CAMP in the Odyssey: Provably Robust Reinforcement Learning with Certified Radius Maximization
作者: Derui Wang, Kristen Moore, Diksha Goel, Minjune Kim, Gang Li, Yang Li, Robin Doss, Minhui Xue, Bo Li, Seyit Camtepe, Liming Zhu
分类: cs.LG, cs.CR
发布日期: 2025-01-29 (更新: 2025-03-29)
备注: Accepted to USENIX Security Symposium 2025, Seattle, WA, USA. Source code is available at Github (https://github.com/NeuralSec/camp-robust-rl) and Zenodo (https://zenodo.org/records/14729675)
🔗 代码/项目: GITHUB
💡 一句话要点
提出CAMP:一种认证半径最大化的强化学习方法,提升对抗环境下的鲁棒性与回报。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 对抗鲁棒性 认证半径 策略平滑 策略模仿 鲁棒优化 深度学习
📋 核心要点
- 深度强化学习易受对抗攻击,现有方法依赖简单高斯增强,导致鲁棒性和回报的权衡不佳。
- CAMP通过最大化认证半径来提升策略,利用局部半径推导全局半径,并引入策略模仿稳定训练。
- 实验表明,CAMP在多种任务中显著改善了鲁棒性-回报权衡,认证预期回报最高可达基线的两倍。
📝 摘要(中文)
深度强化学习(DRL)因其在动态环境中的强大性能而被广泛应用于控制和决策任务。然而,DRL智能体容易受到噪声观测和对抗攻击的影响,DRL系统的对抗鲁棒性问题日益突出。最近的研究致力于解决这些鲁棒性问题,为DRL智能体在对抗环境中所能实现的回报建立严格的理论保证。在这些方法中,策略平滑已被证明是一种有效且可扩展的认证DRL智能体鲁棒性的方法。然而,现有的可认证鲁棒DRL依赖于使用简单高斯增强训练的策略,导致认证鲁棒性和认证回报之间的次优权衡。为了解决这个问题,我们引入了一种名为 exttt{C}ertified-r exttt{A}dius- exttt{M}aximizing exttt{P}olicy ( exttt{CAMP})训练的新范式。 exttt{CAMP}旨在增强DRL策略,在不影响可证明鲁棒性的前提下,实现更好的效用。通过利用全局认证半径可以从基于训练时统计的局部认证半径导出的洞察力, exttt{CAMP}构建了一个与局部认证半径相关的替代损失,并优化由该替代损失引导的策略。我们还引入了策略模仿作为一种稳定 exttt{CAMP}训练的新技术。实验结果表明, exttt{CAMP}显著提高了各种任务中的鲁棒性-回报权衡。根据结果,与基线相比, exttt{CAMP}可以实现高达两倍的认证预期回报。我们的代码可在https://github.com/NeuralSec/camp-robust-rl获取。
🔬 方法详解
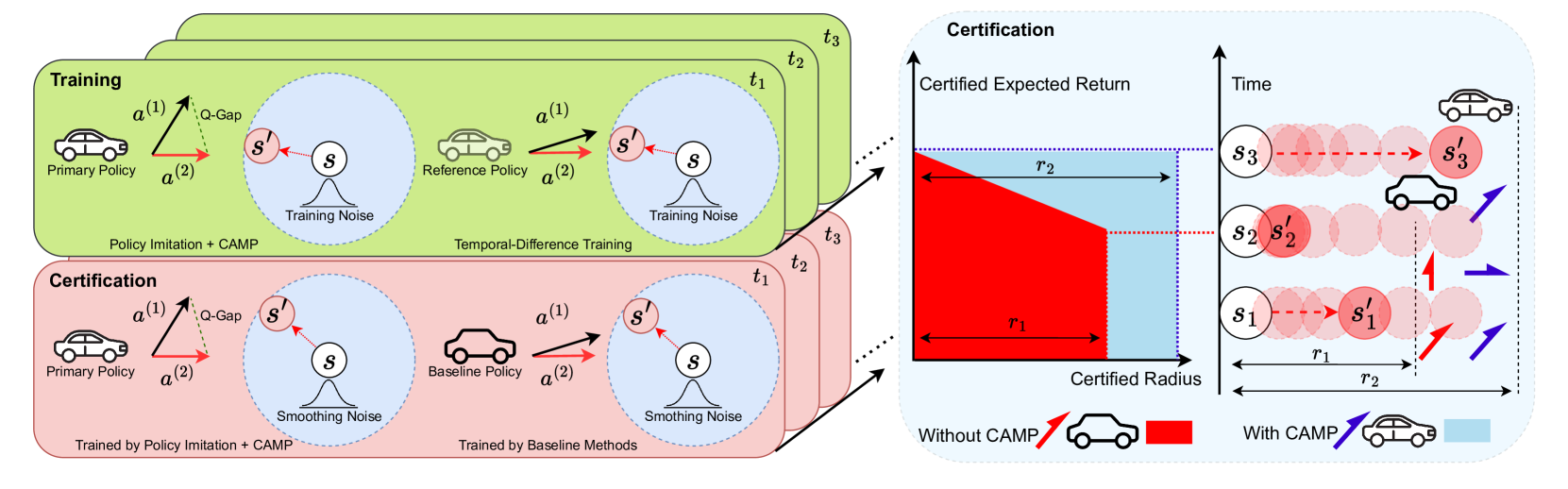
问题定义:现有深度强化学习方法在对抗环境中表现脆弱,容易受到噪声观测和对抗攻击的影响。为了提高鲁棒性,现有方法通常采用策略平滑技术,但依赖于简单的高斯增强,导致认证鲁棒性和认证回报之间存在次优的权衡。因此,需要一种能够在保证可证明鲁棒性的前提下,提升智能体性能的方法。
核心思路:CAMP的核心思路是通过最大化策略的认证半径来提高鲁棒性。该方法利用局部认证半径与全局认证半径之间的关系,构建一个与局部认证半径相关的替代损失函数,并通过优化该损失函数来引导策略的学习。此外,为了稳定训练过程,引入了策略模仿技术。
技术框架:CAMP训练框架主要包含以下几个阶段:1) 策略初始化:使用现有的强化学习算法训练一个初始策略。2) 局部认证半径计算:根据训练时统计信息,计算每个状态的局部认证半径。3) 替代损失函数构建:基于局部认证半径,构建一个替代损失函数,该损失函数旨在最大化策略的认证半径。4) 策略优化:使用梯度下降等优化算法,优化策略,使其能够最大化替代损失函数。5) 策略模仿:使用策略模仿技术,将优化后的策略向原始策略进行模仿,以稳定训练过程。
关键创新:CAMP的关键创新在于提出了认证半径最大化策略训练范式,并将其应用于强化学习中。与现有方法相比,CAMP能够更有效地利用训练数据,从而在保证可证明鲁棒性的前提下,提升智能体的性能。此外,策略模仿技术的引入也有效地稳定了训练过程。
关键设计:CAMP的关键设计包括:1) 局部认证半径的计算方法:论文中具体描述了如何根据训练时统计信息计算局部认证半径。2) 替代损失函数的形式:替代损失函数的设计旨在最大化策略的认证半径,同时考虑了策略的性能。3) 策略模仿的实现方式:论文中具体描述了如何使用策略模仿技术来稳定训练过程。具体的参数设置、损失函数、网络结构等技术细节可以在论文原文中找到。
🖼️ 关键图片

📊 实验亮点
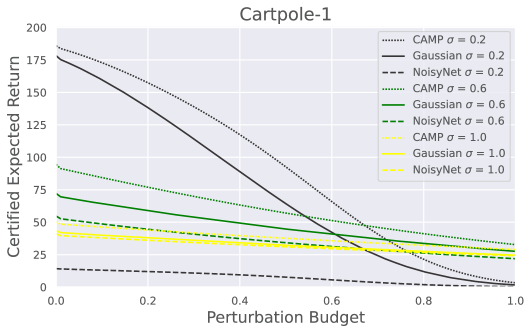
实验结果表明,CAMP在多个强化学习任务中显著提高了鲁棒性-回报权衡。与基线方法相比,CAMP能够实现高达两倍的认证预期回报。例如,在某个具体任务中,CAMP可以将认证预期回报从0.2提升到0.4,同时保持较高的鲁棒性。
🎯 应用场景
该研究成果可应用于对安全性要求较高的强化学习任务中,例如自动驾驶、机器人控制、金融交易等。通过提高智能体在对抗环境下的鲁棒性,可以降低系统风险,提高决策的可靠性。未来,该方法可以进一步扩展到更复杂的环境和任务中,并与其他鲁棒性增强技术相结合。
📄 摘要(原文)
Deep reinforcement learning (DRL) has gained widespread adoption in control and decision-making tasks due to its strong performance in dynamic environments. However, DRL agents are vulnerable to noisy observations and adversarial attacks, and concerns about the adversarial robustness of DRL systems have emerged. Recent efforts have focused on addressing these robustness issues by establishing rigorous theoretical guarantees for the returns achieved by DRL agents in adversarial settings. Among these approaches, policy smoothing has proven to be an effective and scalable method for certifying the robustness of DRL agents. Nevertheless, existing certifiably robust DRL relies on policies trained with simple Gaussian augmentations, resulting in a suboptimal trade-off between certified robustness and certified return. To address this issue, we introduce a novel paradigm dubbed \texttt{C}ertified-r\texttt{A}dius-\texttt{M}aximizing \texttt{P}olicy (\texttt{CAMP}) training. \texttt{CAMP} is designed to enhance DRL policies, achieving better utility without compromising provable robustness. By leveraging the insight that the global certified radius can be derived from local certified radii based on training-time statistics, \texttt{CAMP} formulates a surrogate loss related to the local certified radius and optimizes the policy guided by this surrogate loss. We also introduce \textit{policy imitation} as a novel technique to stabilize \texttt{CAMP} training. Experimental results demonstrate that \texttt{CAMP} significantly improves the robustness-return trade-off across various tasks. Based on the results, \texttt{CAMP} can achieve up to twice the certified expected return compared to that of baselines. Our code is available at https://github.com/NeuralSec/camp-robust-rl.