Smoothed Embeddings for Robust Language Models
作者: Ryo Hase, Md Rafi Ur Rashid, Ashley Lewis, Jing Liu, Toshiaki Koike-Akino, Kieran Parsons, Ye Wang
分类: cs.LG, cs.AI, cs.CL, cs.CR, stat.ML
发布日期: 2025-01-27
备注: Presented in the Safe Generative AI Workshop at NeurIPS 2024
💡 一句话要点
提出RESTA防御方法,通过平滑嵌入向量增强语言模型对抗恶意攻击的鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 对抗攻击 鲁棒性 嵌入平滑 令牌聚合 安全性 可信赖AI
📋 核心要点
- 大型语言模型面临对抗攻击的威胁,现有对齐方法难以完全防御恶意输入。
- RESTA通过在嵌入层引入随机噪声并进行令牌聚合,提升模型对对抗样本的鲁棒性。
- 实验表明,RESTA在提升模型鲁棒性的同时,能够更好地保持模型的生成能力。
📝 摘要(中文)
为了实现可信赖的AI系统,提升大型语言模型(LLM)的安全性和可靠性至关重要。尽管对齐方法旨在抑制有害内容的生成,但LLM仍然容易受到对抗性输入的攻击,这些输入会破坏对齐并诱导产生有害输出,即“越狱”攻击。我们提出了一种名为随机嵌入平滑和令牌聚合(RESTA)的防御方法,该方法通过在生成每个输出令牌期间,向嵌入向量添加随机噪声并执行聚合,从而更好地保留语义信息。实验结果表明,与基线防御方法相比,我们的方法在鲁棒性与效用之间取得了更好的权衡。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)容易受到对抗性攻击的问题,即“越狱”攻击。现有的对齐方法虽然试图抑制有害内容的生成,但仍然无法完全防御精心设计的对抗性输入,这些输入能够绕过安全机制,诱导模型产生有害或不期望的输出。
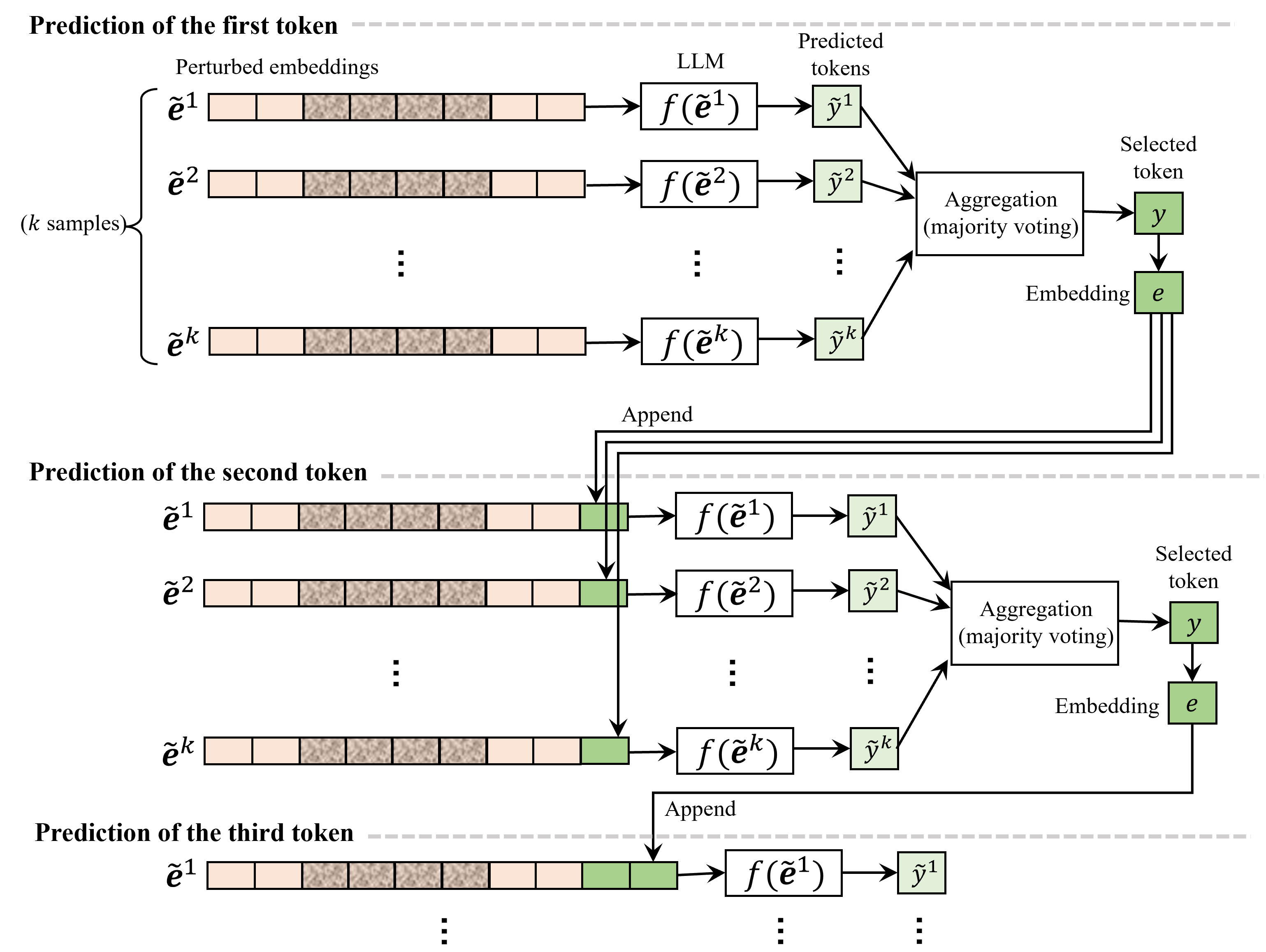
核心思路:论文的核心思路是通过在嵌入层引入随机噪声来平滑嵌入向量,并结合令牌聚合,从而增强模型对输入扰动的鲁棒性。这种方法旨在使模型对输入中的微小变化不敏感,从而降低对抗性攻击成功的可能性。通过聚合多个带有噪声的嵌入向量的输出来保留语义信息。
技术框架:RESTA防御方法主要包含两个关键步骤:1) 随机嵌入平滑:在输入令牌的嵌入向量中加入随机噪声。具体来说,对于每个输入令牌,其嵌入向量会加上一个服从特定分布(例如高斯分布)的随机向量。2) 令牌聚合:对于每个输出令牌的生成,模型会多次采样带有噪声的嵌入向量,并对每次采样的输出进行聚合(例如取平均)。最终的输出是所有采样输出的平均或加权平均。
关键创新:RESTA的关键创新在于将随机平滑技术应用于语言模型的嵌入层,并结合令牌聚合来保持模型的生成能力。与传统的对抗训练方法相比,RESTA不需要预先生成对抗样本,可以直接应用于现有的预训练语言模型,具有更好的通用性和易用性。
关键设计:RESTA的关键设计包括:1) 噪声的分布和方差:噪声的分布通常选择高斯分布,方差需要根据具体的模型和数据集进行调整,以达到最佳的鲁棒性和效用平衡。2) 聚合方法:可以使用简单的平均聚合,也可以使用加权平均聚合,权重可以根据每次采样的置信度或概率进行调整。3) 采样次数:采样次数越多,聚合后的输出越稳定,但计算成本也会相应增加。需要在计算资源和性能之间进行权衡。
🖼️ 关键图片
📊 实验亮点
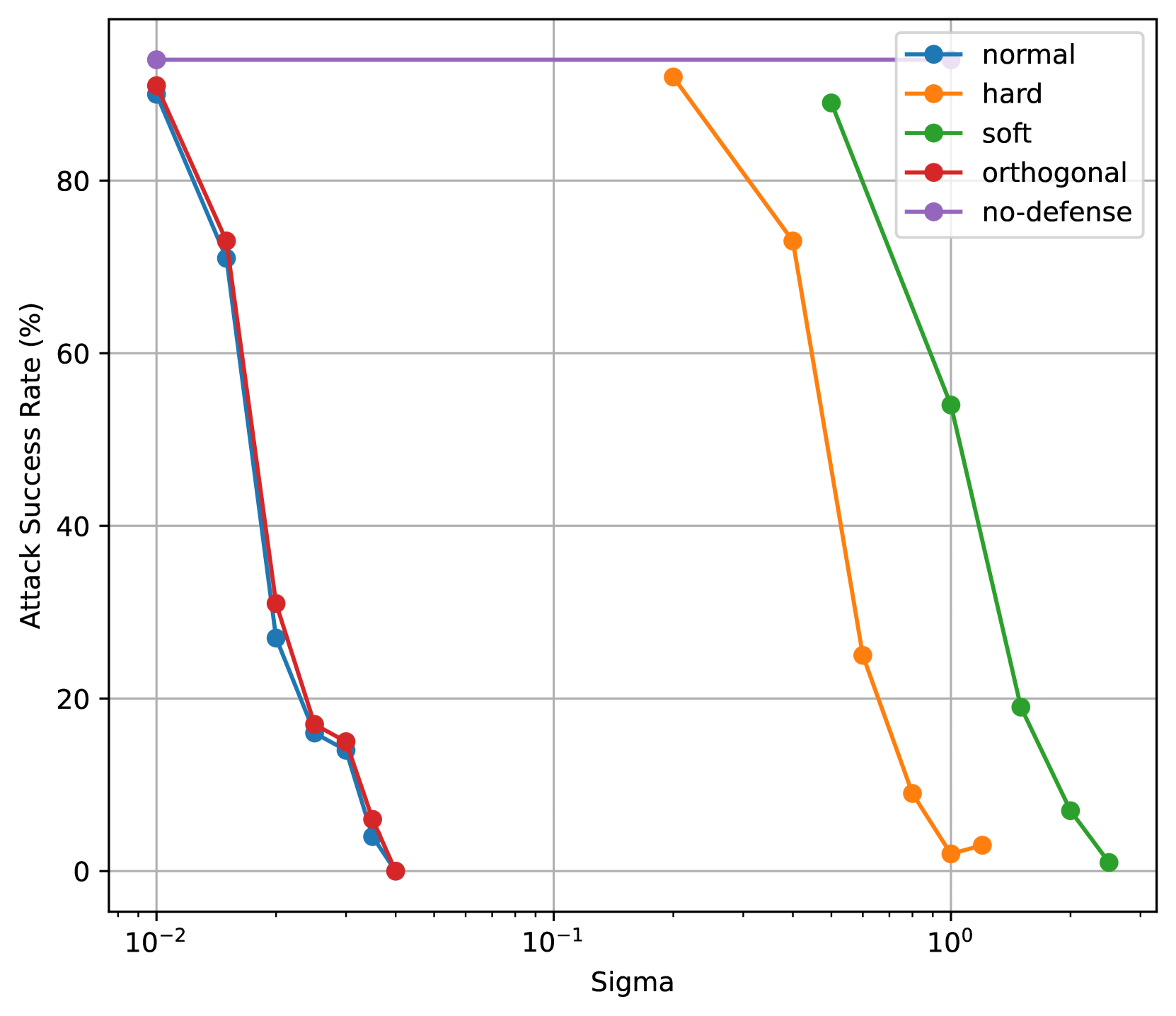
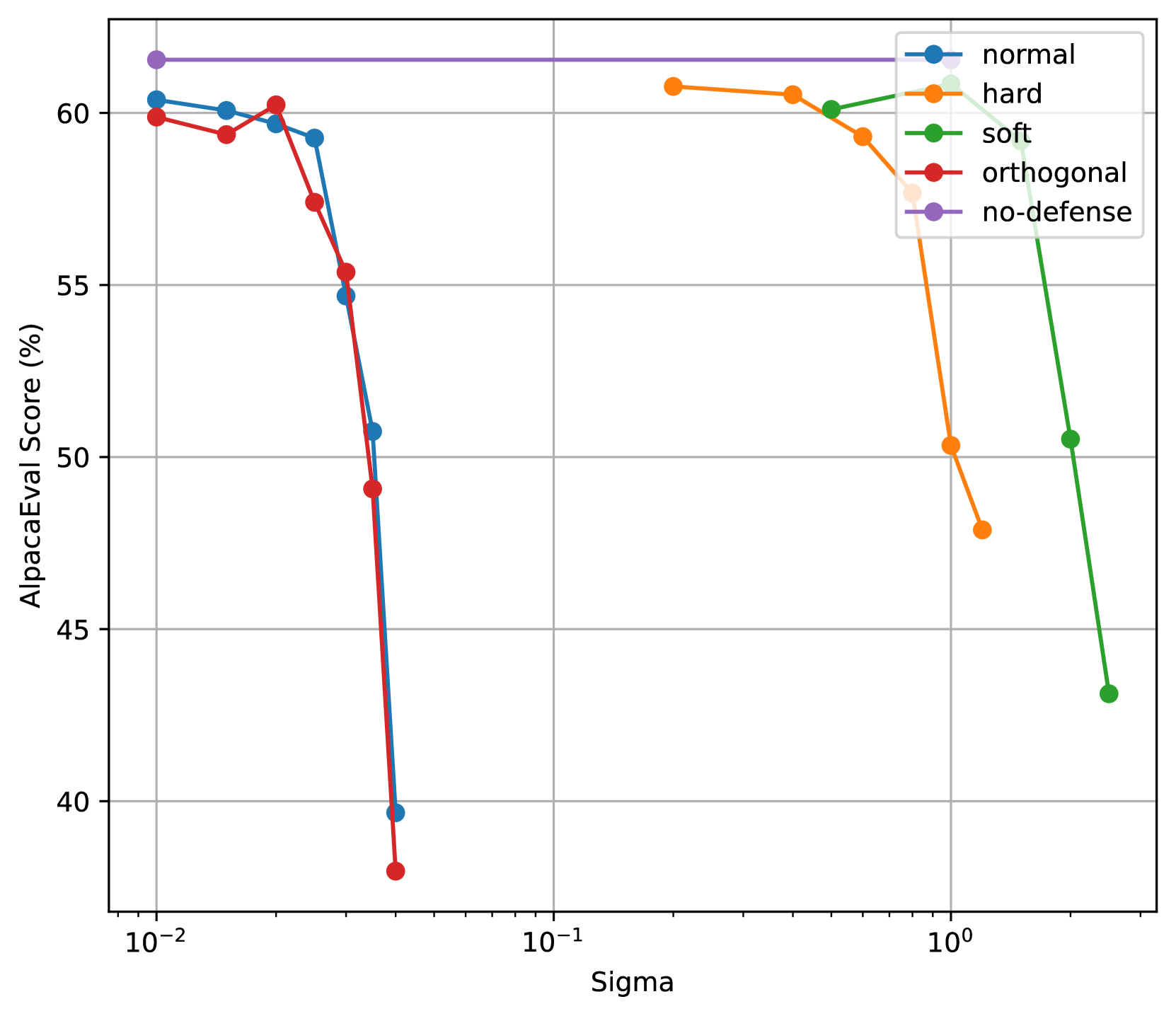
实验结果表明,RESTA防御方法在提升模型鲁棒性的同时,能够更好地保持模型的生成能力。与基线防御方法相比,RESTA在鲁棒性与效用之间取得了更好的权衡。具体而言,在相同的鲁棒性水平下,RESTA的生成质量更高;在相同的生成质量下,RESTA的鲁棒性更强。具体的性能数据和对比基线在论文中进行了详细展示。
🎯 应用场景
RESTA防御方法可以广泛应用于各种需要安全可靠的大型语言模型应用场景,例如智能客服、内容生成、代码生成等。通过提高模型对对抗性攻击的鲁棒性,可以有效防止模型被恶意利用,从而保障用户安全和系统稳定。该研究对于提升AI系统的可信赖性具有重要意义。
📄 摘要(原文)
Improving the safety and reliability of large language models (LLMs) is a crucial aspect of realizing trustworthy AI systems. Although alignment methods aim to suppress harmful content generation, LLMs are often still vulnerable to jailbreaking attacks that employ adversarial inputs that subvert alignment and induce harmful outputs. We propose the Randomized Embedding Smoothing and Token Aggregation (RESTA) defense, which adds random noise to the embedding vectors and performs aggregation during the generation of each output token, with the aim of better preserving semantic information. Our experiments demonstrate that our approach achieves superior robustness versus utility tradeoffs compared to the baseline defenses.