Mamba-Shedder: Post-Transformer Compression for Efficient Selective Structured State Space Models
作者: J. Pablo Muñoz, Jinjie Yuan, Nilesh Jain
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-01-28
备注: NAACL-25 - Main track
🔗 代码/项目: GITHUB
💡 一句话要点
Mamba-Shedder:用于高效选择性结构化状态空间模型的Transformer后压缩
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Mamba模型 模型压缩 序列建模 结构化剪枝 状态空间模型
📋 核心要点
- Transformer模型在序列建模中表现出色,但计算效率较低,限制了其在资源受限场景的应用。
- Mamba-Shedder通过移除Mamba模型中的冗余组件,在不同粒度上进行压缩,以降低计算开销。
- 实验表明,Mamba-Shedder在推理速度上实现了高达1.4倍的加速,同时保持了模型性能。
📝 摘要(中文)
大型预训练模型在序列建模中取得了显著成果。Transformer模块及其注意力机制是这些模型成功的关键驱动力。最近,诸如选择性结构化状态空间模型(SSM)等替代架构被提出,以解决Transformer的效率问题。本文探讨了基于SSM的模型的压缩,特别是Mamba及其混合模型。我们研究了这些模型对移除不同粒度级别的选定组件的敏感性,以减少模型大小和计算开销,从而在保持准确性的同时提高其效率。所提出的解决方案统称为Mamba-Shedder,在推理期间实现了高达1.4倍的加速,表明可以通过消除一些冗余来提高模型效率,而对整体模型性能的影响最小。代码可在https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning 获取。
🔬 方法详解
问题定义:论文旨在解决Mamba模型在实际应用中存在的计算效率问题。尽管Mamba相较于Transformer在某些方面有所改进,但其内部仍然存在冗余,导致模型体积较大,推理速度较慢。现有方法缺乏针对Mamba模型结构特点的有效压缩策略。
核心思路:论文的核心思路是通过分析Mamba模型各组件的重要性,选择性地移除对模型性能影响较小的部分,从而实现模型压缩和加速。这种“shedding”策略旨在消除冗余,提高计算效率,同时尽可能保持模型的准确性。
技术框架:Mamba-Shedder的整体框架包括以下几个主要步骤:1) 模型分析:对Mamba模型的各个组件进行敏感性分析,评估其对模型性能的影响。2) 组件选择:根据敏感性分析的结果,选择要移除的组件,例如某些线性层、激活函数或状态转移矩阵。3) 模型压缩:从模型中移除选定的组件,并对剩余部分进行微调,以恢复性能。4) 性能评估:评估压缩后的模型在推理速度和准确性方面的表现。
关键创新:Mamba-Shedder的关键创新在于其针对Mamba模型的选择性结构化压缩策略。与传统的模型剪枝方法不同,Mamba-Shedder更加关注模型结构的特点,通过移除特定的组件来实现压缩,而不是简单地移除权重。这种方法能够更好地保留模型的关键信息,从而在压缩的同时保持较高的准确性。
关键设计:论文中涉及的关键设计包括:1) 敏感性分析方法:用于评估不同组件对模型性能的影响。2) 组件选择策略:用于确定要移除的组件。3) 微调策略:用于恢复压缩后模型的性能。具体的参数设置和网络结构细节可能需要参考论文原文。
🖼️ 关键图片


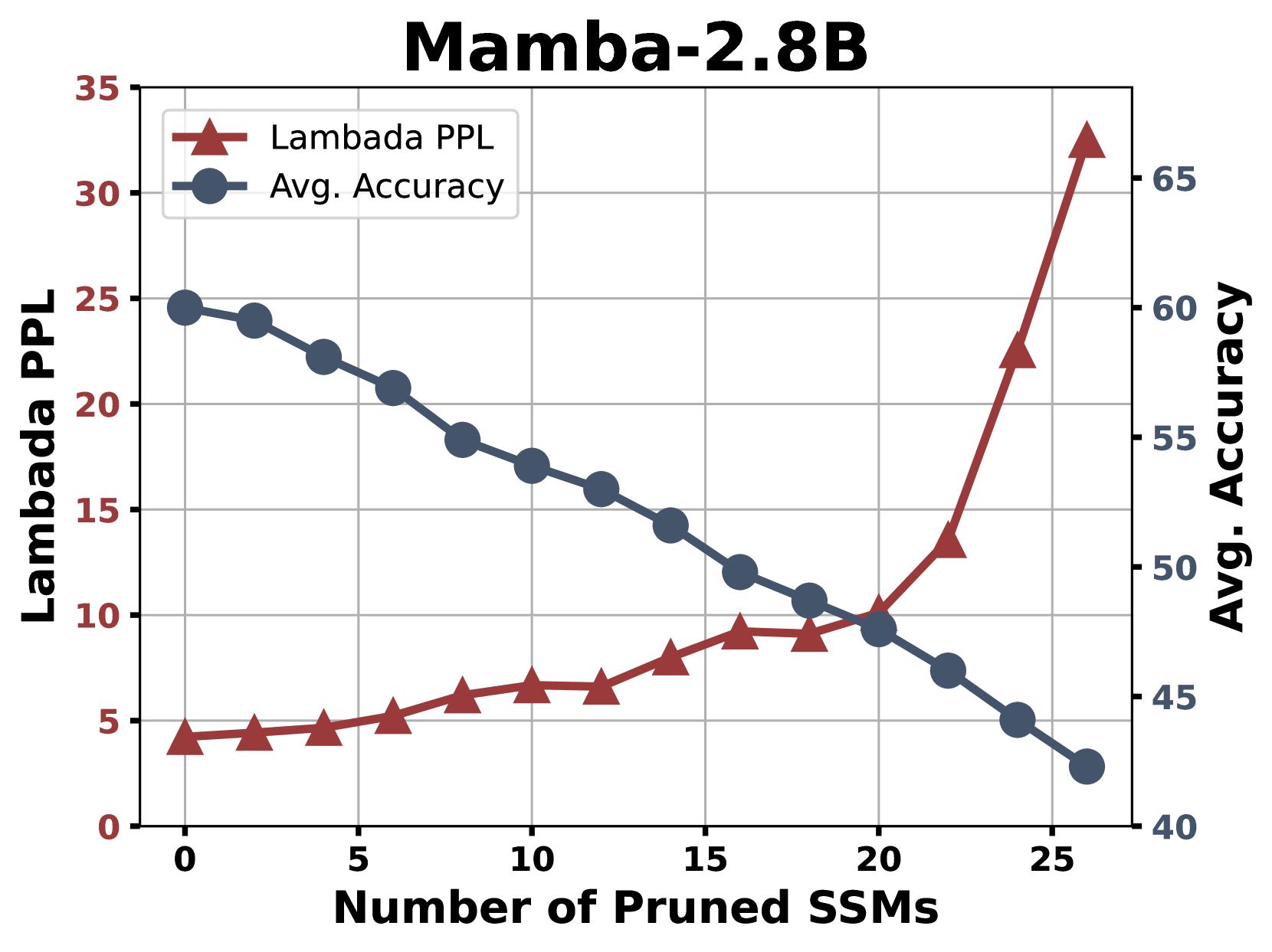
📊 实验亮点
Mamba-Shedder在实验中实现了显著的性能提升。具体而言,在推理速度上,Mamba-Shedder实现了高达1.4倍的加速,同时对模型准确性的影响很小。这意味着可以在不牺牲太多性能的情况下,显著提高Mamba模型的效率。这些结果表明Mamba-Shedder是一种有效的Mamba模型压缩方法。
🎯 应用场景
Mamba-Shedder可应用于各种序列建模任务,尤其是在资源受限的边缘设备或移动设备上。通过压缩Mamba模型,可以降低其计算开销和内存占用,使其能够在这些设备上高效运行。这对于语音识别、自然语言处理、时间序列预测等应用具有重要意义,能够提升用户体验并扩展应用范围。
📄 摘要(原文)
Large pre-trained models have achieved outstanding results in sequence modeling. The Transformer block and its attention mechanism have been the main drivers of the success of these models. Recently, alternative architectures, such as Selective Structured State Space Models (SSMs), have been proposed to address the inefficiencies of Transformers. This paper explores the compression of SSM-based models, particularly Mamba and its hybrids. We study the sensitivity of these models to the removal of selected components at different granularities to reduce the model size and computational overhead, thus improving their efficiency while maintaining accuracy. The proposed solutions, collectively referred to as Mamba-Shedder, achieve a speedup of up to 1.4x during inference, demonstrating that model efficiency can be improved by eliminating several redundancies with minimal impact on the overall model performance. The code is available at https://github.com/IntelLabs/Hardware-Aware-Automated-Machine-Learning.