LLM Assisted Anomaly Detection Service for Site Reliability Engineers: Enhancing Cloud Infrastructure Resilience
作者: Nimesh Jha, Shuxin Lin, Srideepika Jayaraman, Kyle Frohling, Christodoulos Constantinides, Dhaval Patel
分类: cs.LG, cs.AI
发布日期: 2025-01-28
备注: Accepted at the AAAI-2025 Deployable AI Workshop
💡 一句话要点
提出基于LLM的异常检测服务,提升云基础设施的可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 异常检测 大型语言模型 云基础设施 站点可靠性工程 时间序列分析
📋 核心要点
- 现有云基础设施异常检测方法难以有效处理复杂数据流,且缺乏对组件故障模式的理解。
- 利用LLM理解云基础设施组件及其行为,结合多种算法实现高效的单变量和多变量时间序列异常检测。
- 该服务已在工业环境中成功应用,并在公共基准测试中表现出良好的性能,显著提升了SRE的效率。
📝 摘要(中文)
本文介绍了一种可扩展的异常检测服务,该服务具有通用的API,专为工业时间序列数据设计,旨在协助站点可靠性工程师(SRE)管理云基础设施。该服务能够高效地检测复杂数据流中的异常,支持主动识别和解决问题。此外,本文还提出了一种创新的云基础设施异常建模方法,利用大型语言模型(LLM)来理解关键组件、其故障模式和行为。该服务提供了一套用于检测单变量和多变量时间序列数据异常的算法,包括基于回归、基于混合模型和半监督方法。我们提供了关于该服务使用模式的见解,一年内有超过500名用户和20万次API调用。该服务已成功应用于各种工业环境,包括基于物联网的AI应用。我们还在公共异常基准上评估了我们的系统,以展示其有效性。通过利用该服务,SRE可以主动识别潜在问题,从而减少停机时间并缩短事件响应时间,最终提升整体客户体验。我们计划扩展该系统,使其包含时间序列基础模型,从而实现零样本异常检测能力。
🔬 方法详解
问题定义:现有云基础设施的异常检测方法通常难以处理复杂的时间序列数据,并且缺乏对底层系统组件及其相互作用的深入理解。这导致误报率高,难以有效定位和解决问题。现有的方法往往依赖于人工定义的规则或简单的统计模型,难以适应云环境的动态变化。
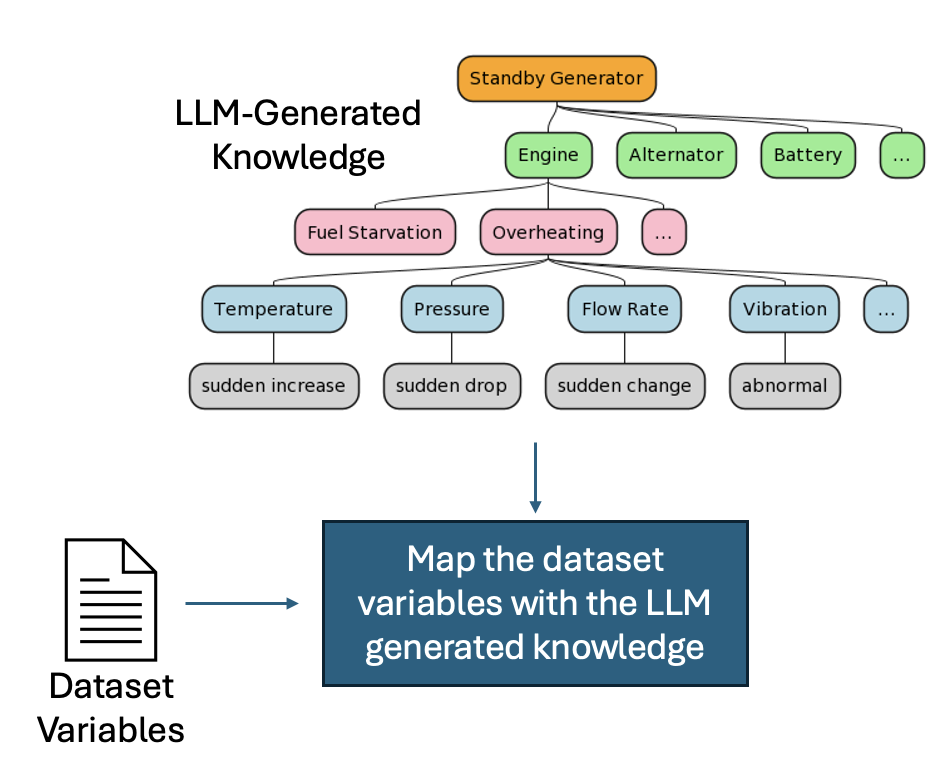
核心思路:本文的核心思路是利用大型语言模型(LLM)的强大语义理解能力,对云基础设施的组件、故障模式和行为进行建模。通过将LLM与传统的异常检测算法相结合,可以更准确地识别异常,并提供更丰富的上下文信息,帮助SRE快速定位和解决问题。
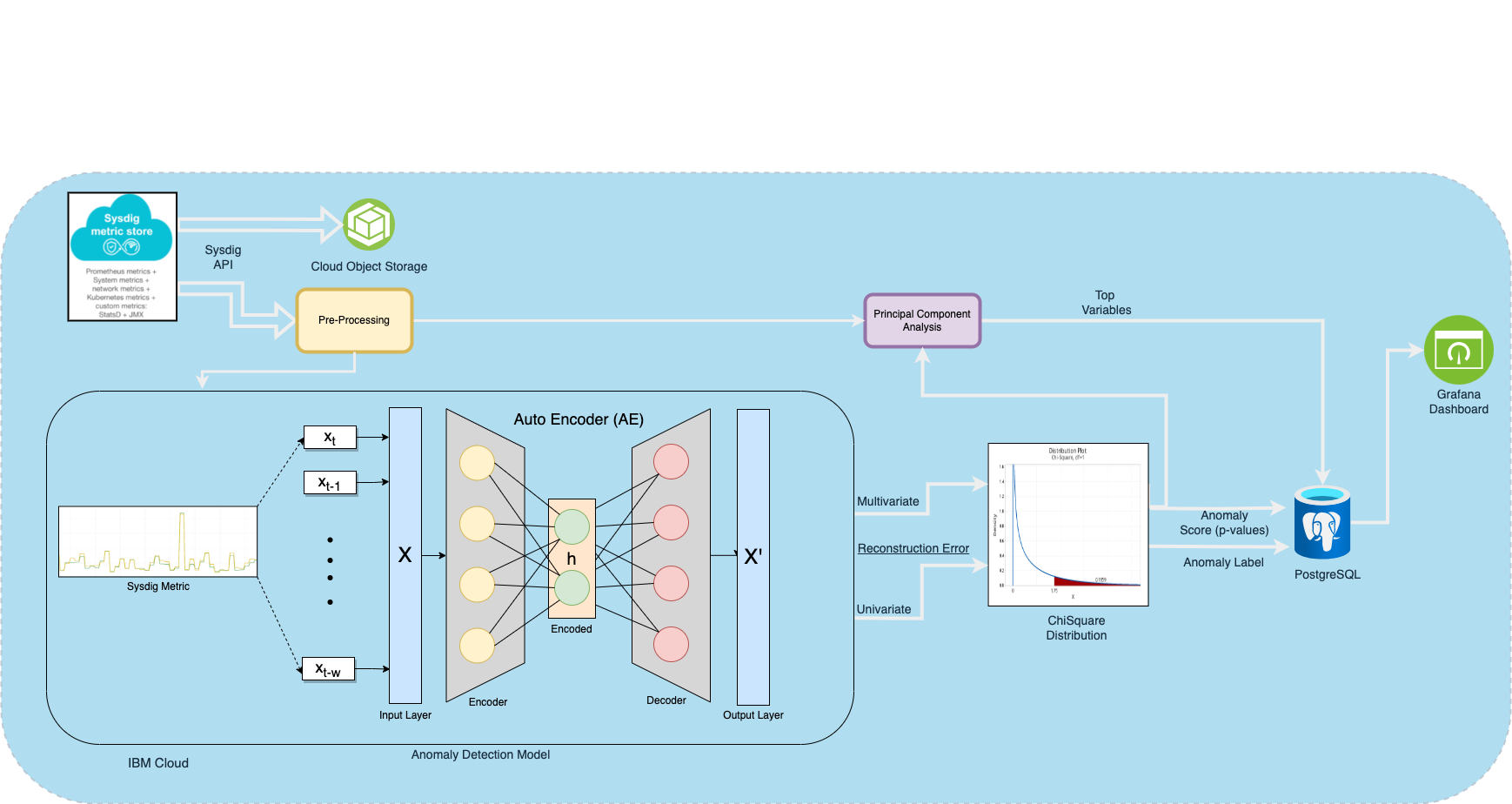
技术框架:该异常检测服务包含以下主要模块:1) 数据收集和预处理模块,负责收集来自各种云基础设施组件的时间序列数据,并进行清洗和转换;2) LLM建模模块,利用LLM对云基础设施的组件、故障模式和行为进行建模,生成知识图谱或嵌入表示;3) 异常检测算法模块,包含多种单变量和多变量时间序列异常检测算法,如基于回归、基于混合模型和半监督方法;4) 异常分析和告警模块,对检测到的异常进行分析,并生成告警信息,提供给SRE。
关键创新:该论文最重要的技术创新点在于将LLM引入到云基础设施的异常检测中。传统的异常检测方法主要依赖于统计模型或机器学习算法,缺乏对底层系统语义的理解。通过利用LLM,可以更准确地识别异常,并提供更丰富的上下文信息,从而提高异常检测的准确性和效率。此外,该服务还提供了一个通用的API,方便用户集成到现有的监控系统中。
关键设计:LLM建模模块的关键设计在于如何有效地利用LLM对云基础设施进行建模。一种方法是利用LLM生成知识图谱,其中节点表示云基础设施的组件,边表示组件之间的关系。另一种方法是利用LLM生成组件的嵌入表示,将组件映射到高维向量空间。异常检测算法模块的关键设计在于如何选择合适的算法,并对其进行优化,以适应云环境的特点。例如,可以利用半监督学习方法,从未标记的数据中学习正常行为的模式,从而提高异常检测的准确性。
🖼️ 关键图片

📊 实验亮点
该异常检测服务已在工业环境中成功应用,一年内有超过500名用户和20万次API调用。在公共异常基准测试中,该服务也表现出良好的性能,相较于传统方法,在准确率和召回率方面均有显著提升(具体数据未知)。通过利用该服务,SRE可以主动识别潜在问题,从而减少停机时间并缩短事件响应时间。
🎯 应用场景
该研究成果可广泛应用于云计算、物联网、工业自动化等领域,帮助运维人员及时发现和解决系统故障,降低停机时间,提升系统可靠性和用户体验。通过结合LLM的语义理解能力,可以实现更智能化的异常检测和根因分析,为企业提供更高效的IT运维解决方案。未来,该技术有望应用于更复杂的系统,例如智能交通、智慧城市等。
📄 摘要(原文)
This paper introduces a scalable Anomaly Detection Service with a generalizable API tailored for industrial time-series data, designed to assist Site Reliability Engineers (SREs) in managing cloud infrastructure. The service enables efficient anomaly detection in complex data streams, supporting proactive identification and resolution of issues. Furthermore, it presents an innovative approach to anomaly modeling in cloud infrastructure by utilizing Large Language Models (LLMs) to understand key components, their failure modes, and behaviors. A suite of algorithms for detecting anomalies is offered in univariate and multivariate time series data, including regression-based, mixture-model-based, and semi-supervised approaches. We provide insights into the usage patterns of the service, with over 500 users and 200,000 API calls in a year. The service has been successfully applied in various industrial settings, including IoT-based AI applications. We have also evaluated our system on public anomaly benchmarks to show its effectiveness. By leveraging it, SREs can proactively identify potential issues before they escalate, reducing downtime and improving response times to incidents, ultimately enhancing the overall customer experience. We plan to extend the system to include time series foundation models, enabling zero-shot anomaly detection capabilities.