SIM: Surface-based fMRI Analysis for Inter-Subject Multimodal Decoding from Movie-Watching Experiments
作者: Simon Dahan, Gabriel Bénédict, Logan Z. J. Williams, Yourong Guo, Daniel Rueckert, Robert Leech, Emma C. Robinson
分类: cs.LG, cs.AI, eess.AS, eess.IV, q-bio.NC
发布日期: 2025-01-27
备注: 27 pages, accepted to ICLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于表面视觉Transformer的SIM模型,实现跨个体多模态脑解码,提升电影观看实验中的泛化能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脑解码 表面视觉Transformer 多模态对比学习 脑机接口 电影观看实验
📋 核心要点
- 现有脑解码模型泛化性差,难以跨个体和未见过的刺激进行解码,限制了其在脑机接口等领域的应用。
- 提出基于表面视觉Transformer的SIM模型,利用皮层表面的拓扑信息,结合多模态对比学习,学习通用的皮层功能动态。
- 在HCP电影观看数据集上验证,即使对于训练中未见过的个体和电影,也能准确解码观看的电影片段,并能捕捉个体大脑活动模式。
📝 摘要(中文)
当前用于脑解码和编码的AI框架通常在相同数据集内训练和测试模型,限制了其在脑机接口(BCI)或神经反馈中的应用。为了更好地模拟训练中未采样的刺激,需要汇集个体经验。个体间大脑皮层组织的高度变异性是模型泛化的主要障碍,使得跨参与者对齐或比较皮层信号变得困难。本文通过使用表面视觉Transformer来解决这个问题,该Transformer通过将皮层网络拓扑及其交互编码为表面上的移动图像,构建了皮层功能动态的通用模型。然后,结合三模态自监督对比学习(CLIP)对齐音频、视频和fMRI模态,从而能够从皮层活动模式中检索视觉和听觉刺激(反之亦然)。在来自人类连接组计划(HCP)的174名健康参与者参与的电影观看实验的7T任务fMRI数据上验证了该方法。结果表明,即使对于训练期间未见过的个体和电影,也可以仅从大脑活动中检测到个体正在观看的电影片段。对注意力图的进一步分析表明,该模型捕获了反映语义和视觉系统的个体大脑活动模式。这为未来个性化的脑功能模拟打开了大门。代码和预训练模型将在https://github.com/metrics-lab/sim上提供,用于训练的处理数据将应要求在https://gin.g-node.org/Sdahan30/sim上提供。
🔬 方法详解
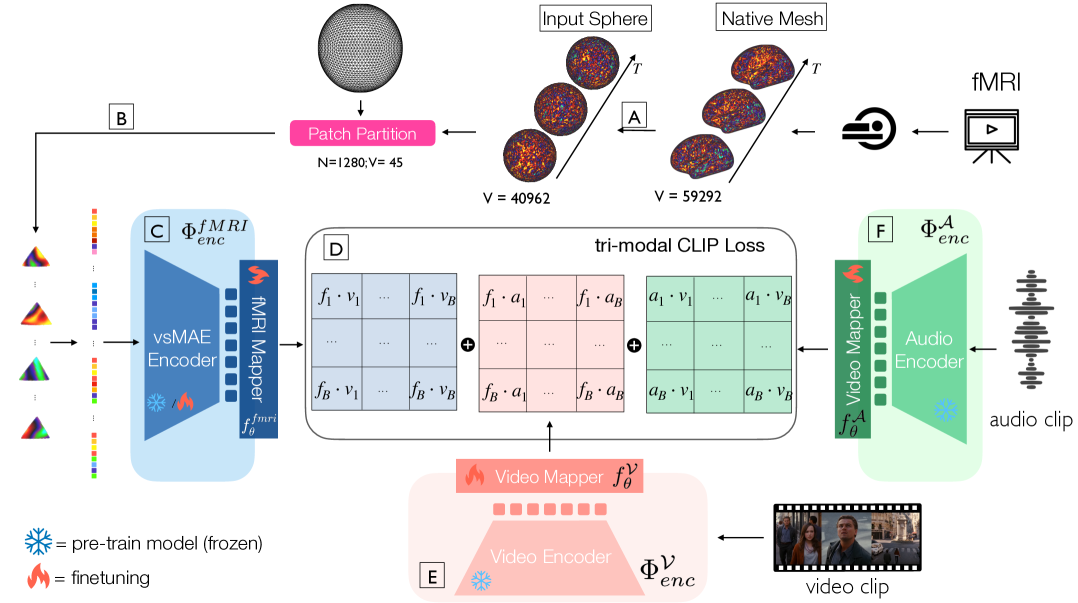
问题定义:论文旨在解决脑解码模型在跨个体和跨未见过的刺激时的泛化能力不足的问题。现有方法通常在相同数据集内训练和测试,难以适应个体间大脑皮层组织的高度变异性,导致模型无法有效推广到新的个体或刺激上。这限制了其在脑机接口和神经反馈等实际应用中的价值。
核心思路:论文的核心思路是利用大脑皮层表面的拓扑结构信息,构建一个通用的、个体无关的皮层功能动态模型。通过将皮层网络及其交互编码为表面上的移动图像,并结合多模态对比学习,模型能够学习到视觉、听觉和fMRI信号之间的对应关系,从而实现跨个体和跨刺激的脑解码。
技术框架:SIM模型的整体框架包括以下几个主要阶段:1) 皮层表面重建:利用fMRI数据重建个体的大脑皮层表面。2) 表面视觉Transformer:将皮层表面的活动模式编码为移动图像,并使用Transformer网络学习其动态特征。3) 多模态对比学习:使用CLIP框架,将视觉、听觉和fMRI信号对齐到一个共享的嵌入空间。4) 解码:利用学习到的嵌入空间,从fMRI信号中解码出对应的视觉或听觉刺激。
关键创新:论文最重要的技术创新点在于使用表面视觉Transformer来建模皮层功能动态。与传统的基于体素的分析方法不同,该方法能够更好地利用皮层表面的拓扑信息,从而提高模型的泛化能力。此外,结合多模态对比学习,使得模型能够学习到不同模态之间的对应关系,进一步提升了解码的准确性。
关键设计:在表面视觉Transformer中,论文使用了Transformer网络来学习皮层表面活动模式的动态特征。在多模态对比学习中,论文使用了CLIP框架,并针对fMRI信号进行了调整。具体的损失函数包括对比损失和交叉熵损失。在实验中,论文使用了7T任务fMRI数据,并对数据进行了预处理,包括运动校正、空间标准化和时间滤波等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SIM模型在HCP电影观看数据集上取得了显著的性能。即使对于训练中未见过的个体和电影,该模型也能准确解码观看的电影片段。此外,注意力图分析表明,该模型能够捕捉到反映语义和视觉系统的个体大脑活动模式。该模型在跨个体和跨刺激的脑解码任务中表现出强大的泛化能力。
🎯 应用场景
该研究成果可应用于脑机接口、神经反馈、认知神经科学等领域。例如,可以用于开发个性化的脑机接口系统,帮助患者恢复运动或交流能力。此外,还可以用于研究大脑如何处理视觉和听觉信息,以及不同个体之间大脑活动的差异。
📄 摘要(原文)
Current AI frameworks for brain decoding and encoding, typically train and test models within the same datasets. This limits their utility for brain computer interfaces (BCI) or neurofeedback, for which it would be useful to pool experiences across individuals to better simulate stimuli not sampled during training. A key obstacle to model generalisation is the degree of variability of inter-subject cortical organisation, which makes it difficult to align or compare cortical signals across participants. In this paper we address this through the use of surface vision transformers, which build a generalisable model of cortical functional dynamics, through encoding the topography of cortical networks and their interactions as a moving image across a surface. This is then combined with tri-modal self-supervised contrastive (CLIP) alignment of audio, video, and fMRI modalities to enable the retrieval of visual and auditory stimuli from patterns of cortical activity (and vice-versa). We validate our approach on 7T task-fMRI data from 174 healthy participants engaged in the movie-watching experiment from the Human Connectome Project (HCP). Results show that it is possible to detect which movie clips an individual is watching purely from their brain activity, even for individuals and movies not seen during training. Further analysis of attention maps reveals that our model captures individual patterns of brain activity that reflect semantic and visual systems. This opens the door to future personalised simulations of brain function. Code & pre-trained models will be made available at https://github.com/metrics-lab/sim, processed data for training will be available upon request at https://gin.g-node.org/Sdahan30/sim.