Optimizing Large Language Model Training Using FP4 Quantization
作者: Ruizhe Wang, Yeyun Gong, Xiao Liu, Guoshuai Zhao, Ziyue Yang, Baining Guo, Zhengjun Zha, Peng Cheng
分类: cs.LG, cs.CL
发布日期: 2025-01-28 (更新: 2025-05-23)
💡 一句话要点
首个LLM的FP4训练框架,通过创新量化方法实现精度与效率的平衡。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: FP4量化 大型语言模型 量化训练 低精度训练 可微量化 离群值处理 混合精度训练
📋 核心要点
- 现有LLM训练计算成本高昂,低比特量化训练面临量化误差大和表示能力有限的挑战。
- 提出基于FP4的LLM训练框架,通过可微量化估计器和离群值处理策略来提升精度和稳定性。
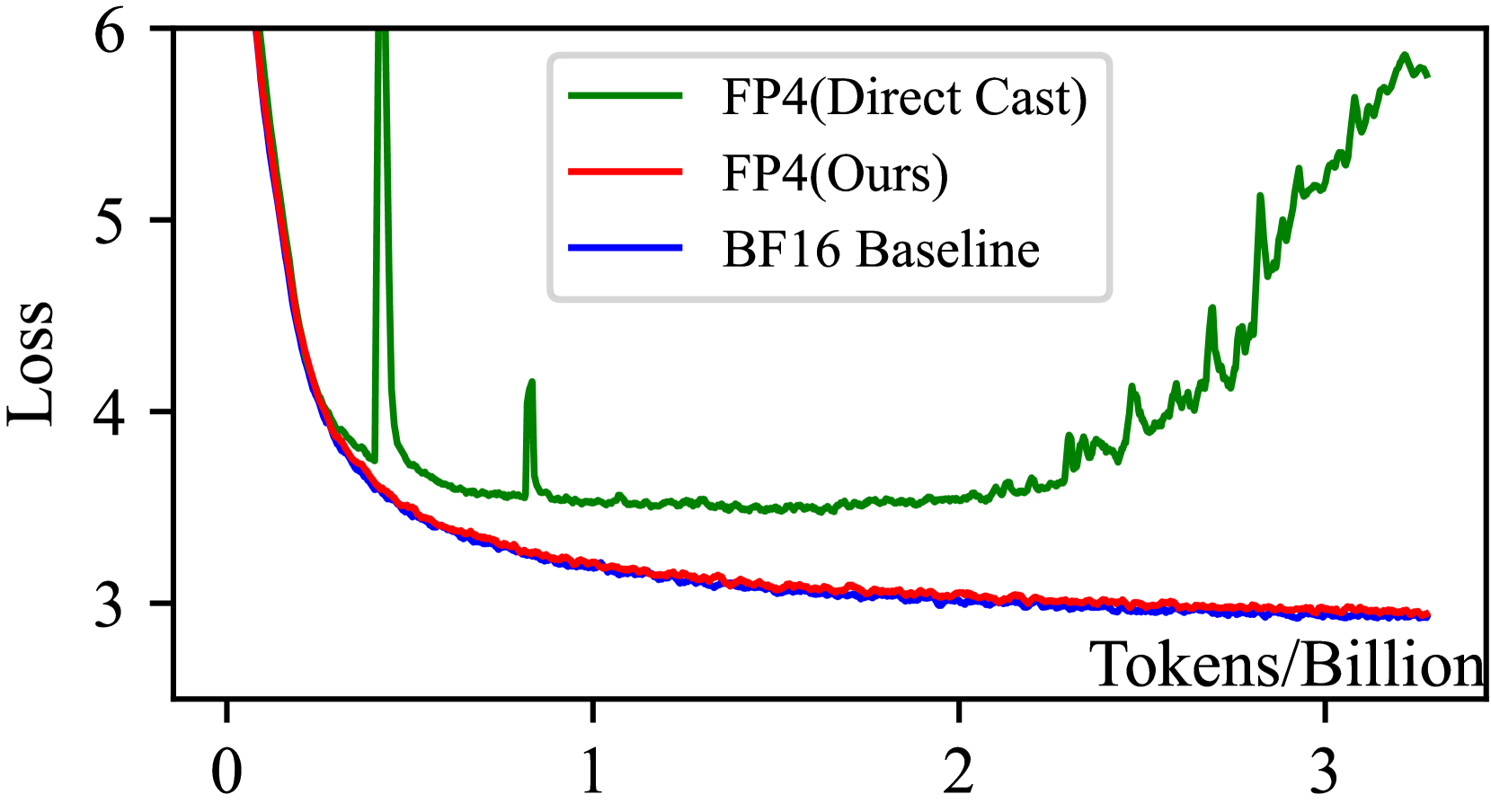
- 实验表明,该FP4框架在13B参数LLM上实现了与BF16/FP8相当的精度,且扩展性良好。
📝 摘要(中文)
训练大型语言模型(LLM)日益增长的计算需求需要更有效的方法。量化训练通过低比特算术运算来降低这些成本,提供了一个有希望的解决方案。虽然FP8精度已经证明了可行性,但由于显著的量化误差和有限的表示能力,利用FP4仍然是一个挑战。本研究提出了首个用于LLM的FP4训练框架,通过两项关键创新来解决这些挑战:用于精确权重更新的可微量化估计器,以及用于防止激活崩溃的离群值钳制和补偿策略。为了确保稳定性,该框架集成了混合精度训练方案和向量化量化。实验结果表明,我们的FP4框架实现了与BF16和FP8相当的精度,且退化最小,可有效扩展到在高达100B tokens上训练的13B参数LLM。随着支持FP4的下一代硬件的出现,我们的框架为高效的超低精度训练奠定了基础。
🔬 方法详解
问题定义:论文旨在解决在大型语言模型(LLM)训练中使用FP4量化时遇到的精度损失和训练不稳定性问题。现有的低精度训练方法,如FP8,虽然能降低计算成本,但更低精度的FP4由于其有限的表示范围和更大的量化误差,导致模型性能显著下降,难以有效训练。
核心思路:论文的核心思路是通过精细的量化控制和补偿机制,减轻FP4量化带来的负面影响。具体来说,通过可微量化估计器来更准确地更新权重,并采用离群值钳制和补偿策略来防止激活值崩溃,从而在保证训练稳定性的前提下,尽可能地利用FP4的计算效率。
技术框架:该FP4训练框架主要包含以下几个关键模块:1) 可微量化估计器:用于在反向传播过程中更精确地估计量化误差,从而更好地更新权重。2) 离群值钳制和补偿:用于限制激活值中的极端值,防止激活值崩溃,并对钳制造成的误差进行补偿。3) 混合精度训练:结合FP4和更高精度(如BF16)的参数,以提高训练的稳定性。4) 向量化量化:对权重向量进行整体量化,而非对单个元素进行量化,以减少量化误差。
关键创新:该论文最关键的创新在于提出了可微量化估计器和离群值钳制与补偿策略。可微量化估计器允许在反向传播过程中更准确地估计量化误差,从而优化权重更新。离群值钳制与补偿策略则有效地解决了FP4训练中常见的激活值崩溃问题,保证了训练的稳定性。这些创新使得FP4训练LLM成为可能。
关键设计:在可微量化估计器方面,论文可能采用了某种平滑的量化函数近似,使其可导。在离群值钳制方面,可能使用了动态阈值来确定需要钳制的激活值,并采用某种补偿机制(例如,通过统计信息来估计钳制造成的误差并进行校正)。混合精度训练方案中,可能将对精度要求更高的层或参数设置为BF16,而其余部分使用FP4。向量化量化可能采用了某种范数归一化方法,以减少量化误差。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该FP4训练框架在13B参数的LLM上实现了与BF16和FP8相当的精度,且性能退化最小。该框架成功扩展到在高达100B tokens上训练的模型,证明了其良好的扩展性和稳定性。这些结果表明,该FP4框架为高效的超低精度LLM训练奠定了坚实的基础。
🎯 应用场景
该研究成果可广泛应用于对计算资源敏感的场景,如移动设备、边缘计算和资源受限的数据中心。通过使用FP4量化训练LLM,可以在不显著降低模型性能的前提下,大幅降低训练和推理的计算成本,从而加速LLM在各个领域的部署和应用,例如智能助手、自然语言处理和机器翻译等。
📄 摘要(原文)
The growing computational demands of training large language models (LLMs) necessitate more efficient methods. Quantized training presents a promising solution by enabling low-bit arithmetic operations to reduce these costs. While FP8 precision has demonstrated feasibility, leveraging FP4 remains a challenge due to significant quantization errors and limited representational capacity. This work introduces the first FP4 training framework for LLMs, addressing these challenges with two key innovations: a differentiable quantization estimator for precise weight updates and an outlier clamping and compensation strategy to prevent activation collapse. To ensure stability, the framework integrates a mixed-precision training scheme and vector-wise quantization. Experimental results demonstrate that our FP4 framework achieves accuracy comparable to BF16 and FP8, with minimal degradation, scaling effectively to 13B-parameter LLMs trained on up to 100B tokens. With the emergence of next-generation hardware supporting FP4, our framework sets a foundation for efficient ultra-low precision training.