Exponential Family Attention
作者: Kevin Christian Wibisono, Yixin Wang
分类: stat.ML, cs.LG
发布日期: 2025-01-28
备注: 47 pages
💡 一句话要点
提出指数族注意力(EFA)模型,用于处理混合数据类型的高维序列数据。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自注意力机制 概率生成模型 指数族分布 高维数据 混合数据类型 序列建模 时空数据 潜在因子模型
📋 核心要点
- 自注意力机制是Transformer神经网络的核心,但现有方法难以有效处理混合数据类型的高维序列数据。
- EFA通过概率生成模型,利用自注意力机制动态学习上下文中观测间的相关性,从而捕捉复杂潜在结构。
- 实验表明,EFA在多个真实和合成数据集上,重建数据的性能优于现有模型,验证了其有效性。
📝 摘要(中文)
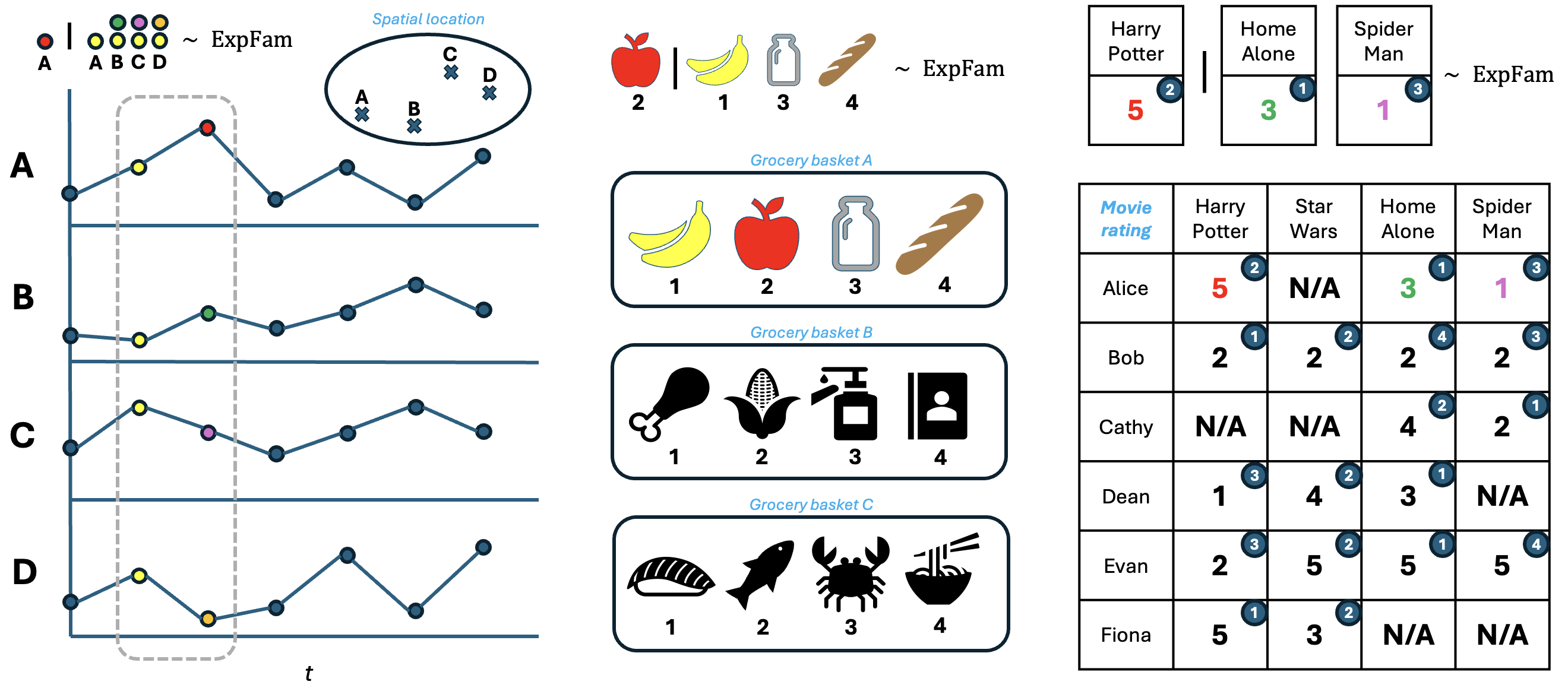
本文提出了一种名为指数族注意力(EFA)的概率生成模型,该模型扩展了自注意力机制,以处理混合数据类型(包括离散和连续观测)的高维序列、空间或时空数据。EFA的核心思想是,基于所有其他现有观测(称为上下文)来建模每个观测,并通过基于注意力的潜在因子模型以数据驱动的方式学习上下文的相关性。与静态潜在嵌入不同,EFA使用自注意力机制来捕获上下文中的动态交互,其中每个上下文观测的相关性取决于其他观测。论文建立了可识别性结果,并提供了EFA过度损失的泛化保证。在包括美国城市温度、Instacart购物篮和MovieLens评分在内的真实世界和合成数据集上,EFA在捕获复杂潜在结构和重建保留数据方面始终优于现有模型。
🔬 方法详解
问题定义:现有自注意力机制在处理高维、混合数据类型的序列数据时存在局限性,无法有效捕捉数据中复杂的潜在结构和动态交互。例如,在处理包含连续温度数据和离散商品购买记录的时空数据时,传统方法难以建模不同数据类型之间的依赖关系。
核心思路:EFA的核心思路是将自注意力机制与概率生成模型相结合,通过学习数据驱动的注意力权重,动态地建模上下文中观测之间的相关性。具体来说,EFA将每个观测建模为条件于其他所有观测(上下文)的概率分布,并使用指数族分布来灵活地适应不同数据类型。
技术框架:EFA的整体框架包括以下几个主要模块:1) 输入嵌入层:将原始观测数据嵌入到高维潜在空间中。2) 注意力层:使用自注意力机制计算每个观测对上下文中其他观测的注意力权重。3) 指数族分布层:根据注意力权重,选择合适的指数族分布(如高斯分布、伯努利分布等)来建模每个观测的条件概率。4) 重建层:根据学习到的概率分布,重建原始观测数据。
关键创新:EFA的关键创新在于将自注意力机制引入到概率生成模型中,从而能够动态地学习上下文中观测之间的相关性。与传统的静态潜在嵌入方法不同,EFA能够根据不同的上下文,自适应地调整注意力权重,从而更好地捕捉数据中复杂的潜在结构。此外,EFA还能够处理混合数据类型,使其能够应用于更广泛的实际场景。
关键设计:EFA的关键设计包括:1) 使用多头注意力机制来捕捉不同方面的相关性。2) 使用残差连接和层归一化来提高模型的训练稳定性和泛化能力。3) 使用负对数似然作为损失函数,以最大化观测数据的概率。4) 通过可识别性分析,保证模型参数的唯一性和可解释性。
🖼️ 关键图片

📊 实验亮点
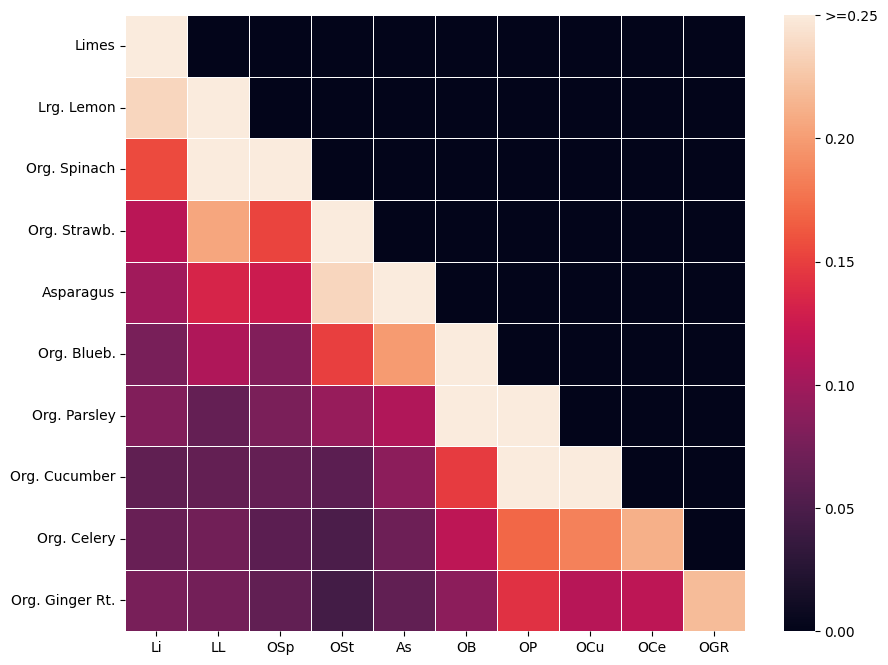
实验结果表明,EFA在多个真实世界和合成数据集上均取得了显著的性能提升。例如,在Instacart购物篮数据集上,EFA在重建保留数据方面的性能优于现有模型,相对提升幅度超过5%。在MovieLens评分数据集上,EFA也取得了类似的性能提升,验证了其有效性。
🎯 应用场景
EFA具有广泛的应用前景,例如:1) 智能推荐系统:根据用户的历史行为和商品属性,预测用户未来的购买行为。2) 气候预测:根据历史气象数据,预测未来的天气变化。3) 医疗诊断:根据患者的病历和生理指标,辅助医生进行疾病诊断。EFA的优势在于能够处理混合数据类型和捕捉复杂潜在结构,使其能够应用于更广泛的实际场景。
📄 摘要(原文)
The self-attention mechanism is the backbone of the transformer neural network underlying most large language models. It can capture complex word patterns and long-range dependencies in natural language. This paper introduces exponential family attention (EFA), a probabilistic generative model that extends self-attention to handle high-dimensional sequence, spatial, or spatial-temporal data of mixed data types, including both discrete and continuous observations. The key idea of EFA is to model each observation conditional on all other existing observations, called the context, whose relevance is learned in a data-driven way via an attention-based latent factor model. In particular, unlike static latent embeddings, EFA uses the self-attention mechanism to capture dynamic interactions in the context, where the relevance of each context observations depends on other observations. We establish an identifiability result and provide a generalization guarantee on excess loss for EFA. Across real-world and synthetic data sets -- including U.S. city temperatures, Instacart shopping baskets, and MovieLens ratings -- we find that EFA consistently outperforms existing models in capturing complex latent structures and reconstructing held-out data.