Foundation for unbiased cross-validation of spatio-temporal models for species distribution modeling
作者: Diana Koldasbayeva, Alexey Zaytsev
分类: stat.AP, cs.LG
发布日期: 2025-01-27 (更新: 2025-12-19)
备注: Accepted manuscript. Published in Ecological Informatics (2025)
期刊: Ecological Informatics, Volume 92, Article 103521, 2025
DOI: 10.1016/j.ecoinf.2025.103521
💡 一句话要点
提出基于空间自相关的交叉验证方法,提升物种分布模型时空泛化能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 物种分布模型 空间自相关 交叉验证 时空迁移 模型评估
📋 核心要点
- 随机交叉验证忽略了物种分布数据中的空间自相关性,导致模型性能评估过于乐观,无法反映真实部署效果。
- 论文提出基于空间自相关的交叉验证方法,通过空间分块降低自相关的影响,更准确地评估模型泛化能力。
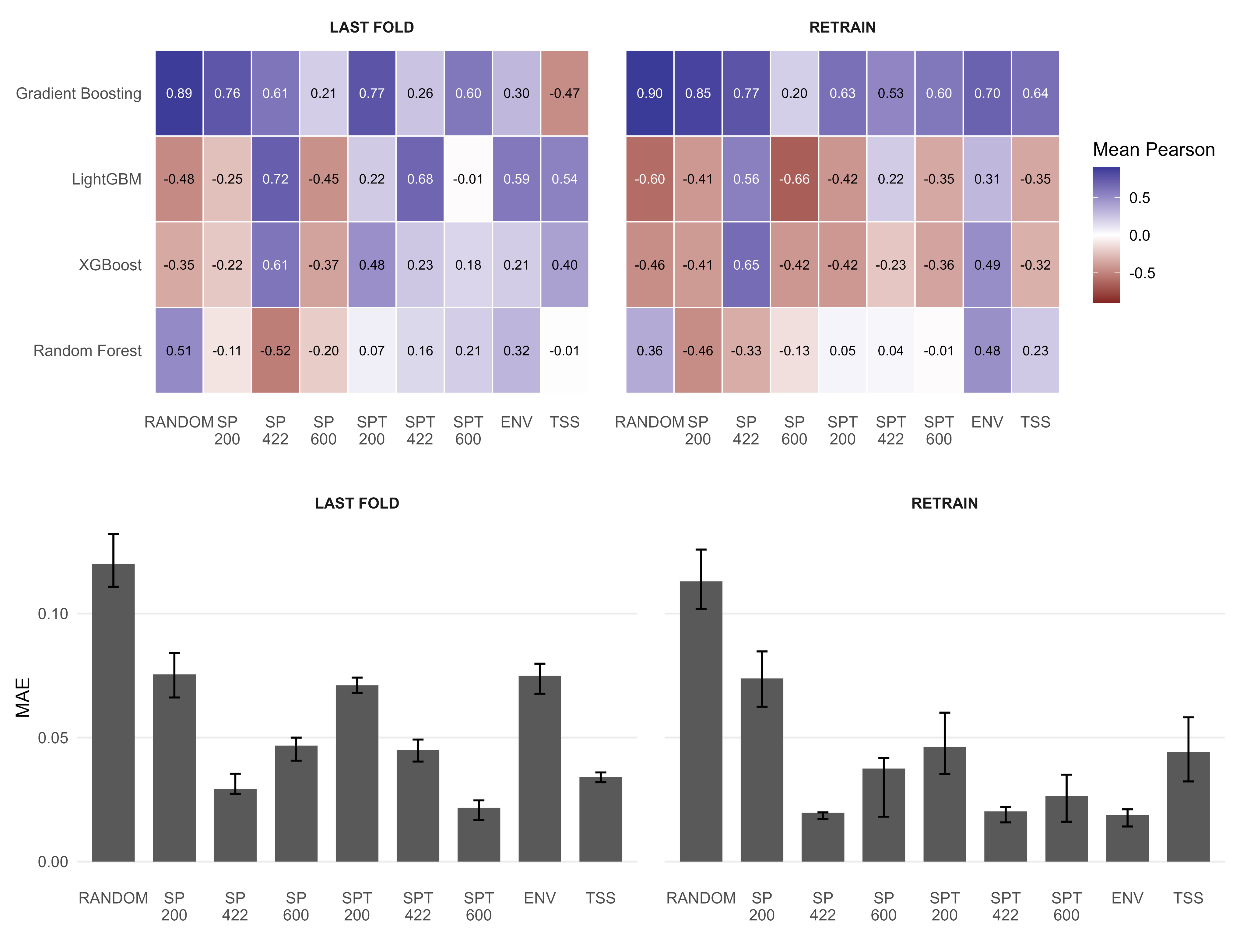
- 实验表明,空间分块交叉验证能显著降低AUC高估,并减少验证集与测试集之间的MAE差异,提升模型可靠性。
📝 摘要(中文)
物种分布模型(SDM)在实际部署场景下的预测性能评估需要谨慎处理数据中的空间和时间依赖性。交叉验证(CV)是模型评估的标准方法,但其设计严重影响性能估计的有效性。当SDM用于空间或时间迁移时,由于相邻观测值之间的空间自相关(SAC),随机CV可能导致过于乐观的结果。本文使用四种机器学习算法(GBM、XGBoost、LightGBM、Random Forest)在两种真实存在/缺失数据集(一种温带植物和一种溯河鱼)上,使用多种CV设计进行基准测试:随机、空间、时空、环境和前向链。评估了两种训练数据使用策略(LAST FOLD和RETRAIN),并在每个CV方案中执行超参数调整。使用AUC、MAE和相关性指标在独立的out-of-time测试集上评估模型性能。结果表明,基于SAC的阻塞、阻塞超参数调整和外部时间验证可以提高时空迁移的可靠性。
🔬 方法详解
问题定义:论文旨在解决物种分布模型(SDM)在时空迁移应用中,由于空间自相关性(SAC)导致随机交叉验证(CV)高估模型性能的问题。现有方法,即随机CV,无法有效评估模型在新的空间或时间环境下的泛化能力,导致模型选择和部署的偏差。
核心思路:核心思路是利用空间分块(spatial blocking)来降低训练数据中的空间自相关性,从而使交叉验证过程更接近于模型在实际部署中遇到的情况。通过将数据按照空间位置进行分组,确保验证集中的样本与训练集中的样本在空间上具有一定的独立性,从而避免模型过度拟合训练数据中的空间模式。
技术框架:整体框架包括以下几个主要步骤:1) 数据准备:收集物种分布数据和环境数据;2) 交叉验证设计:选择不同的交叉验证策略,包括随机CV、空间CV、时空CV、环境CV和前向链CV;3) 模型训练与超参数调优:使用四种机器学习算法(GBM、XGBoost、LightGBM、Random Forest)进行模型训练,并在每个CV方案中进行超参数调优;4) 模型评估:使用AUC、MAE和相关性指标在独立的out-of-time测试集上评估模型性能;5) 结果分析与比较:比较不同CV策略和训练策略下的模型性能,分析空间自相关性对模型评估的影响。
关键创新:最重要的技术创新点在于提出了基于空间自相关的交叉验证方法,该方法通过空间分块来降低训练数据中的空间自相关性,从而更准确地评估模型在时空迁移应用中的泛化能力。与传统的随机CV相比,该方法能够更好地反映模型在实际部署中遇到的情况,避免模型性能的高估。
关键设计:关键设计包括:1) 空间分块策略:根据经验SAC范围进行空间分块,确保验证集中的样本与训练集中的样本在空间上具有一定的独立性;2) 训练数据使用策略:评估LAST FOLD和RETRAIN两种训练数据使用策略,LAST FOLD只使用最后一个fold的数据进行训练,RETRAIN则使用所有fold的数据进行训练;3) 超参数调优:在每个CV方案中进行超参数调优,以确保模型在不同的CV策略下都能达到最佳性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,随机CV高估AUC高达0.16,MAE比空间分块方法高80%。在强空间自相关下,LAST FOLD策略验证集与测试集差异更小;在弱空间自相关下,RETRAIN策略测试集AUC更高。Boosted ensemble模型在空间结构化CV设计下表现最佳。推荐基于SAC感知的分块、分块超参数调优和外部时间验证的SDM工作流程。
🎯 应用场景
该研究成果可广泛应用于物种分布预测、生态环境保护、生物多样性管理等领域。通过更准确地评估模型在时空迁移应用中的泛化能力,可以为决策者提供更可靠的科学依据,从而制定更有效的保护策略和管理措施。此外,该方法也可推广到其他具有空间自相关性的数据分析问题中。
📄 摘要(原文)
Evaluating the predictive performance of species distribution models (SDMs) under realistic deployment scenarios requires careful handling of spatial and temporal dependencies in the data. Cross-validation (CV) is the standard approach for model evaluation, but its design strongly influences the validity of performance estimates. When SDMs are intended for spatial or temporal transfer, random CV can lead to overoptimistic results due to spatial autocorrelation (SAC) among neighboring observations. We benchmark four machine learning algorithms (GBM, XGBoost, LightGBM, Random Forest) on two real-world presence-absence datasets, a temperate plant and an anadromous fish, using multiple CV designs: random, spatial, spatio-temporal, environmental, and forward-chaining. Two training data usage strategies (LAST FOLD and RETRAIN) are evaluated, with hyperparameter tuning performed within each CV scheme. Model performance is assessed on independent out-of-time test sets using AUC, MAE, and correlation metrics. Random CV overestimates AUC by up to 0.16 and produces MAE values up to 80 percent higher than spatially blocked alternatives. Blocking at the empirical SAC range substantially reduces this bias. Training strategy affects evaluation outcomes: LAST FOLD yields smaller validation-test discrepancies under strong SAC, while RETRAIN achieves higher test AUC when SAC is weaker. Boosted ensemble models consistently perform best under spatially structured CV designs. We recommend a robust SDM workflow based on SAC-aware blocking, blocked hyperparameter tuning, and external temporal validation to improve reliability under spatial and temporal shifts.