DFPE: A Diverse Fingerprint Ensemble for Enhancing LLM Performance
作者: Seffi Cohen, Niv Goldshlager, Nurit Cohen-Inger, Bracha Shapira, Lior Rokach
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-01-29 (更新: 2025-02-06)
💡 一句话要点
提出多样性指纹集成(DFPE)方法,提升LLM在复杂任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型集成 多样性指纹 自适应加权 自然语言理解
📋 核心要点
- 现有LLM在复杂领域表现不一,缺乏一致性,需要更鲁棒的集成方法。
- DFPE通过模型聚类、过滤和自适应加权,有效利用多个LLM的互补优势。
- 实验表明,DFPE在MMLU基准测试中显著提升了LLM的总体和学科级准确率。
📝 摘要(中文)
大型语言模型(LLM)在各种自然语言处理任务中表现出卓越的能力,但通常难以在多样化或复杂的领域中取得一致的优异表现。我们提出了一种新颖的集成方法——多样性指纹集成(DFPE),它利用多个LLM的互补优势来实现更稳健的性能。我们的方法包括:(1)基于响应“指纹”模式对模型进行聚类,(2)应用基于分位数的过滤机制来移除每个主题上表现不佳的模型,以及(3)根据剩余模型的主题级验证准确性为其分配自适应权重。在Massive Multitask Language Understanding (MMLU)基准上的实验表明,DFPE的总体准确率比最佳单一模型高3%,学科级准确率高5%。该方法提高了LLM的鲁棒性和泛化能力,并强调了模型选择、多样性保持和性能驱动的加权如何有效地解决具有挑战性的多方面语言理解任务。
🔬 方法详解
问题定义:现有大型语言模型在处理复杂和多样的自然语言理解任务时,往往表现出性能不一致的问题。单个模型难以在所有领域都达到最佳,且容易受到特定领域数据的影响,导致泛化能力不足。因此,如何有效地结合多个LLM的优势,提升整体性能和鲁棒性,是一个重要的挑战。
核心思路:DFPE的核心思路是利用不同LLM在不同领域的互补优势。通过分析模型的“指纹”(即在不同任务上的表现模式),将模型进行聚类,然后根据模型在特定任务上的验证集表现,动态地调整其权重。这种方法旨在保留模型的多样性,并赋予在特定任务上表现更好的模型更高的权重,从而实现更优的集成效果。
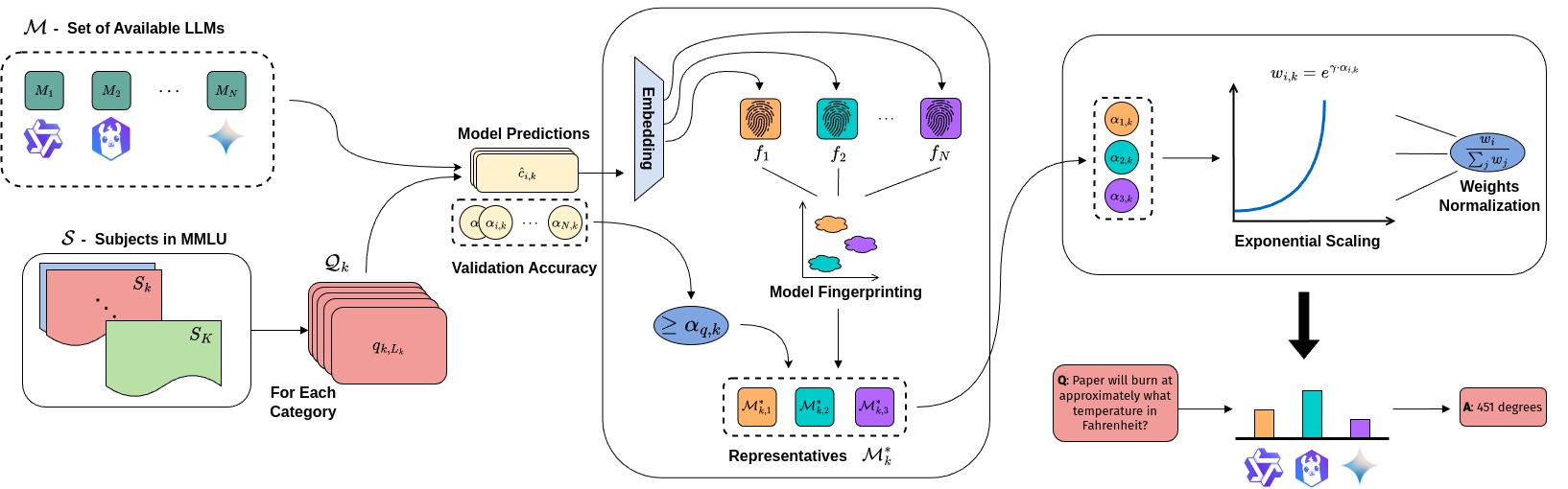
技术框架:DFPE的整体框架包含三个主要阶段:1) 模型聚类:基于模型在各个任务上的响应“指纹”进行聚类,旨在识别具有相似行为模式的模型。2) 模型过滤:应用基于分位数的过滤机制,针对每个任务,移除表现低于一定阈值的模型,以减少噪声和提高集成质量。3) 自适应加权:根据剩余模型在每个任务上的验证集准确率,为其分配自适应权重。表现更好的模型获得更高的权重,从而在集成过程中发挥更大的作用。
关键创新:DFPE的关键创新在于其多样性保持和性能驱动的加权策略。传统的集成方法可能侧重于选择最佳的单个模型或简单地平均多个模型的预测。而DFPE通过聚类和过滤,保留了模型的多样性,并通过自适应加权,动态地调整模型在不同任务上的贡献。这种方法能够更有效地利用多个模型的互补优势,从而提高整体性能。
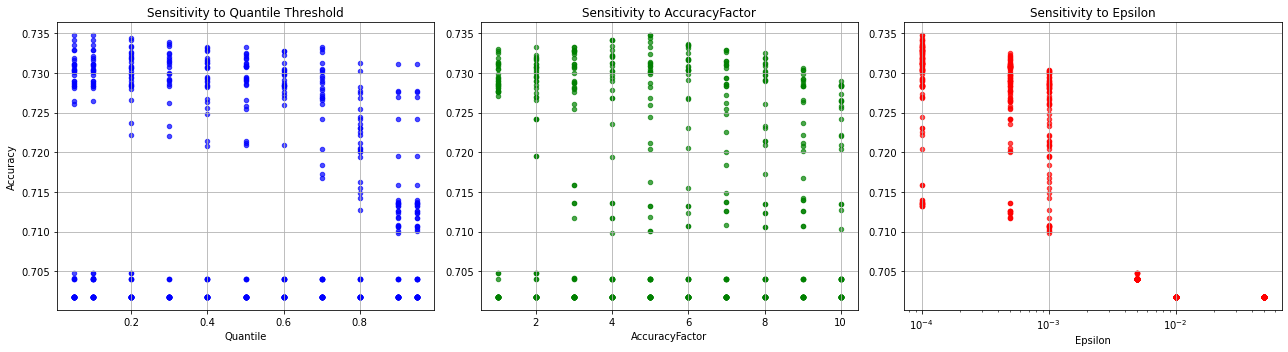
关键设计:在模型聚类阶段,可以使用各种聚类算法,例如K-means或层次聚类。关键在于选择合适的距离度量来衡量模型“指纹”之间的相似度。在模型过滤阶段,分位数阈值的选择会影响模型的数量和集成效果,需要根据具体任务进行调整。在自适应加权阶段,可以使用不同的加权函数,例如线性加权或指数加权。此外,验证集的划分和大小也会影响权重的准确性。
🖼️ 关键图片
📊 实验亮点
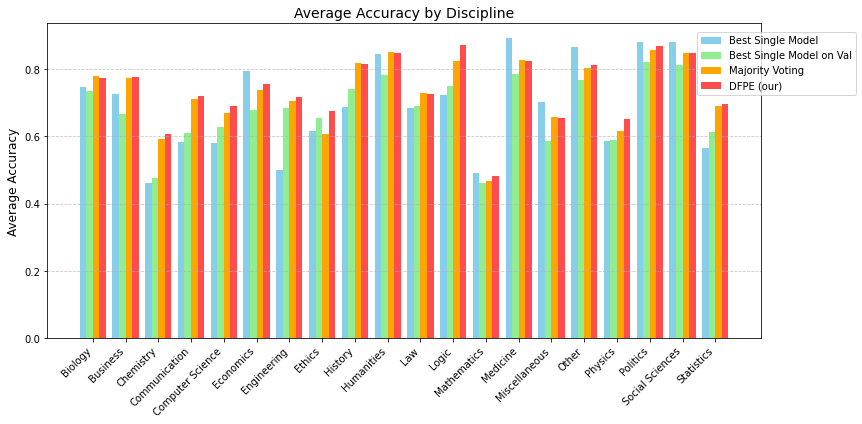
实验结果表明,DFPE在MMLU基准测试中取得了显著的性能提升。与最佳单一模型相比,DFPE的总体准确率提高了3%,学科级准确率提高了5%。这些结果表明,DFPE能够有效地利用多个LLM的互补优势,从而提高整体性能和鲁棒性。此外,实验还验证了DFPE在不同任务上的泛化能力。
🎯 应用场景
DFPE方法可广泛应用于需要处理复杂和多样化自然语言理解任务的场景,例如智能客服、机器翻译、信息检索和问答系统。该方法能够提升LLM在这些场景中的鲁棒性和泛化能力,从而提供更准确、更可靠的服务。未来,DFPE可以扩展到其他类型的模型集成,并与其他技术(如知识蒸馏和迁移学习)相结合,以进一步提升LLM的性能。
📄 摘要(原文)
Large Language Models (LLMs) have shown remarkable capabilities across various natural language processing tasks but often struggle to excel uniformly in diverse or complex domains. We propose a novel ensemble method - Diverse Fingerprint Ensemble (DFPE), which leverages the complementary strengths of multiple LLMs to achieve more robust performance. Our approach involves: (1) clustering models based on response "fingerprints" patterns, (2) applying a quantile-based filtering mechanism to remove underperforming models at a per-subject level, and (3) assigning adaptive weights to remaining models based on their subject-wise validation accuracy. In experiments on the Massive Multitask Language Understanding (MMLU) benchmark, DFPE outperforms the best single model by 3% overall accuracy and 5% in discipline-level accuracy. This method increases the robustness and generalization of LLMs and underscores how model selection, diversity preservation, and performance-driven weighting can effectively address challenging, multi-faceted language understanding tasks.