sDREAMER: Self-distilled Mixture-of-Modality-Experts Transformer for Automatic Sleep Staging
作者: Jingyuan Chen, Yuan Yao, Mie Anderson, Natalie Hauglund, Celia Kjaerby, Verena Untiet, Maiken Nedergaard, Jiebo Luo
分类: cs.LG, cs.AI
发布日期: 2025-01-27
DOI: 10.1109/ICDH60066.2023.00028
💡 一句话要点
提出sDREAMER模型,利用自蒸馏混合模态专家Transformer进行自动睡眠分期
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 睡眠分期 脑电图 肌电图 Transformer 多模态学习 自蒸馏 混合专家
📋 核心要点
- 现有睡眠分期方法在模态间信息交互不足,且缺乏统一模型处理不同输入源。
- sDREAMER模型采用混合模态专家(MoME)结构和自蒸馏训练,增强跨模态信息交互。
- 实验表明,sDREAMER在单通道和多通道睡眠分期任务上均优于现有Transformer模型。
📝 摘要(中文)
基于脑电图(EEG)和肌电图(EMG)信号的自动睡眠分期是睡眠相关研究的重要组成部分。现有的睡眠分期方法存在两个主要缺点:一是模态间的信息交互有限;二是缺乏能够处理不同输入源的统一模型。为了解决这些问题,我们提出了一种新的睡眠分期模型sDREAMER,它强调跨模态交互和每通道性能。具体来说,我们开发了一个混合模态专家(MoME)模型,包含EEG、EMG和混合信号三个通路,并采用部分共享权重。我们进一步提出了一种自蒸馏训练方案,以促进模态间的进一步信息交互。我们的模型使用多通道输入进行训练,并且可以对单通道或多通道输入进行分类。实验表明,我们的模型在多通道推理方面优于现有的基于Transformer的睡眠分期方法。对于单通道推理,我们的模型也优于使用单通道信号训练的基于Transformer的模型。
🔬 方法详解
问题定义:论文旨在解决自动睡眠分期中,现有方法模态间信息交互不足以及无法统一处理不同输入源的问题。现有方法的痛点在于未能充分利用EEG和EMG信号之间的互补信息,并且针对单通道和多通道输入需要训练不同的模型。
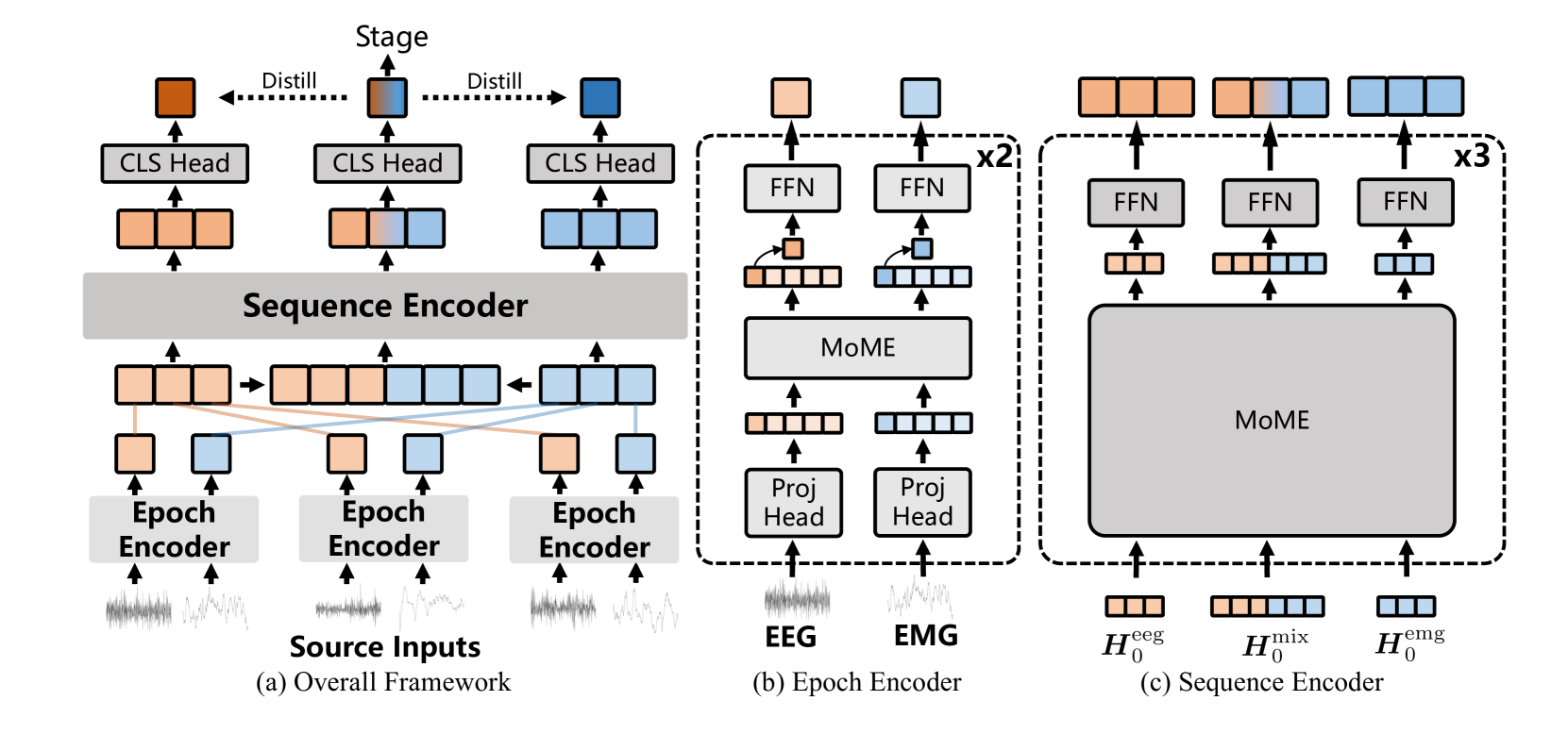
核心思路:论文的核心思路是设计一个能够有效融合不同模态信息,并且能够灵活处理单通道和多通道输入的统一模型。通过混合模态专家(MoME)结构,模型可以学习不同模态的特定表示,并通过自蒸馏训练促进模态间的信息交互。
技术框架:sDREAMER模型主要包含三个通路:EEG通路、EMG通路和混合信号通路。每个通路都包含Transformer编码器,用于提取输入信号的特征。MoME层用于融合不同通路的特征表示。模型采用自蒸馏训练方案,其中一个通路作为教师模型,指导其他通路的学习。最终,模型输出每个睡眠阶段的概率分布。
关键创新:论文的关键创新在于混合模态专家(MoME)结构和自蒸馏训练方案。MoME结构允许模型学习不同模态的特定表示,并促进模态间的信息融合。自蒸馏训练方案进一步增强了模态间的信息交互,提高了模型的泛化能力。与现有方法相比,sDREAMER能够更有效地利用多模态信息,并且能够灵活处理单通道和多通道输入。
关键设计:MoME层采用加权平均的方式融合不同通路的特征表示,权重由一个可学习的门控机制控制。自蒸馏训练采用KL散度作为损失函数,用于衡量教师模型和学生模型输出概率分布之间的差异。模型使用交叉熵损失函数进行睡眠分期任务的训练。Transformer编码器采用标准的多头注意力机制。
🖼️ 关键图片

📊 实验亮点
实验结果表明,sDREAMER模型在多通道睡眠分期任务上优于现有的基于Transformer的模型。在单通道睡眠分期任务上,sDREAMER也取得了显著的性能提升,超过了使用单通道信号训练的Transformer模型。这些结果验证了sDREAMER模型在跨模态信息融合和泛化能力方面的优势。
🎯 应用场景
该研究成果可应用于临床睡眠医学、可穿戴设备和远程健康监测等领域。通过自动睡眠分期,医生可以更高效地诊断睡眠障碍,患者可以通过可穿戴设备监测自身睡眠质量。该模型还可以用于开发个性化的睡眠干预方案,提高人们的睡眠健康水平。
📄 摘要(原文)
Automatic sleep staging based on electroencephalography (EEG) and electromyography (EMG) signals is an important aspect of sleep-related research. Current sleep staging methods suffer from two major drawbacks. First, there are limited information interactions between modalities in the existing methods. Second, current methods do not develop unified models that can handle different sources of input. To address these issues, we propose a novel sleep stage scoring model sDREAMER, which emphasizes cross-modality interaction and per-channel performance. Specifically, we develop a mixture-of-modality-expert (MoME) model with three pathways for EEG, EMG, and mixed signals with partially shared weights. We further propose a self-distillation training scheme for further information interaction across modalities. Our model is trained with multi-channel inputs and can make classifications on either single-channel or multi-channel inputs. Experiments demonstrate that our model outperforms the existing transformer-based sleep scoring methods for multi-channel inference. For single-channel inference, our model also outperforms the transformer-based models trained with single-channel signals.