Temperature-Free Loss Function for Contrastive Learning
作者: Bum Jun Kim, Sang Woo Kim
分类: cs.LG
发布日期: 2025-01-29
备注: 10 pages, 5 figures
💡 一句话要点
提出一种无温度超参数的对比学习损失函数,提升梯度特性并简化调参。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 对比学习 自监督学习 InfoNCE损失 无超参数 反双曲正切函数
📋 核心要点
- InfoNCE损失在对比学习中依赖温度超参数,该参数对性能至关重要,但调优过程耗时且困难。
- 论文提出用反双曲正切函数替代温度缩放,改进InfoNCE损失,实现无温度超参数的对比学习。
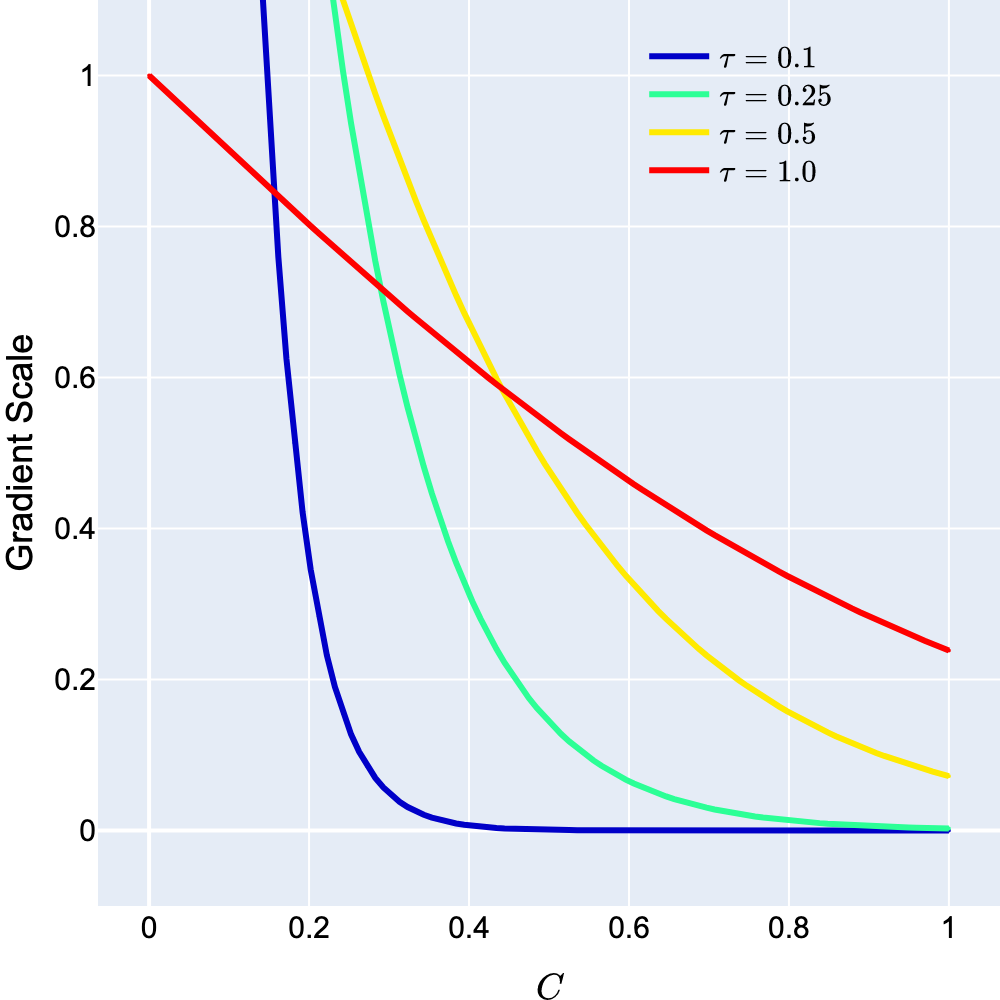
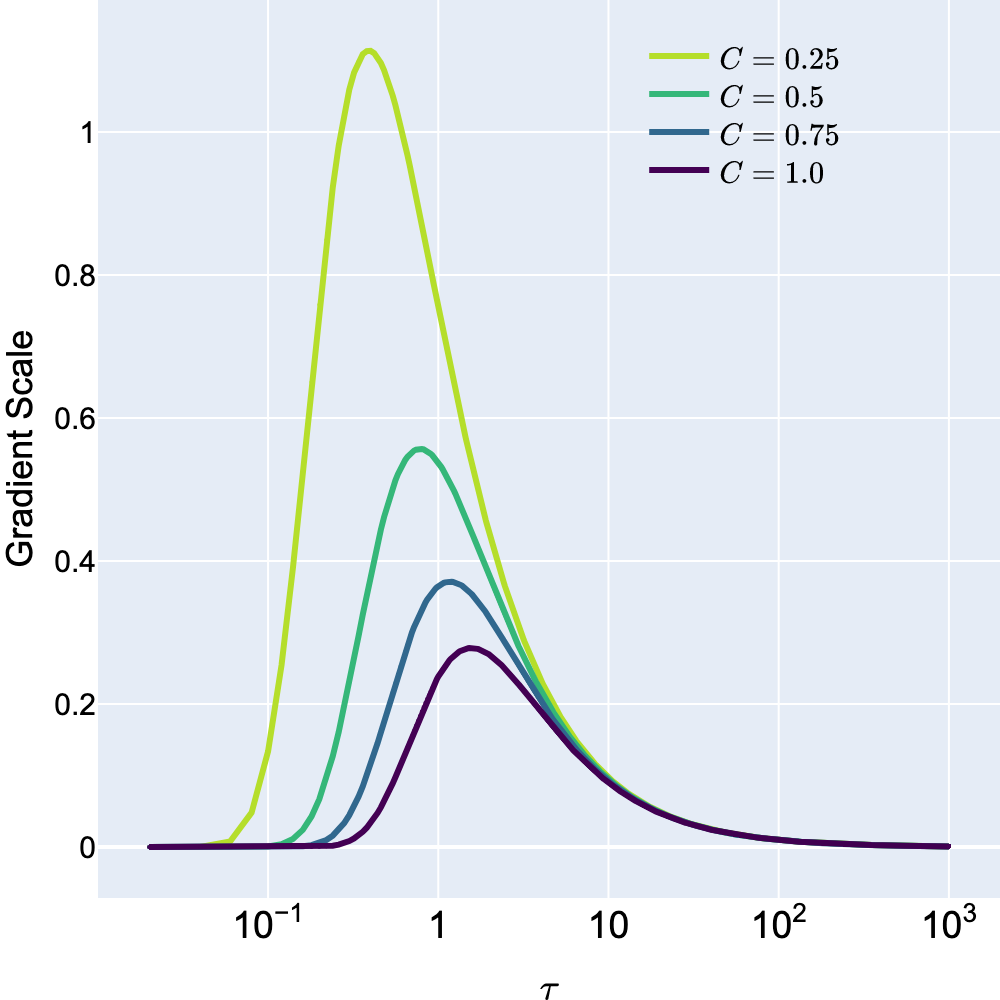
- 实验表明,该方法不仅无需调参,还能提升对比学习性能,理论分析揭示了其优越的梯度特性。
📝 摘要(中文)
对比学习作为一种极具前景的自监督学习方法,已经在众多领域取得了一系列突破。InfoNCE损失是实现对比学习的一种主要方法:通过捕获样本对之间的相似性,InfoNCE损失能够学习数据的表示。尽管InfoNCE损失取得了成功,但它需要调整温度参数,这是一个用于校准相似度得分的核心超参数。尽管其重要性和对性能的敏感性已被多项研究强调,但寻找有效的温度参数需要大量的试错实验,这增加了采用InfoNCE损失的难度。为了解决这个难题,我们提出了一种无需温度参数即可部署InfoNCE损失的新方法。具体来说,我们用反双曲正切函数代替温度缩放,从而得到一个改进的InfoNCE损失。除了无超参数部署之外,我们还观察到所提出的方法甚至提高了对比学习的性能。我们详细的理论分析发现,当前InfoNCE损失中的温度缩放实践会导致梯度下降中的严重问题,而我们的方法提供了理想的梯度特性。所提出的方法在对比学习的五个基准上进行了验证,无需温度调整即可产生令人满意的结果。
🔬 方法详解
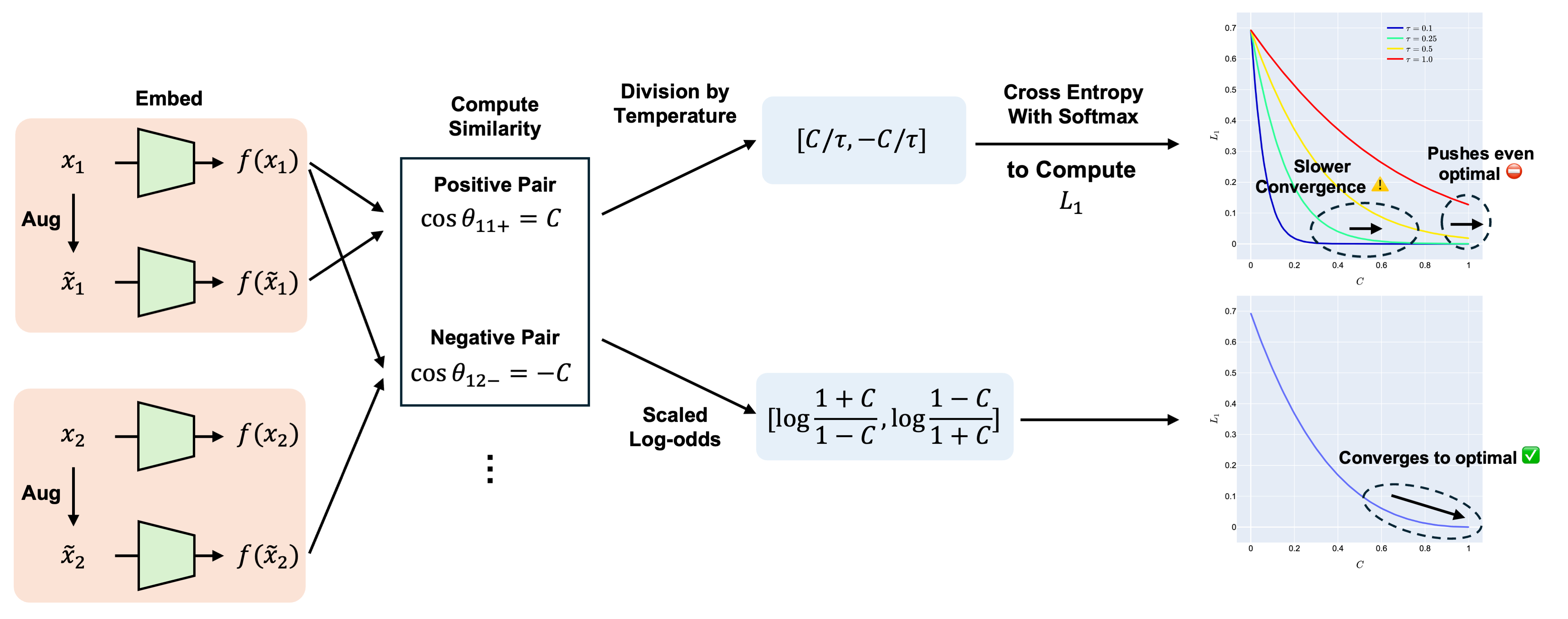
问题定义:现有对比学习方法,特别是基于InfoNCE损失的方法,依赖于一个名为“温度”的超参数来缩放相似度得分。这个温度参数对最终模型的性能有很大影响,但找到一个合适的温度值需要大量的实验和调优,增加了使用对比学习的复杂性和计算成本。现有方法的痛点在于温度参数的敏感性和调优的困难。
核心思路:论文的核心思路是用反双曲正切函数(inverse hyperbolic tangent function)来替代InfoNCE损失中的温度缩放。反双曲正切函数具有将相似度得分映射到(-1, 1)区间的特性,并且可以自适应地调整相似度得分的分布,从而避免了手动调整温度参数的需要。这种设计旨在解决温度参数调优困难的问题,并提升模型的泛化能力。
技术框架:该方法主要涉及对InfoNCE损失函数的修改。首先,计算样本对之间的相似度得分(例如,通过点积)。然后,将这些相似度得分输入到反双曲正切函数中进行变换。最后,使用变换后的相似度得分计算改进的InfoNCE损失。整体流程与标准的对比学习框架类似,但关键在于用反双曲正切函数替代了温度缩放这一步骤。
关键创新:最重要的技术创新点是用反双曲正切函数替代温度缩放。与现有方法相比,该方法无需手动调整温度参数,从而简化了对比学习的流程。此外,理论分析表明,该方法能够提供更理想的梯度特性,有助于优化模型的训练过程。本质区别在于,现有方法依赖于一个固定的温度值来缩放相似度得分,而该方法则使用一个自适应的函数来变换相似度得分。
关键设计:关键设计在于反双曲正切函数的选择和应用。具体来说,论文使用tanh⁻¹(s),其中s是样本对之间的相似度得分。这个函数将相似度得分映射到(-1, 1)区间,并且具有非线性的特性,可以自适应地调整相似度得分的分布。损失函数采用修改后的InfoNCE损失,其中相似度得分经过反双曲正切函数变换。网络结构方面,可以使用任何标准的对比学习网络结构,例如ResNet等。
🖼️ 关键图片
📊 实验亮点
该方法在五个对比学习基准测试中取得了令人满意的结果,无需进行温度调整。实验结果表明,在某些情况下,该方法甚至可以超越经过精心调优的传统InfoNCE损失。这表明该方法不仅简化了对比学习的流程,还提高了模型的性能。
🎯 应用场景
该研究成果可广泛应用于各种需要自监督学习的场景,如图像识别、自然语言处理、语音识别等。尤其适用于资源有限或需要快速部署的场景,因为无需耗时的温度参数调优。该方法有望降低对比学习的使用门槛,促进其在更多实际问题中的应用,并加速相关领域的研究进展。
📄 摘要(原文)
As one of the most promising methods in self-supervised learning, contrastive learning has achieved a series of breakthroughs across numerous fields. A predominant approach to implementing contrastive learning is applying InfoNCE loss: By capturing the similarities between pairs, InfoNCE loss enables learning the representation of data. Albeit its success, adopting InfoNCE loss requires tuning a temperature, which is a core hyperparameter for calibrating similarity scores. Despite its significance and sensitivity to performance being emphasized by several studies, searching for a valid temperature requires extensive trial-and-error-based experiments, which increases the difficulty of adopting InfoNCE loss. To address this difficulty, we propose a novel method to deploy InfoNCE loss without temperature. Specifically, we replace temperature scaling with the inverse hyperbolic tangent function, resulting in a modified InfoNCE loss. In addition to hyperparameter-free deployment, we observed that the proposed method even yielded a performance gain in contrastive learning. Our detailed theoretical analysis discovers that the current practice of temperature scaling in InfoNCE loss causes serious problems in gradient descent, whereas our method provides desirable gradient properties. The proposed method was validated on five benchmarks on contrastive learning, yielding satisfactory results without temperature tuning.