains, but their increasing scale results in high computational and memory costs. Recent studies have revealed that LLMs exhibit sparsity, providing the potential to reduce model size through pruning techniques. However, existing pruning methods typically follow a prune-then-finetune paradigm. Since the pruned components still contain valuable information, their direct removal often leads to irreversible performance degradation, imposing a substantial computational burden to recover performance during finetuning. In this paper, we propose a novel paradigm that first applies regularization, then prunes, and finally finetunes. Based on this paradigm, we introduce DReSS, a simple and effective Data-driven Regularized Structured Streamlining method for LLMs. By leveraging a small amount of data to regularize the components to be pruned, DReSS explicitly transfers the important information to the remaining parts of the model in advance. Compared to direct pruning, this can reduce the information loss caused by parameter removal, thereby enhancing its language modeling capabilities. Experimental results demonstrate that DReSS significantly outperforms existing pruning methods even under extreme pruning ratios, significantly reducing latency and increasing throughput.